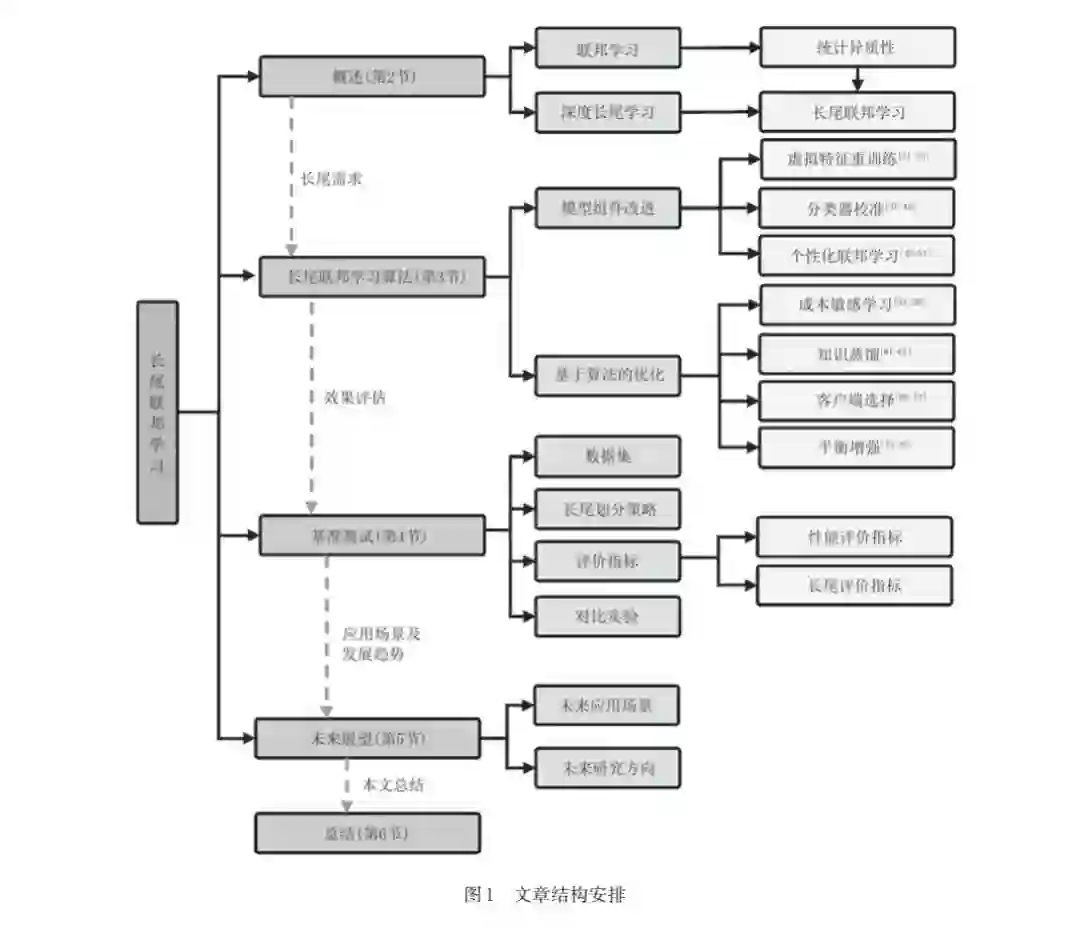
![]() 摘 要 联邦学习是一种基于分布式训练的机器学习技术,有效地解决了因联合建模而引发的用户间数据隐私泄 露问题,因此在多个领域得到了广泛应用。然而,在实际的联邦学习应用中,统计异质性与长尾分布的共存成为一 大挑战,严重影响了模型性能。因此,如何在保护数据隐私的前提下解决长尾问题,已成为当前的研究热点。本文 综述了联邦长尾学习的研究成果,首先简要阐述了联邦学习的架构,并介绍了统计异质性、长尾学习及联邦长尾学 习的核心概念与定义。接着,依据优化方法的差异,将联邦长尾学习的算法分为两大类:模型组件改进和基于算法 的优化,并深入分析了每种算法的实现细节及其优缺点。同时,为了更好地为不同任务提供参考,本文整合了一些 具有代表性的开源数据集、长尾划分策略、评价指标与对比实验。最后,针对未来的应用场景和研究方向,对联邦长 尾学习进行了展望。期望通过本文的深入研究,能为这类问题提供更全面的解决方案,进一步推动联邦长尾学习技 术在各个领域的广泛应用和发展。 关键词 联邦学习;长尾学习;联邦长尾学习;统计异质性;隐私保护;边缘智能
摘 要 联邦学习是一种基于分布式训练的机器学习技术,有效地解决了因联合建模而引发的用户间数据隐私泄 露问题,因此在多个领域得到了广泛应用。然而,在实际的联邦学习应用中,统计异质性与长尾分布的共存成为一 大挑战,严重影响了模型性能。因此,如何在保护数据隐私的前提下解决长尾问题,已成为当前的研究热点。本文 综述了联邦长尾学习的研究成果,首先简要阐述了联邦学习的架构,并介绍了统计异质性、长尾学习及联邦长尾学 习的核心概念与定义。接着,依据优化方法的差异,将联邦长尾学习的算法分为两大类:模型组件改进和基于算法 的优化,并深入分析了每种算法的实现细节及其优缺点。同时,为了更好地为不同任务提供参考,本文整合了一些 具有代表性的开源数据集、长尾划分策略、评价指标与对比实验。最后,针对未来的应用场景和研究方向,对联邦长 尾学习进行了展望。期望通过本文的深入研究,能为这类问题提供更全面的解决方案,进一步推动联邦长尾学习技 术在各个领域的广泛应用和发展。 关键词 联邦学习;长尾学习;联邦长尾学习;统计异质性;隐私保护;边缘智能
![]()