

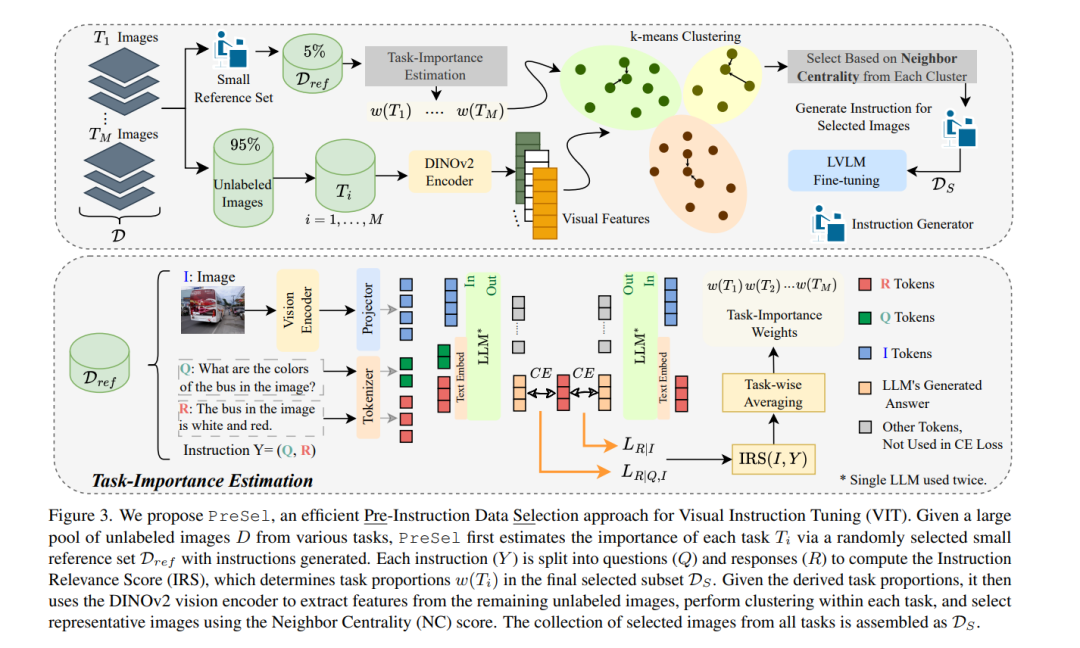
视觉指令调优(Visual Instruction Tuning, VIT) 对于大规模视觉-语言模型(Large Vision-Language Models, LVLMs)的训练需要依赖大量的图像-指令对数据集,这可能会带来高昂的成本。最近的研究尝试通过选择高质量图像-指令对的子集来减少VIT的运行时间,同时保持与全量训练相当的性能。然而,一个常被忽视的主要挑战是,从未标注图像生成指令用于VIT的成本非常高。大多数现有的VIT数据集严重依赖人工标注或付费服务(如GPT API),这限制了资源有限的用户为定制应用创建VIT数据集的能力。 为了解决这一问题,我们提出了预指令数据选择(Pre-Instruction Data Selection, PreSel),这是一种更实用的数据选择范式,直接选择最有益的无标注图像,并仅为选定的图像生成指令。PreSel首先估计VIT数据集中每个视觉任务的相对重要性,以确定任务级别的采样预算。然后,它在每个任务中对图像特征进行聚类,并根据预算选择最具代表性的图像。这种方法减少了VIT数据形成过程中指令生成和LVLM微调的计算开销。通过仅为15%的图像生成指令,PreSel在LLaVA-1.5和Vision-Flan数据集上实现了与全量VIT相当的性能。 项目页面链接:https://bardisafa.github.io/PreSel
成为VIP会员查看完整内容
相关内容
Arxiv
37+阅读 · 2023年4月19日
Arxiv
200+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日
相关VIP内容
相关资讯
相关论文
Arxiv
37+阅读 · 2023年4月19日
Arxiv
200+阅读 · 2023年4月7日
Arxiv
20+阅读 · 2023年3月21日