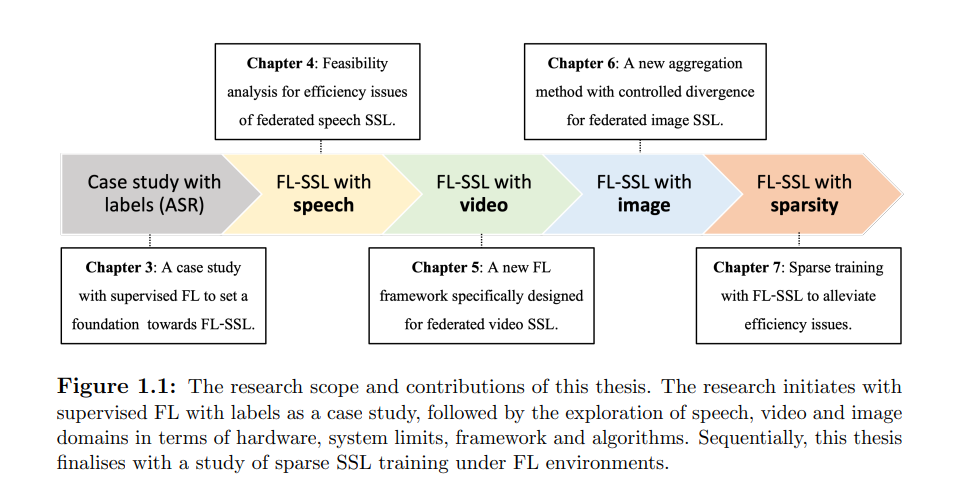
联邦学习(Federated Learning,FL)因其在不损害用户数据隐私的情况下促进大规模数据集协同学习的独特能力,已受到研究界和工业界的广泛关注。然而,目前的FL实践主要集中于监督学习任务,要求数据与高质量的领域特定标签同时存在。这一前提限制了FL在许多现实世界应用中的实施,因为在边缘设备上获取此类标签的途径有限。自监督学习(Self-Supervised Learning,SSL)能够从未标注数据中获取表示,这些表示可以随后用于解决各种下游任务。将SSL与FL结合,不仅在隐私保护训练方面具有显著优势,还包括强大的分布式表示学习、增强的可扩展性以及对噪声数据的抗扰性。尽管如此,在FL背景下的SSL研究仍然稀缺。本论文旨在弥补这一研究空白,通过阐明基础挑战并提出潜在解决方案,推动在FL环境中训练SSL模型的发展,特别是在语音、视频和图像领域。首先,我们系统地调查了在FL背景下实施语音SSL的可行性和复杂性,涉及硬件限制和算法方面,并为使用短输入序列训练的效率问题提供了初步解决方案。其次,我们深入探讨了视频-SSL在FL中的未开垦领域,并提出了一种新的FL框架,在聚合过程中结合了随机加权平均和部分权重更新,在下游任务上实现了新的最先进性能。第三,我们研究了图像联邦SSL中客户偏差引发的模型分歧问题。我们引入了一种新的聚合方案,旨在通过利用角度分歧作为权重系数在层级别加权客户模型,来减轻这一问题。最后,我们重新审视了FL-SSL中的效率挑战,并在联邦SSL模型训练中引入了稀疏化,以加速此类模型在FL边缘设备上的部署。总的来说,本论文的原创贡献在于解决将SSL模型训练整合到FL环境中的任务,涵盖三个广泛领域(语音、视频和图像)。本工作为在本地边缘设备上实现SSL训练奠定了基础,适用于广泛的现实世界应用。https://www.repository.cam.ac.uk/items/088cfd84-7a88-4a16-803f-94774169581f