讲座题目
大规模序贯实验的基础:Foundations of large-scale sequential experimentation
讲座简介
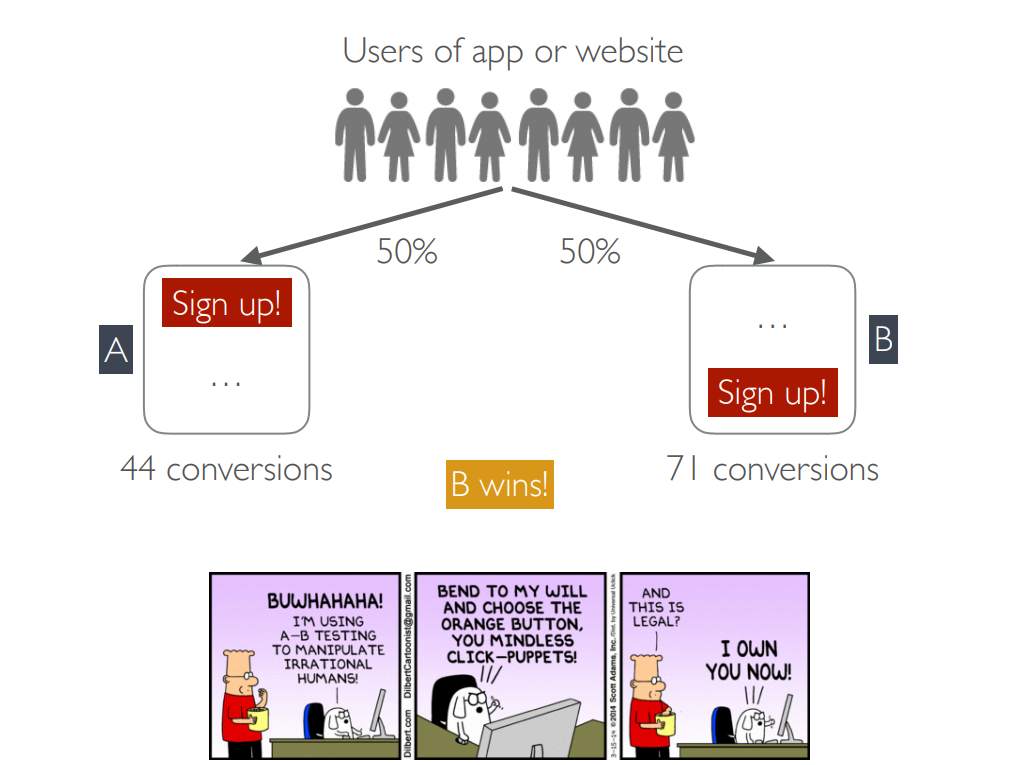
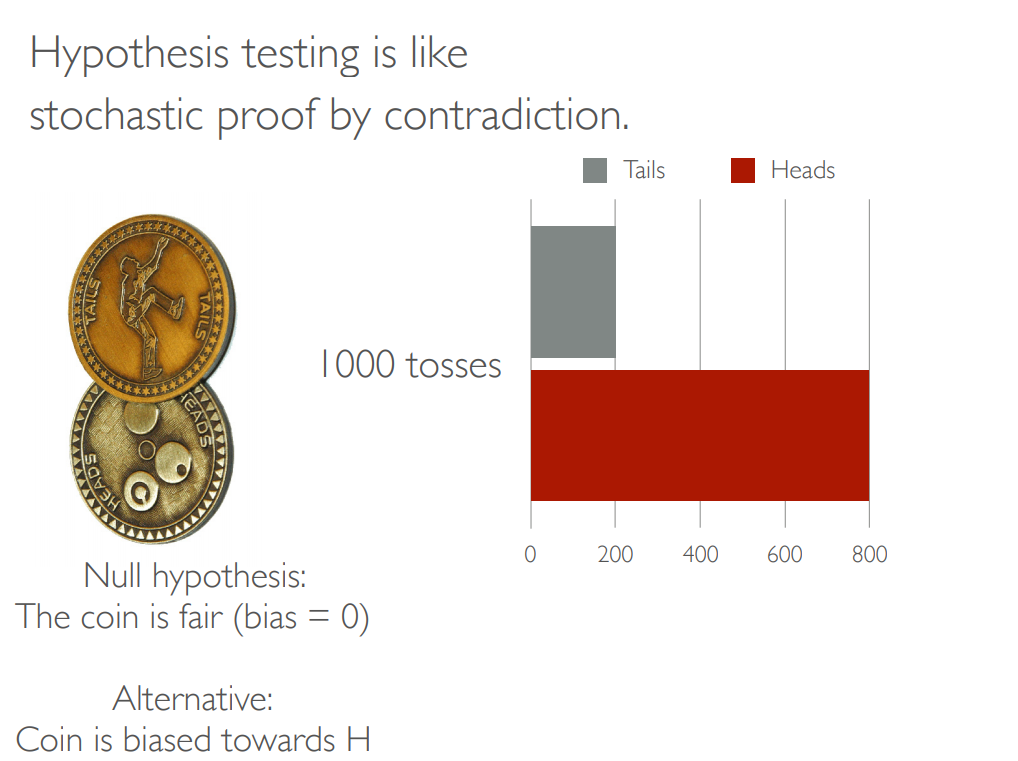
大规模序贯假设检验(A/B-testing)在科技行业十分盛行,互联网公司每年要进行数十万次检验。大约6年前,微软声称在Bing上进行的此类实验增加了数亿美元的收入(Kohavi等人,2013年),甚至9年前,谷歌也声称此类实验基本上是一个咒语(Tang等人,2010年)。这个实验实际上是“双重顺序的”,因为它由一系列连续的实验组成。 在本教程中,读者将了解在大规模、异步、双顺序实验中遇到的各种问题,包括内部顺序过程(单个顺序测试)和外部顺序过程(测试顺序),并了解最近开发的解决这些问题的原则。我们将讨论实验内和实验间的误差度量,并介绍可证明控制这些误差的最新方法,无论是否使用参数或渐近假设。特别是,我们将演示当前常见的窥视和边缘测试实践如何无法控制实验内和实验间的错误,但如何通过对实验设置进行简单而微妙的更改来减轻这些错误。我们还将简要讨论多臂bandit方法在检验假设中的作用,以及自适应抽样引入的选择偏差可能带来的陷阱。
讲座嘉宾
Reza Zafarani是锡拉丘兹大学EEC的助理教授。Reza的研究兴趣是社交媒体挖掘、数据挖掘、机器学习和社交网络分析。他的研究重点一直放在应对大规模数据分析的挑战上,以增强大数据的科学发现过程,特别是在社交媒体中。这些挑战包括没有基本事实的评估、快速识别大量数据集中的相关信息、利用有限信息进行学习、大规模用户行为分析和建模,以及跨多个数据源的信息集成和建模。他的研究成果已在各大学术机构发表,并在多家科学机构得到了强调。雷扎是《社交媒体挖掘:导论》一书的主要作者,该书由剑桥大学出版社和SIGKDD探索与传播前沿联合编辑编写。他是亚利桑那州立大学校长创新奖和优秀教学奖的获得者。