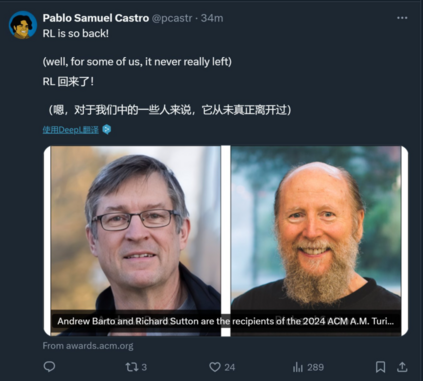
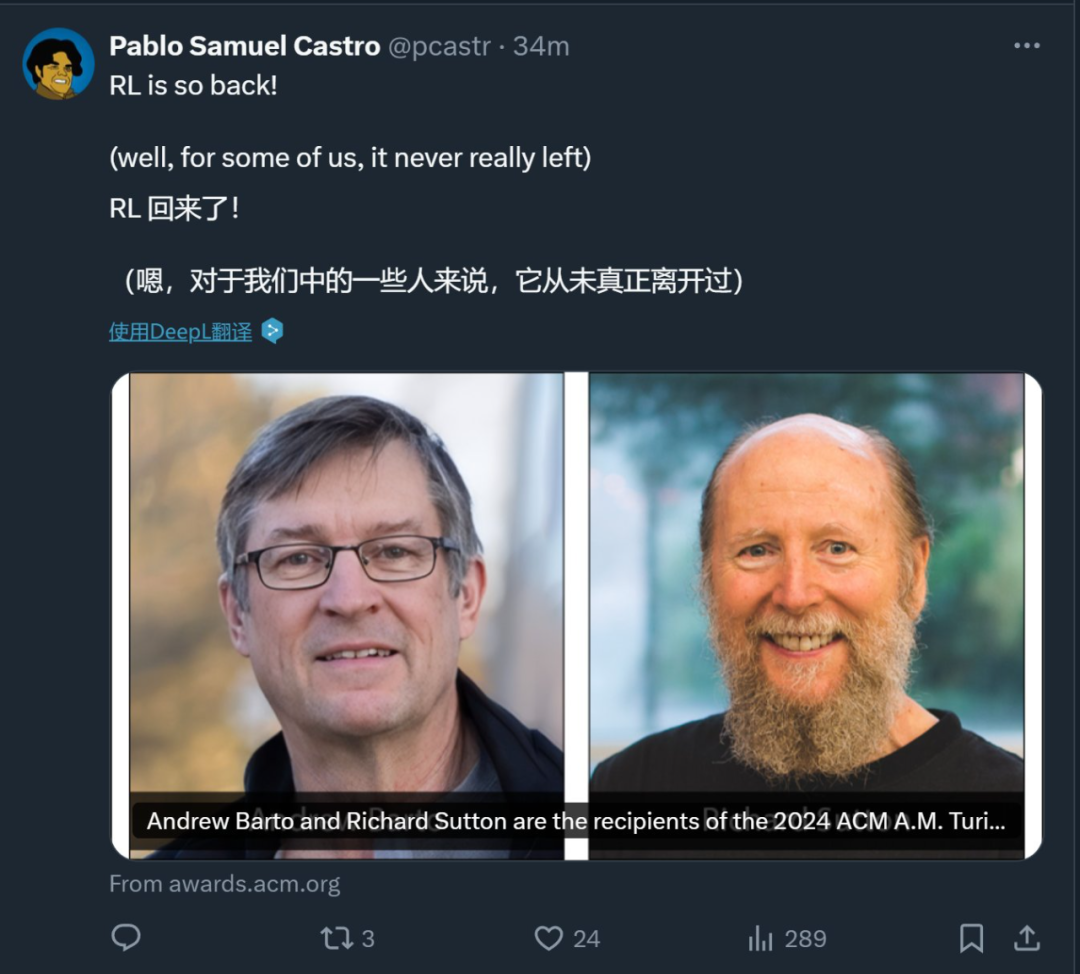
转载机器之心报道机器之心编辑部强化学习先驱 Andrew Barto 与 Richard Sutton 获得今年的 ACM 图灵奖。 人工智能学者,再次收获图灵奖!

刚刚,计算机学会(ACM)宣布了 2024 年的 ACM A.M. Turing Award(图灵奖)获得者:Andrew Barto 和 Richard Sutton。他们都是对强化学习做出奠基性贡献的著名研究者,Richard Sutton 更是有「强化学习之父」的美誉。Andrew Barto 则是 Sutton 的博士导师。自 1980 年代起,两位学者在一系列论文中提出了强化学习的主要思想,还构建了强化学习的数学基础,并开发了强化学习的重要算法。两人合著的《Reinforcement Learning: An Introduction》一直是强化学习领域最经典的教材之一。 Andrew Barto 是马萨诸塞大学阿默斯特分校信息与计算机科学荣休教授。Richard Sutton 是阿尔伯塔大学计算机科学教授,同时也是 Keen Technologies 的研究科学家。ACM 图灵奖常被称为「计算机领域的诺贝尔奖」,奖金为 100 万美元,由谷歌公司提供资金支持。该奖项以提出计算数学基础的英国数学家艾伦・图灵命名。强化学习,当今 AI 突破的原点
尽管 Barto 和 Sutton 的算法是数十年前开发的,但通过将强化学习与深度学习(由 2018 年图灵奖获得者 Bengio、Hinton、LeCun 开创)相结合,强化学习的实际应用已在过去十五年中取得重大进展。于是,深度强化学习技术应运而生。强化学习最著名的例子是 AlphaGo 计算机程序在 2016 年和 2017 年战胜了顶级人类围棋选手。另一个近期重大成就是聊天机器人 ChatGPT。ChatGPT 是一个经过两阶段训练得到的大型语言模型(LLM),其中第二阶段采用了一种名为「基于人类反馈的强化学习(RLHF)」的技术,其作用是可以让模型输出符合人类期望。强化学习在许多其他领域也取得了成功,其中之一是机器人运动技能学习。通过强化学习,机器手可以学会操作物体和解决物理问题;并且这种学习过程可在模拟中完成,然后再迁移到现实世界。强化学习适用的领域还包括网络拥堵控制、芯片设计、互联网广告、优化、全球供应链优化、改进聊天机器人的行为和推理能力,甚至改进矩阵乘法算法 —— 这是计算机科学中最古老的问题之一。最后,强化学习还反过来助力了神经科学的发展 —— 强化学习正是受到了该学科的启发。最近的研究,包括 Barto 的研究成果,已经表明 AI 领域开发的某些强化学习算法可为涉及人类大脑中多巴胺系统的广泛发现提供最佳解释。 「Barto 和 Sutton 的工作展示了将多学科方法应用于我们领域长期挑战的巨大潜力,」ACM 主席 Yannis Ioannidis 解释道。「从认知科学和心理学到神经科学的研究领域启发了强化学习的发展,这为 AI 领域的一些最重要进展奠定了基础,并让我们更深入地了解大脑如何工作。Barto 和 Sutton 的工作不是我们已经超越的垫脚石。强化学习继续发展,并为计算和许多其他学科的进一步发展提供了巨大潜力。用我们领域最负盛名的奖项表彰他们是非常恰当的。」「在 1947 年的一次演讲中,艾伦・图灵表示『我们想要的是一台能从经验中学习的机器』」,谷歌高级副总裁 Jeff Dean 指出。「Barto 和 Sutton 开创的强化学习直接回应了图灵的挑战。他们的工作是过去几十年 AI 进步的关键。他们开发的工具仍然是 AI 繁荣的中心支柱,带来了重大进步,吸引了大量年轻研究人员,并推动了数十亿美元的投资。RL 的影响将持续到未来。谷歌很荣幸赞助 ACM 图灵奖并表彰那些塑造了改善我们生活的技术的个人。」
个人背景****Andrew G. Barto
Andrew Barto 是马萨诸塞大学阿默斯特分校信息与计算机科学系荣誉退休教授。他于 1977 年作为博士后研究助理在马萨诸塞大学阿默斯特分校开始职业生涯,此后担任过多个职位,包括副教授、教授和系主任。Barto 在密歇根大学获得数学学士学位(优等),并在那里获得了计算机与通信科学的硕士和博士学位。 Barto 的荣誉包括马萨诸塞大学神经科学终身成就奖、IJCAI 研究卓越奖(Research Excellence Award)和 IEEE 神经网络学会先驱奖。他是电气和电子工程师协会(IEEE)会士和美国科学促进会(AAAS)会士。 Richard S. Sutton
Richard S. Sutton 是阿尔伯塔大学计算机科学教授、Keen Technologies(一家总部位于德克萨斯州达拉斯的通用人工智能公司)的研究科学家,以及阿尔伯塔机器智能研究所(Amii)的首席科学顾问。Sutton 从 2017 年到 2023 年是 DeepMind 的杰出研究科学家。在加入阿尔伯塔大学之前,他曾于 1998 年至 2002 年在新泽西州 Florham Park 的 AT&T 香农实验室人工智能部门担任首席技术人员。 Sutton 与 Andrew Barto 的合作始于 1978 年,当时在马萨诸塞大学阿默斯特分校,Barto 是 Sutton 的博士和博士后导师。Sutton 在斯坦福大学获得心理学学士学位,在马萨诸塞大学阿默斯特分校获得计算机与信息科学的硕士和博士学位。 Sutton 的荣誉包括获得 IJCAI 研究卓越奖、加拿大人工智能协会终身成就奖和马萨诸塞大学阿默斯特分校的杰出研究成就奖。Sutton 是伦敦皇家学会会士、人工智能促进协会会士和加拿大皇家学会会士。 参考链接https://x.com/TheOfficialACM/status/1897225672935735579https://amturing.acm.org/