在大模型时代,内容生成逐渐向个性化生成(Personalized Generation, PGen)转变,以满足个体用户的偏好和需求。本论文首次对PGen进行了全面综述,系统性地梳理了该领域的现有研究,并对其关键组成部分、核心目标及抽象工作流程进行了统一建模。 基于这一统一视角,我们提出了一种多层次的分类体系(multi-level taxonomy),深入回顾了不同模态、个性化场景和任务下的技术进展、常用数据集及评估指标。此外,我们展望了PGen的潜在应用,并探讨了当前面临的开放性挑战与未来研究方向。 通过跨模态整合PGen研究,本综述为该领域的知识共享与跨学科合作提供了有价值的参考,助力构建更加个性化的数字生态。
1 引言
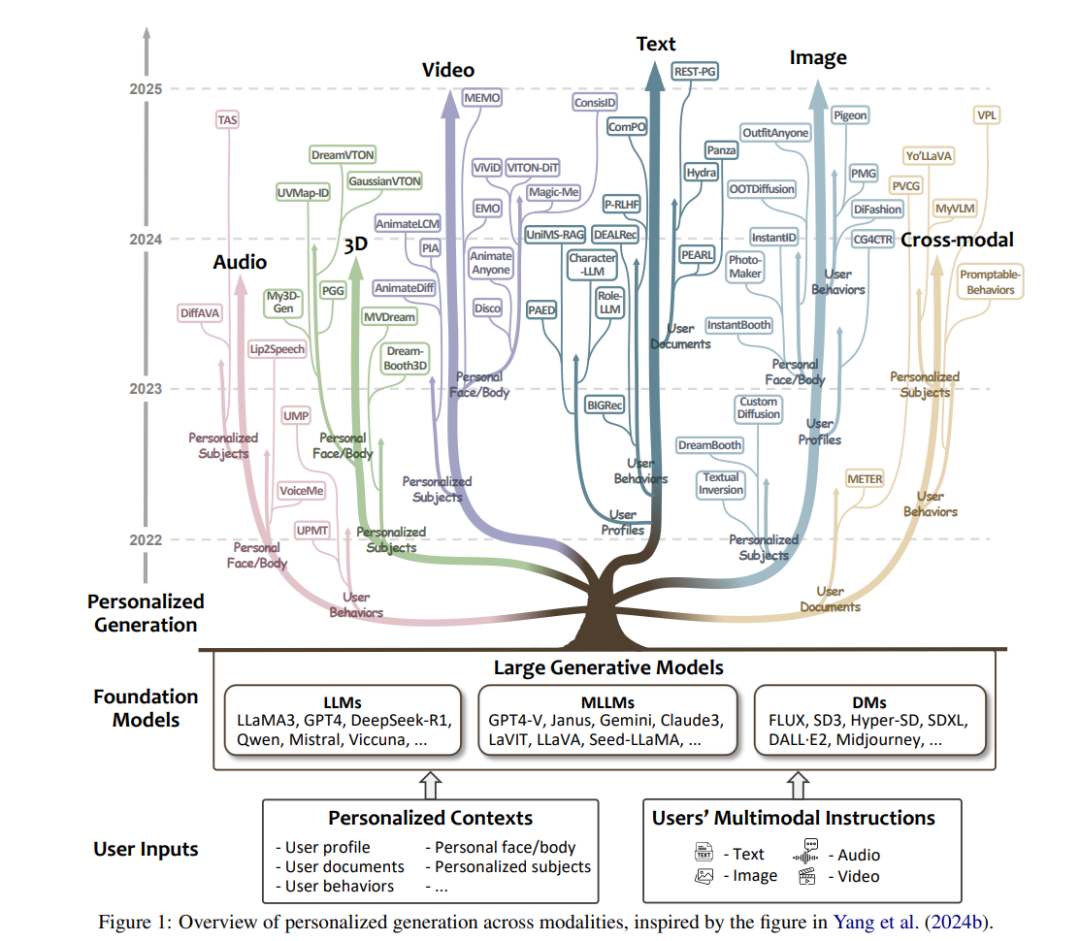
近年来,大型生成模型的突破性进展推动了内容生成范式的变革,从通用化、一刀切的生成模式,向更加个性化生成(Personalized Generation, PGen)转变(Wang et al., 2023c; Xu et al., 2024c; Nguyen et al., 2024b)。PGen 通过定制化内容满足个体用户的偏好和需求,在多个领域展现出巨大潜力,例如电商中的个性化产品图像(Yang et al., 2024a)、营销活动中的个性化广告(Tang et al., 2024a)、以及个性化 AI 助手(Zhang et al., 2024a)。由于其广阔的应用前景,PGen 受到了学术界和工业界的广泛关注。 尽管 PGen 研究已取得显著进展(Alaluf et al., 2025; Salemi et al., 2024b),但这一领域的研究主要在不同社区(如自然语言处理 NLP、计算机视觉 CV 和信息检索 IR)内独立发展,尚无专门的综述提供跨领域的 PGen 研究概览。目前,与 PGen 相关的综述大多采用**模型导向(model-centric)或任务导向(task-centric)**的视角,仅涵盖部分相关研究:
-
模型导向综述 关注特定生成模型在个性化任务中的应用,如多模态大语言模型(MLLMs)(Wu et al., 2024b)、大语言模型(LLMs)(Zhang et al., 2024j; Chen et al., 2024e; Li et al., 2024i)、以及扩散模型(Diffusion Models, DMs)(Zhang et al., 2024g)。
-
任务导向综述 总结个性化生成在特定应用场景中的方法,如对话生成(Dialogue Generation)(Chen et al., 2024f)、角色扮演(Role-playing)(Chen et al., 2024d; Tseng et al., 2024)、以及生成式推荐(Generative Recommendation)(Ayemowa et al., 2024)。
然而,现有综述均未提供一个能够跨领域综合 PGen 研究的统一框架。构建统一框架对于系统回顾 PGen 的最新进展和发展趋势至关重要,它不仅能提供对该领域的全景式理解,还能促进不同研究社区之间的交流、知识共享和合作,从而推动更加智能、个性化的数字生态系统的发展。 然而,构建这样的统一综述面临诸多挑战,不同研究社区关注的模态存在显著差异。例如,自然语言处理(NLP)和信息检索(IR)社区主要关注文本模态,而计算机视觉(CV)领域则专注于图像、视频和 3D 内容。由于不同模态涉及不同的数据结构和技术挑战,这些模态特异性(modality-specific)差异导致 PGen 研究在不同社区间存在技术分歧,难以形成统一的框架。
研究目标与贡献
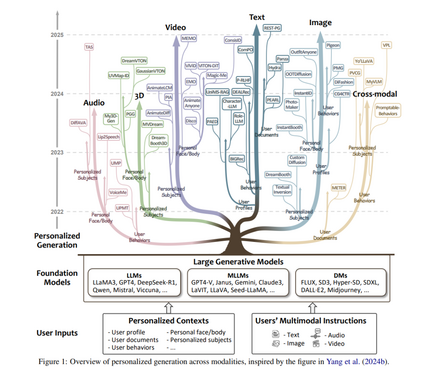
为解决上述问题,我们从高层次、模态无关(modality-agnostic)的角度重新审视 PGen。本质上,PGen 需要基于个性化上下文和多模态指令进行用户建模,并提取个性化信号来引导内容生成过程。如 图 1 所示,现有 PGen 研究的核心在于建模用户输入,并利用生成模型在不同模态下实现个性化内容生成。 为此,本论文提出首个专注于 PGen 的系统性综述,其主要贡献如下:
- 基于用户中心的 PGen 统一视角(第 2 章):我们通过形式化 PGen 的关键组成部分、核心目标和通用工作流程,将不同模态下的研究整合进一个统一框架。
- PGen 研究的多层次分类体系(第 3 章):基于统一视角,我们提出了一种新型分类方法,系统回顾 PGen 在不同模态、个性化场景和任务中的技术进展、常用数据集及评估指标。
- PGen 在用户中心服务中的潜在应用展望(第 4 章):我们按内容个性化的不同阶段,对 PGen 在内容创建与分发过程中的应用进行了分类与探讨。
- PGen 研究的关键开放问题(第 5 章):我们总结了未来研究需解决的核心问题,为 PGen 领域的创新和发展提供方向性指引,助力构建更加个性化的内容生态系统。
本综述致力于打破不同研究社区的壁垒,促进跨领域融合,为 PGen 研究提供系统性指导,推动更加智能和个性化的数字内容生成技术的发展。
- 个性化生成的统一用户中心视角
2.1 任务形式化
PGen利用生成模型合成符合个人偏好和特定需求的内容。如图1所示,它依赖于两个基本的用户输入:1)个性化上下文,包含用户偏好;2)用户的多模态指令,包括文本提示、语音命令和其他模态特定的输入,明确传达其内容需求。生成模型从多样化的个性化上下文中学习用户偏好和个人特征,并遵循用户的多模态指令,生成跨不同模态的定制内容。个性化上下文包括以下维度: * 用户档案:与特定用户相关的人口统计和个人属性集合,如年龄、性别、职业和位置。 * 用户文档:用户创建的文本内容,如评论、电子邮件和社交媒体帖子,反映个人创作偏好。 * 用户行为:用户参与过程中捕获的用户交互,如搜索、点击、点赞、评论、观看、分享和购买。 * 个人面部/身体:个人的面部和身体特征,包括静态特征(如面部结构和体型)和动态特征(如表情、手势和动作)。这些广泛用于肖像生成、时尚虚拟试穿和3D建模等任务。 * 个性化主题:用户特定的概念或实体,如宠物、个人物品和喜爱的对象,反映独特品味。
通过将个性化上下文与用户的多模态指令相结合,生成模型可以创建高度定制的内容,紧密贴合个人偏好并满足特定需求。
2.2 目标
尽管每种模态中的PGen由独特的数据结构、特定挑战和不同任务塑造,但三个基本目标和评估维度在所有模态中保持一致: * 高质量:确保生成的内容符合高标准的连贯性、相关性和美学。 * 指令对齐:要求生成的内容准确遵循用户的多模态指令并有效满足其需求。 * 个性化:保证生成的内容与个性化上下文一致,并迎合特定用户偏好。
尽管文本生成始终能够实现高质量输出,但在其他模态(如图像、视频、音频和3D生成)中,生成的内容有时可能显得混乱或脱节。在所有模态中保持高质量标准是实现成功个性化生成的基础。此外,在某些领域(如新闻、法律、政策和专家知识),事实准确性尤为重要,生成模型必须优先考虑真实性,以确保提供给用户的内容的可靠性和可信度。
2.3 工作流程
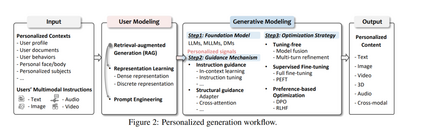
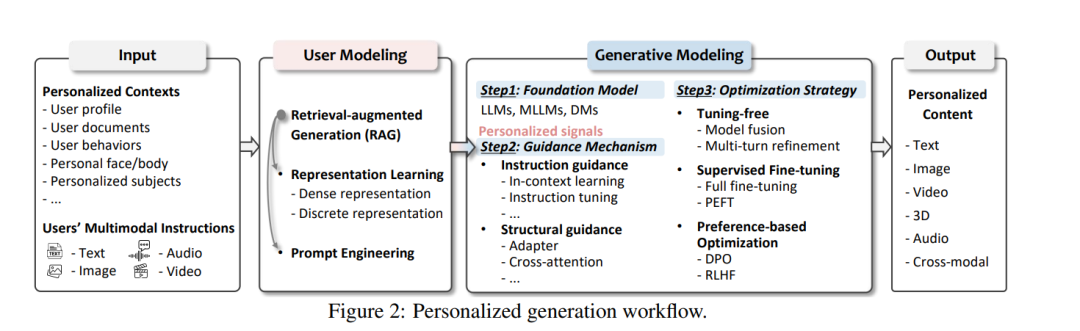
如图2所示,PGen工作流程涉及两个关键过程:1)基于多样化用户特定数据的用户建模;2)跨多种模态的生成建模,确保高质量、指令对齐和个性化的内容。 用户建模:为了有效捕捉用户偏好和特定内容需求,基于个性化上下文和用户的多模态指令,通常采用三种关键技术:1)表示学习,将这些输入编码为密集嵌入或总结为离散表示(如文本);2)提示工程,设计任务特定的提示以结构化用户特定信息;3)检索增强生成(RAG),通过过滤无关信息并整合外部相关数据来丰富用户特定信息。通过结合这些技术,用户建模为PGen建立了坚实的基础,提取个性化信号以指导生成建模过程中的内容个性化。 生成建模:为了有效生成个性化内容,生成建模遵循结构化的三步过程: * 步骤1:基础模型。在大模型时代,LLMs、MLLMs和DMs作为内容生成的骨干。根据目标模态、任务要求和用户特定数据选择适当的基础模型对于实现准确和个性化的内容至关重要。 * 步骤2:指导机制。为了有效整合个性化信号,采用两种主要指导机制:指令指导和结构指导。具体而言,指令指导确保模型遵循显式用户提示和指令,使用上下文学习和指令调优等技术。相比之下,结构指导通过引入附加模块(如适配器和交叉注意力机制)来修改模型架构,以嵌入个性化信息。 * 步骤3:优化策略。赋予大型生成模型个性化生成能力涉及三种主要优化策略:1)免调优方法,利用预训练模型进行个性化生成而不修改模型参数;2)监督微调,使用显式监督信号优化模型参数;3)基于偏好的优化,结合用户偏好数据更新模型参数。
通过整合这些先进技术和策略,该工作流程不仅确保了对多样化个性化上下文和用户指令的适应性,还突出了大型生成模型的不断演变,为PGen提供了可扩展的解决方案。
3. 跨模态的个性化生成
基于统一视角,我们提出了PGen的多层次分类法,系统回顾了跨各种模态、个性化上下文和任务的PGen研究,如表1所示。PGen的研究首先按模态分类,包括文本、图像、视频、音频、3D和跨模态生成。在每个模态内,我们进一步根据个性化上下文对研究进行分类,并检查相应的任务和技术。此外,我们还提供了每个模态常用数据集和评估指标的全面概述,总结在表2、表3和表4中。
3.1 个性化文本生成
个性化文本生成旨在提供符合用户偏好和需求的文本内容,涉及从信息寻求到用户模拟的任务。
**3.1.1 用户行为
用户与系统的交互通常随时间发生,允许系统学习隐式偏好和行为模式以增强个性化并鼓励长期参与。这种个性化上下文对于以下个性化文本任务非常有价值。 信息寻求:个性化文本生成的主要用例是制作符合用户偏好的响应,从而实现更具吸引力的交互。系统可以利用用户反馈(如点赞/点踩和选择的最佳响应)来调整其响应以符合用户偏好。尽管个性化在信息访问和搜索环境中得到了广泛研究,但在生成场景中仍然相对未被充分探索,这主要是由于缺乏标准化指标和基准。 推荐:虽然推荐不直接涉及内容生成,但在提供个性化内容方面起着至关重要的作用。生成模型在推荐系统(RecSys)中的应用已被广泛研究,特别是LLMs通过提示或直接训练来执行推荐任务。
**3.1.2 用户文档
在某些情况下,用户可能不经常与系统交互,但可以提供有价值的个性化信息,如用户创建的文档。 写作助手:个性化在增强基于文本的写作助手中起着关键作用,能够跨不同格式和风格生成定制文本。为此,LaMP基准专注于短文本生成,如创建新闻文章标题或电子邮件主题行。相比之下,LongLaMP基准针对较长形式的任务,如从用户的角度撰写产品评论。
**3.1.3 用户档案
生成模型可以从用户档案中推断用户偏好,以指导个性化文本生成。 对话系统:近年来,聊天机器人和对话系统已成为个性化文本生成的核心焦点。通过基于用户档案定义模型的人设或个性,系统可以调整响应以符合个人偏好和需求。 用户模拟:先前的研究表明,LLMs擅长执行分配给它们的角色或人设,从而基于用户档案进行用户模拟以提取偏好并进一步个性化系统。
**3.1.4 评估指标
评估个性化文本生成具有挑战性,因为只有目标用户才能准确确定生成的内容是否符合其偏好和需求。一种评估个性化文本生成的方法是通过人工判断,个人评估生成内容的质量和相关性。自动评估可以使用基于参考和无参考的方法进行。
3.2 个性化图像生成
个性化图像生成旨在合成反映个人偏好和需求的图像。通过结合各种个性化上下文,现有研究在增强生成模型生成符合特定需求的图像能力方面取得了显著进展。
**3.2.1 用户行为
用户交互是推断视觉偏好的关键来源,指导个性化图像生成过程。基于用户行为(如历史互动和实时反馈),现有方法探索了各种增强个性化的方法。 通用图像生成:该任务涉及在各种场景中生成定制图像。例如,PMG、I-AM-G和Pigeon利用用户历史互动图像推断其视觉品味,从而在各种场景中实现个性化生成。 时尚设计生成:该任务涉及通过推断用户行为中的个人时尚品味生成个性化时尚设计。 电子商务产品图像生成:该任务旨在为电子商务产品创建定制的、吸引眼球的视觉效果,以吸引目标消费者。
**3.2.2 用户档案
一些研究利用用户的人口统计属性推断偏好或将其分类为组以进行个性化图像生成。 时尚设计生成:基于用户属性(如年龄、性别、对角色感兴趣),LVA-COG利用LLMs提取用户偏好以指导时尚设计生成。 电子商务产品图像生成:通过根据用户属性将其分类为不同组,CG4CTR提出了自循环生成管道,为每个用户组生成定制产品图像。
**3.2.3 个性化主题
这是计算机视觉社区的主要焦点,旨在从有限的主题图像中捕捉主题表示,并遵循用户指令进行主题驱动的文本到图像(T2I)生成。 主题驱动的T2I生成:该领域的研究可以大致分为两类:优化方法和编码器方法。
**3.2.4 个人面部/身体
个人面部和身体图像已成为个性化图像生成的热门选择,因为它们与个人身份高度相关。通过利用这些图像,生成模型可以创建高度定制和逼真的图像,反映用户的独特身份,同时遵循用户特定的要求。 面部生成:生成模型利用个人面部图像创建高保真肖像或头像,保留个人面部身份,同时遵循用户的多模态指令,如修改表情、动作和背景。 虚拟试穿:该任务旨在通过将指定服装与个人的身体和面部图像结合,合成逼真的试穿图像。
**3.2.5 评估指标
为了评估生成图像与个性化上下文的对齐以及遵循用户多模态指令的程度,大多数研究依赖于相似性指标,如LPIPS和SSIM。此外,预训练模型如CLIP和DINO通常用于提取图像特征以计算余弦相似度,从而进行更上下文化的个性化和指令对齐评估。
3.3 个性化视频生成
个性化视频生成旨在生成反映个人偏好、特征和特定需求的定制视频内容。
**3.3.1 个性化主题
在某些情况下,用户可能提供一个或多个个性化主题的图像,如对象或概念,以及指定的文本提示,要求生成模型执行主题驱动的文本到视频(T2V)生成。 主题驱动的T2V生成:鉴于各种个性化模型在主题驱动的T2I生成中的巨大成功,AnimateDiff、PIA和Still-Moving等方法通过引入附加模块将这些模型适应于T2V生成。
**3.3.2 个人面部/身体
同样,用户可能提供一个或多个个人面部和身体图像,使生成模型能够合成保留其身份并遵循多模态指令的个性化视频。 ID保留的T2V生成:该任务侧重于创建与个人面部ID和指定文本提示对齐的个性化视频。 说话头生成:该任务旨在合成与音频剪辑同步的说话视频。 姿势引导的视频生成:最近的研究探索了通过各种条件机制将个人面部和身体图像适应特定姿势序列以进行视频生成。 视频虚拟试穿:该任务旨在将指定服装无缝转移到源视频中的人身上,同时保留其动作和身份。
**3.3.3 评估指标
为了评估个性化和指令对齐,类似于个性化图像生成,现有研究通常依赖于相似性指标,如LPIPS、SSIM和PSNR。此外,预训练图像编码器如CLIP和DINO经常用于提取帧级特征并计算余弦相似度以进行定量评估。
3.4 个性化3D生成
个性化3D生成涉及将用户的个性化视觉或文本上下文(如身体形状、面部特征、图像和提示)转换为3D资产。
**3.4.1 个性化主题
个性化3D生成的最常见范式是用户提供一些基于图像的个性化主题,然后生成相应的3D资产。 图像到3D生成:个性化图像到3D生成专注于创建准确捕捉给定个性化主题的几何和外观的3D资产。
**3.4.2 个人面部/身体
在某些情况下,用户可能提供个人面部和身体图像或单目视频,旨在生成保留身份的3D资产。 3D面部生成:对于3D面部生成,Zhang等人引入了PoseGAN模块,用于生成动态头部姿势。 3D人体姿势生成:Huang等人将源图像形状信息与2D关键点结合,生成个性化UV图。 3D虚拟试穿:3D虚拟试穿能够从最小输入(如用户图像、服装图像和文本提示)创建高质量、定制的3D模型。
**3.4.3 评估指标
为了量化3D生成中的个性化和指令对齐,现有研究通常使用相似性指标,如LPIPS、SSIM、PSNR和CLIP分数,类似于图像和视频生成。此外,一些任务特定的分数可以通过预训练模型进行评估,如面部属性分类器。
3.5 个性化音频生成
个性化音频生成提取用户的听觉偏好以创建定制的音频内容,如音乐和语音。
**3.5.1 用户行为
用户在音乐上的行为,如听歌历史和评分,是推断用户个性化偏好的重要线索。 音乐生成:UMP和UP-Transformer等方法通过分析听歌历史和评分推断用户偏好。
**3.5.2 个性化主题
在某些情况下,用户提供音频片段并旨在通过文本提示操作它们。 文本到音频生成:个性化文本到音频生成探索了通过对齐用户偏好、文本描述和上下文输入来合成定制音频的方法。
**3.5.3 个人面部/身体
用户可能提供其面部图像或视频,使生成模型能够提取说话者特定属性以进行定制语音生成。 面部到语音生成:VioceMe使用SpeakerNet导出说话者嵌入,并结合全局风格标记(GST)来建模语音风格。
**3.5.4 评估指标
为了量化音乐转移和文本到音频生成等任务中的个性化和风格对齐,现有研究通常使用相似性指标,如CLAP分数、模式相似性(PS)和嵌入距离。
3.6 个性化跨模态生成
个性化跨模态生成主要旨在基于多模态个性化上下文(如图像、视频、历史机器人轨迹)生成个性化文本响应(如标题、答案或机器人动作)。
**3.6.1 用户行为
基于用户交互,生成模型可以推断用户偏好以定制机器人行为。 机器人:几项研究调查了从历史轨迹和相关人类反馈中推断用户偏好,从而实现个性化机器人决策。
**3.6.2 用户文档
用户创建的文档,如评论、评论和标题,可用于推断其写作风格和偏好以进行个性化。 标题/评论生成:几项研究利用用户创建的标题和评论开发个性化标题和评论系统。
**3.6.3 个性化主题
在某些情况下,用户可能提供特定主题图像,如朋友的照片,用于个性化视觉问答。 跨模态对话系统:给定用户特定的主题图像和查询,系统应识别这些主题并推断用户意图以生成个性化响应。
**3.6.4 评估指标
为了量化文本生成任务(如个人助理和评论生成)中的个性化,现有研究通常采用(1)术语匹配指标,如ROUGE、BLEU、Meteor、CIDEr;(2)语义匹配指标,如CLIPScore;(3)召回率、精确率和F1分数,以验证用户特定概念是否出现在生成的标题中;(4)人工评估,以确定与地面实况在情感、风格和相关性方面的对齐。
4 应用(Applications)
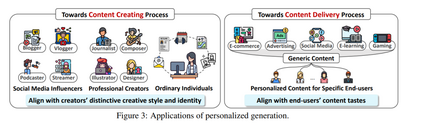
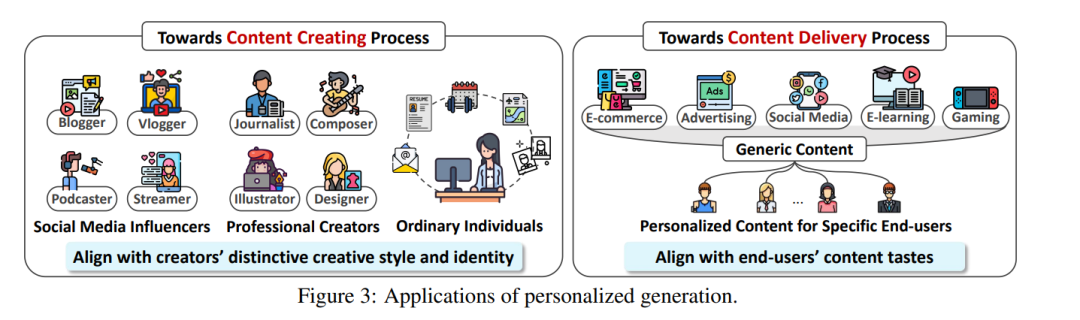
前一部分已经强调了 PGen 在不同模态下的成功应用,展示了其在提升用户互动体验和丰富多样领域中的潜力。如图 3 所示,PGen 的应用可根据内容个性化的不同阶段进行分类:
- 面向内容创作过程——为各类内容创作者提供个性化工具和服务,使其在保持独特创作风格的同时,提高创作流程的效率;
- 面向内容交付过程——以个性化方式向最终用户推送多模态内容,使其符合个体偏好。
4.1 面向内容创作过程(Towards Content Creation Process)
生成式模型 正在重塑内容创作的格局,拓展生产力和创造力的边界。通过结合个性化技术,PGen 可进一步赋能各类内容创作者,使其在提高创作效率的同时,保留自身独特的创作风格和身份。
- 社交媒体创作者(如博客作者、视频博主、播客主持人)可利用 PGen 分析其过往内容,提供定制化的标题建议(Fang et al., 2024a)与引言,甚至生成符合其品牌形象的全新内容。这不仅优化了创作流程,还确保了风格一致性,促进与受众更深入的互动。
- 专业创作者(如记者、设计师、插画师、音乐作曲家)通常依赖独特的创作风格来建立声誉。PGen 通过分析他们的以往作品,识别并适应其风格特征,从而提供定制化的创意建议、草稿或修改方案,帮助创作者在个人风格与外部需求之间找到最佳平衡。
- 普通用户 也可以通过 PGen 简化日常任务,如个性化邮件撰写、简历制作、旅行规划、健身安排和人像生成等。
4.2 面向内容交付过程(Towards Content Delivery Process)
在信息爆炸的时代,个性化内容分发 变得越来越重要,有助于用户更有效地筛选和获取海量的多模态内容。通过将 PGen 集成到内容交付流程中,通用内容可以转换为多样化、个性化的形式,以吸引不同受众,并满足他们独特的内容需求。以下是 PGen 在个性化内容交付方面的典型应用场景:
- 营销与广告(Marketing and Advertising)
PGen 可帮助企业制定精准营销策略,并生成具有动态调整能力的广告,使其更契合特定受众的兴趣点,提高点击率和转化率。
- 零售与电商(Retail and E-commerce)
通过个性化产品描述、商品图片、用户手册以及虚拟试穿等功能,PGen 可提升消费者的购物体验,提高用户粘性和销售额。
- 娱乐与媒体(Entertainment and Media)
在 Flipboard、Twitter、Netflix、YouTube 等数字内容平台,个性化内容对用户留存起着至关重要的作用。例如,PGen 可生成个性化新闻摘要、社交媒体帖子、电影海报、视频缩略图等,以提升用户对平台的忠诚度。
- 教育与在线学习(Education and E-learning)
生成式模型在教育领域展现出巨大潜力,如 Google Learn About 等平台。PGen 可进一步提升个性化教育体验,例如提供定制化学习路线和学习资料,动态适应不同用户的学习风格、目标和进度。
- 游戏(Gaming)
将 PGen 集成到游戏行业,可实现动态故事线、个性化任务、可扩展的难度级别、交互式角色等,使游戏体验更具沉浸感和互动性。
- 个性化 AI 助手(Personalized AI Assistant)
PGen 可用于 AI 助手,提供专业化支持(如法律咨询、医疗建议、财务指导等),确保高精准度和用户定制化体验。
**
**
5 关键挑战(Open Problems)
尽管 PGen 在内容个性化方面取得了重大进展,但仍面临多个关键挑战。
5.1 技术挑战(Technical Challenges)
- 可扩展性与效率(Scalability and Efficiency)
PGen 依赖大型生成模型进行内容个性化,这通常需要大量计算资源,限制了其在实时、大规模用户场景下的应用。开发高效、可扩展的算法 仍是未来研究的关键方向(Yang et al., 2024c)。
- PGen 的推理优化(Deliberative Reasoning for PGen)
在某些场景下(如数字广告),内容质量比生成速度更重要。因此,如何在推理过程中进行多轮优化,提高内容的相关性和个性化程度,是一个重要的研究方向(Nabati et al., 2024)。受 LLM 推理能力 成功经验的启发(Guan et al., 2024;Guo et al., 2025),未来研究可探索基于深度逻辑推理的 PGen,以更精准地分析用户偏好(Fang et al., 2025)。
- 用户偏好的动态变化(Evolving User Preference)
传统推荐系统(RecSys)已广泛研究了用户行为的动态变化(Wang et al., 2023d),PGen 需要适应这些变化,以提供更符合用户期望的个性化内容。
- 多模态个性化(Multi-modal Personalization)
现有 PGen 研究主要关注单模态内容生成,而多模态个性化(如结合图像和文本的个性化社交媒体帖子)仍处于探索阶段。实现高质量、指令对齐且跨模态一致的个性化输出是一个关键挑战。
- 生成与检索的协同优化(Synergy Between Generation and Retrieval)
传统的个性化内容分发系统主要依赖检索方法(如推荐系统)。然而,已有内容可能无法完全满足用户需求。将 PGen 与检索方法结合,构建更强大的个性化内容分发系统,是一个值得研究的方向(Wang et al., 2023c)。
5.2 评测基准与指标(Benchmarks and Metrics)
PGen 的一个核心挑战是建立可靠的评测指标和数据集。现有评测方法主要依赖传统生成指标(如 BLEU 用于文本,CLIP-I 用于图像),但这些指标无法全面衡量生成内容是否符合用户个性化偏好。未来研究应探索更有效的个性化评测指标。
5.3 可信性问题(Trustworthiness)
确保 PGen 的可信性至关重要,以提升用户信任度并促进其负责任的部署。关键考虑因素包括:
- 隐私保护(Privacy)
PGen 依赖用户数据进行个性化内容生成,因此涉及隐私安全问题。如何在个性化与隐私保护之间取得平衡 是该领域的关键挑战。
- 公平性与偏见(Fairness and Bias)
由于训练数据的局限性,PGen 可能会无意中强化偏见和刻板印象,导致不公平或歧视性内容。有效的偏见检测和消除策略对于保护不同用户群体至关重要。
- 安全性(Safety)
透明的治理协议、可靠的内容审核机制、可解释的生成过程对于用户信任和系统安全性至关重要。
6 结论(Conclusion)
本文首次对 PGen 在多模态内容个性化 方面的研究进行了全面综述,系统回顾了该领域的最新进展和研究趋势。通过构建一个整体框架,我们统一了现有研究,并提出了多层分类体系,总结了不同模态下的常用数据集与评测指标。此外,我们分析了 PGen 在内容创作与内容分发中的广泛应用,并探讨了未来挑战和研究方向。 作为一个快速发展的研究领域,PGen 未来有望重塑数字内容生态,推动更个性化和沉浸式的用户体验。我们希望本综述能够促进跨模态知识共享与合作,为构建更加个性化的数字世界提供支持。