

人工智能(AI)已经在多个领域引发了革命,包括诸如医疗健康等安全关键领域。它已经显示出在医学中利用各种类型的医疗数据构建诊断和预测模型的卓越潜力。然而,尽管具有潜力,但医疗AI发展和随后在医疗系统中的采用存在两个主要障碍:1)训练能够在有限标记数据量下表现良好的AI模型具有挑战性。但是,筹备大规模标记数据集成本高昂;在某些情况下可能不可行;2)即使经过充分验证和测试,表现出色的先进模型在部署时可能无法推广到新患者,而且在分布变化下可能变得脆弱。这降低了对模型能力的信任,并限制了它们进入临床实践的采用。在本论文中,我通过提出三项不同的工作来解决医疗AI发展和部署中的上述障碍,即稳健性、数据效率和模型信任,以改进各种模态的当前最先进技术。在论文的第一部分,我提出了观察性监督,这是一种新颖的监督范式,我们在其中使用被动收集的辅助元数据来训练AI模型。我使用观察性监督来解决使用有限训练数据进行临床结果预测时的主要挑战。临床结果预测模型可以改善医疗护理并辅助临床决策,但通常只提供有限的训练数据,导致模型能力狭窄且泛化能力降低。审计日志通常是电子健康记录(EHR)系统中被低估的、被动收集的数据源,它们捕获了临床医生与EHR的互动,并代表了观察信号。我们提出的方法是利用观察性监督来结合临床数据,使用审计日志改进了两种临床重要疾病(急性肾损伤和急性缺血性中风)的AI模型的性能和稳健性,即使有限的标记训练数据。
在论文的第二部分,我提出了针对自监督基础模型的领域特定增强策略,以实现大规模、标签高效的AI模型训练。我解决了模型稳健性和标签效率的主要挑战。基础模型范式涉及使用自监督方式预训练模型,然后将预训练模型调整为不同的下游任务。基础模型为以标签高效的方式提高模型稳健性提供了机会。输入的增强或转换对于基础模型的成功至关重要;然而,医学图像与自然图像非常不同,需要专门的增强策略。我们提出的医学图像增强策略导致了领域特定的基础模型,提高了胸部X射线分类的性能,能够泛化到未见的人群和有限标签的分布外数据。在论文的第三部分,我提出了TRUST-LAPSE,一种可解释、事后和可操作的连续AI模型监控信任评分框架。我解决了模型信任的主要挑战。尽管模型在测试集上表现出色,但需要无标签、连续的模型监控,以量化对其预测的信任,以确保安全可靠的部署。目前,用于此目的的技术包括经典不确定性估计、信心校准和贝叶斯网络,并存在一些限制。我们提出的信任评分框架TRUST-LAPSE克服了这些限制,能够以高准确性(最先进的性能)确定部署模型的预测何时可以和何时不可以信任,能够识别模型在训练期间未见的类别或数据分布变化,并能够适应各种类型的输入数据(视觉、音频和临床脑电图)。综合这些工作为发展和部署稳健、数据高效和可信任的医疗AI模型以改善临床护理铺平了道路。
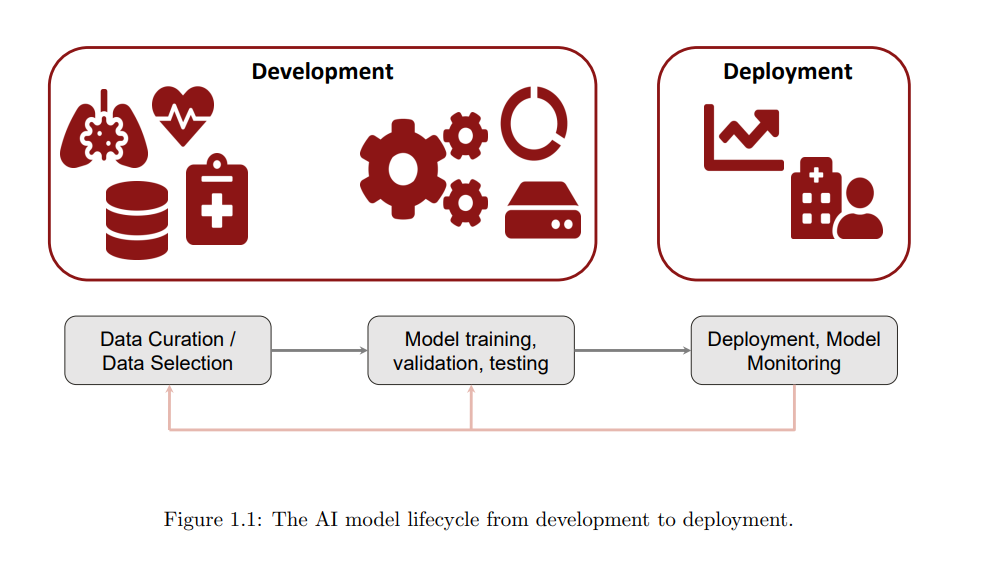
1.1 医疗健康与人工智能 美国和全球的医疗健康需要改进。目前,仅在美国,我们每年花费超过4万亿美元用于医疗健康 [2]。事实上,超过一半的医生感到过度疲劳 [3],其中近三分之二的时间都用在了繁琐的文书工作上 [4]。大流行病只是加剧了已经紧张的工作流程,暴露出临床护理质量的低效和不足。可预防的住院费用几乎为三百万美元 [5],而因医疗错误导致的死亡人数超过了25万 [6]。因此,医疗系统的各个方面都需要改进,包括减轻临床医生的负担,使医疗健康变得负担得起,并提高所有患者群体的医疗健康获取和质量。 人工智能(AI)可以解决上述若干挑战。现代AI方法,如机器学习和深度学习,其中一个模型通过统计优化受基础数据启发,特别在医疗健康领域显示出了潜力 [7, 8, 9]。这种现代AI方法是由大量高质量标记数据支持的。训练AI模型的第一步是收集这些大量数据并对其进行标记。通常,每个数据都与一个标签或目标相关联,模型必须预测该标签。标签可以是模型将要预测或检测的结果(分类);可以是描绘病变、器官或区域的分割;或者是实数风险评分(回归)。例如,从胸部X射线图中识别不同患者的病情的模型将需要图像标签对,标签指示图像中存在的疾病(如肋骨骨折、肺炎等)。从通过脑电图(EEG)记录的脑电活动中检测癫痫的模型将需要许多EEG剪辑-标签对,标签指示EEG剪辑中是否存在癫痫活动。确定患者未来是否可能经历临床结果的模型需要患者临床数据-标签对,标签指示患者是否经历了该结果。模型经过不同的训练和优化策略来预测给定数据样本的标签。然后,通常会在经过充分策划的测试集上对训练模型进行验证和测试。在模型经过充分训练和严格评估之后,它将被部署以在现实世界中为新数据进行预测。在此部署阶段,需要持续监控模型,以确保其性能符合预期,如果不符合预期,则需要进一步开发和改进。图1.1显示了AI开发的完整生命周期,直至部署阶段。
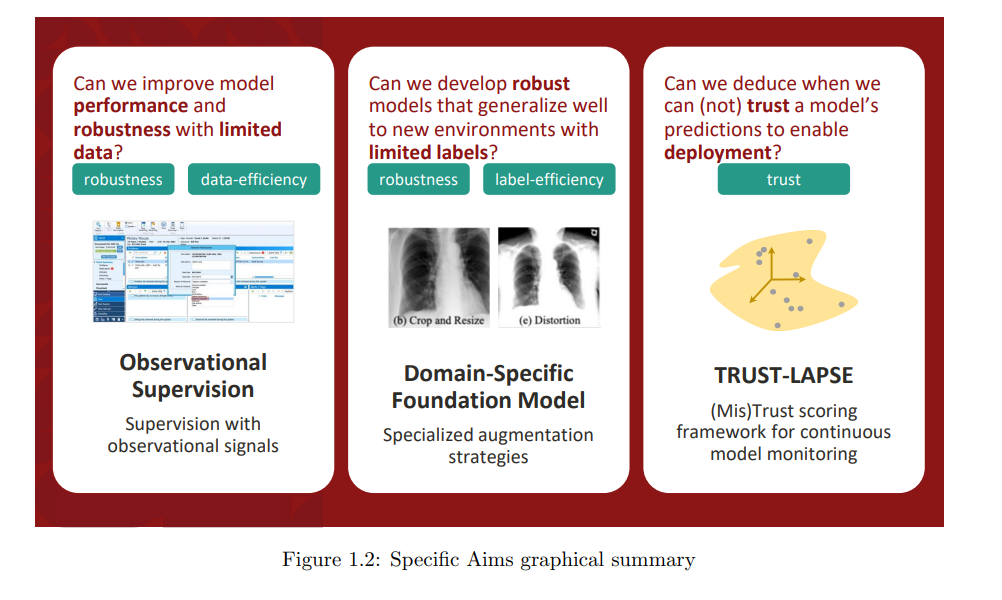
在我的论文中,我通过以下方式解决了医疗AI开发和部署中的上述障碍:(a) 开发了新颖的观察性监督技术,以改善模型在有限的训练数据下的性能和稳健性,(b) 开发了专门的领域特定增强策略,用于自监督基础模型,以提高模型在有限的训练标签下的性能和稳健性,(c) 开发了一个框架,用于在数据分布发生变化时检测模型预测何时可信以及何时不可信,以实现在部署后监测模型的可信度。 我将开发稳健、数据高效和可信任的医疗AI的总体目标组织为三个具体的目标,针对不同情景和不同下游临床应用,其数据(和标签)可用性各不相同。图1.2显示了本论文所探讨的三个基本问题的摘要。 观察性监督 具体目标1:开发观察性监督策略,以提高模型性能和稳健性,针对两个重要的临床结果预测问题,这些问题通常涉及有限的训练数据。
重要的临床结果预测问题,如预测急性肾损伤患者是否会在重症监护入院后的120天内经历严重肾脏事件(MAKE-120),以及预测急性缺血性中风患者是否会在出院后的30天内再次入院,通常涉及到有限的训练数据,即较小的患者队列。我们提出观察性监督,这是一种新颖的范式,在这个范式中,模型使用临床数据与电子健康记录(EHR)系统中记录的被动收集的观察信号进行训练。通过利用这些辅助元数据,观察性监督可以提高在有限的临床训练数据下模型的性能。
• 目标1.1:我们为急性肾损伤患者(AKI队列)和急性缺血性中风患者(中风队列)创建患者队列,并从EHR中提取这些患者队列的临床和审计日志数据。
• 目标1.2:我们对急性肾损伤患者的MAKE-120预测和中风患者的30天再入院预测分别进行了带有和不带有观察性监督的模型训练。
• 目标1.3:我们通过接收操作特征曲线下面积(AUROC)来严格评估这两个模型的结果预测性能。 • 目标1.4:我们研究了在训练具有和不具有观察性监督的模型时,对数据中潜在的时间分布变化的稳健性。 领域特定基础模型 具体目标2:开发专门的增强策略,以提高医学图像分类的模型性能、稳健性和标签效率,当有大量未标记数据可用于训练,但只有其中一部分被标记。 近年来,已经付出了大量努力来筹备用于医学图像分类的公共大规模数据集,尤其是胸部X射线分类。然而,获取高质量(即由专家制作的)标签是昂贵的,导致了有限数量的高质量标签。迄今为止,提出的用于胸部X射线分类的模型对不同类型的分布变化敏感,对来自不同医院和人群的数据,以及不同类别分布和类别不平衡表现出性能下降。为了解决这些挑战,我们专注于大规模基础模型,这些模型是以自监督的方式预训练的(无需标签),并具有各种成对增强策略。 • 目标1.1:我们使用通常用于自然图像的各种基线增强策略来预训练基础模型。 • 目标1.2:我们为胸部X射线分类任务开发了专门的预训练基础模型增强策略。 • 目标1.3:我们对使用每种增强策略预训练的基础模型在下游胸部X射线分类性能上进行了严格评估。 • 目标1.4:我们严格评估了这些模型对数据分布变化的稳健性,使用来自不同医院、不同疾病分布、不同少数类别和不同图像质量的数据。 TRUST-LAPSE 具体目标3:开发一个用于连续模型监控的框架,以便在部署后检测经过训练的模型的预测何时不可信,并在部署前检测模型自身何时不可信。
即使经过良好的训练和评估,模型在部署后的若干情况下也可能无法给出正确的输出,从而降低了对其能力的信任。因此,需要一个连续模型监控框架,可以检测模型的预测何时可信,何时不可信,以及何时模型自身对所有预测都不可信。我们提出了TRUST-LAPSE,一个用于连续模型监控的(不)信任评分框架,以为模型部署提供这些功能。 • 目标1.1:我们确定了连续模型监控系统的要求,并将信任确定为一个数学问题,其中生成信任分数,指示模型的预测可信度程度,以及预测。 • 目标1.2:我们开发了一种新颖的信任评分框架TRUST-LAPSE,在该框架中,使用模型引发的潜在空间中的互补指标来确定对预测的信任,并使用这些指标的序列来建立对模型自身的整体信任。 • 目标1.3:我们制定了一种评估策略,以测试系统在三个不同数据领域(视觉、音频和临床时间序列)上的性能。 • 目标1.4:我们严格评估了该框架在区分可信样本和不可信模型输出以及在何时识别模型自身变得不可信方面的能力,与强基线进行了比较。






