随着大语言模型与视觉模型在现实应用中的广泛采用,如何应对“幻觉”问题——即模型生成错误或无意义输出的情况——已成为紧迫需求。这类错误在部署过程中可能导致错误信息的传播,从而带来财务和运营上的损失。尽管已有大量研究致力于缓解幻觉,但我们对其的理解依然不完整且零散。缺乏统一的理解框架可能导致现有方法只是在缓解表层症状,而非解决深层原因,从而限制了方法在实际部署中的有效性与普适性。 为弥补这一空白,我们首先提出了一个统一的、多层次框架,用于在不同应用场景下表征文本和图像幻觉,从而减少概念上的碎片化。随后,我们将这些幻觉与模型生命周期中的特定机制联系起来,并通过一种任务-模态交织的方法促进更为整体的理解。我们的研究表明,幻觉往往源于数据分布中可预测的模式以及继承的偏差。通过加深对幻觉的理解,本综述为开发更健壮、更有效的解决方案奠定了基础,从而提升生成式人工智能系统在现实环境中的可靠性。 **
**
附加关键词与短语: 幻觉成因,多模态失效分析,生成式人工智能,幻觉分类学,视觉-语言模型。
1 引言
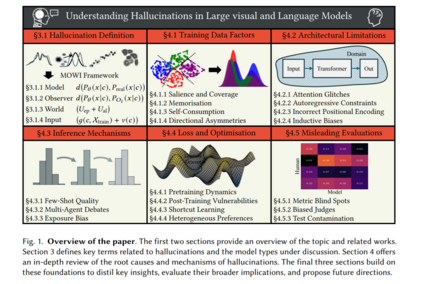
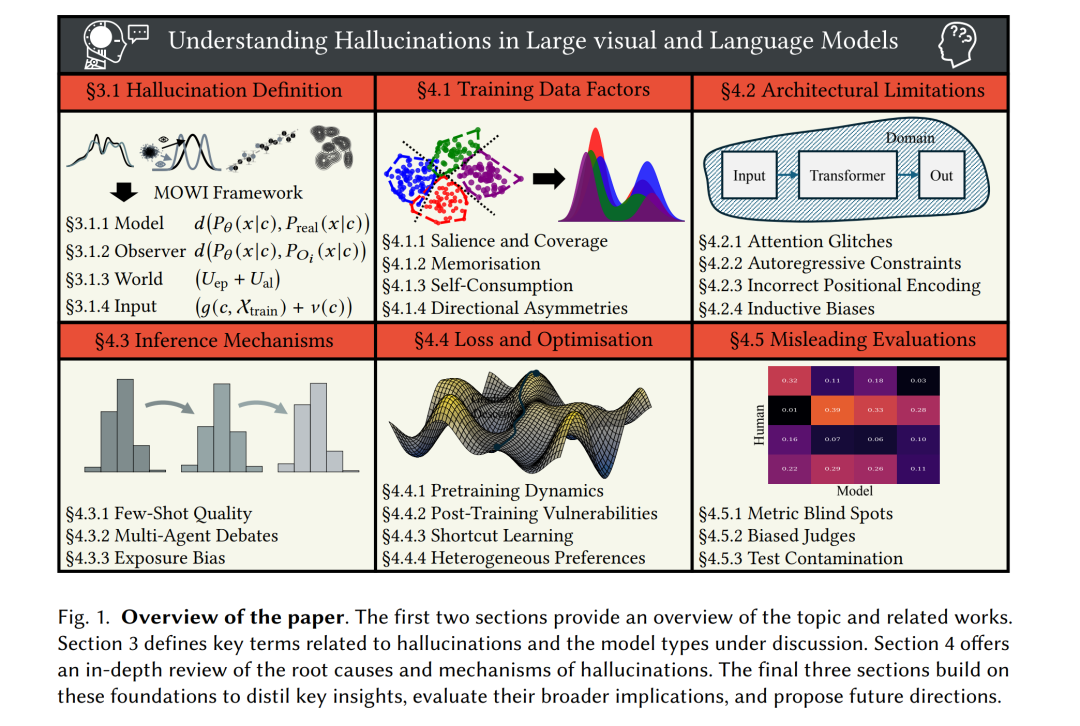
大语言模型(Large Language Models, LLMs)、大规模视觉-语言模型(Large Vision-Language Models, LVLMs)以及文本生成视觉模型(Text-to-Vision Models, TVMs)如今已支撑了众多现实应用,影响着数百万用户。截至 2024 年,已有超过 77,000 家组织使用 GitHub 的 Copilot LLM 辅助软件开发 [21]。在专业媒体领域,Adobe 的 Firefly TVM 已经生成超过 45 亿次内容 [124]。ChatGPT 现已为超过 100 万家企业用户提供日常任务支持 [46],而 Google 的 Gemini LVLM 正在跨行业自动化复杂的图文工作流 [99]。 尽管应用广泛,这些模型经常会生成错误、不一致或不连贯的内容——这一现象被称为幻觉(hallucinations)[10, 26, 105, 158]。幻觉可能带来实际危害:例如,存在缺陷的代码建议会损害软件可靠性 [97];不连贯的 AI 生成媒体降低了用户参与度 [73];而不一致的图文分析则会削弱工作流质量 [51]。随着越来越多的组织依赖这些模型来塑造数百万用户使用的下游产品与服务,如何应对语言和视觉模型中的幻觉问题已成为一项关键挑战。 尽管已有大量努力致力于解决幻觉,但仍存在两个关键空白。首先,我们对幻觉的理解仍然有限。现有研究大多集中于缓解策略,这些方法通常是对观察到的失败案例作出的回应,而非基于对幻觉成因的系统性理解。因此,许多缓解技术可能仍然是被动且不完整的,从而限制了其有效性与性能。其次,幻觉相关研究仍然是碎片化的,缺乏系统化。不同研究常常采用针对特定任务或模态的狭窄或经验性定义,这使得我们难以得出更广泛的见解或识别可能揭示更深层次成因的共性失效模式。结果是,开发具备更强泛化性和稳健性的缓解策略受到了显著阻碍。要降低幻觉在实际应用中带来的风险,亟需填补这两方面的空白:加深理解与减少碎片化。 为弥补这些不足,我们提出了对幻觉进行深入调查与系统化刻画的研究。我们的工作包含三个主要贡献: 1. 提出统一框架:该框架为幻觉提供了一个更为通用的定义。与先前工作不同,它充分考虑了不同模态和任务的差异性,大幅提升了适用性与覆盖面。这有助于减少现有讨论中的碎片化,推动围绕幻觉现象更为连贯的学术话语。 1. 开展全面综述:我们对 LLMs、LVLMs 与 TVMs 中的幻觉成因进行了系统性综述。本综述采用跨模态交织的方式组织,而非僵化的任务划分,从而更好地识别不同系统间的共性失效模式。更为重要的是,我们将该综述建立在所提出的统一框架之上,并将幻觉成因追溯到模型生命周期中可识别的机制,从而实现更深层次、更完整的理解。 1. 凝练研究洞见与未来方向:我们基于综述总结出反复出现的主题,并提出未来研究方向。论文的整体结构见图 1,近期的理解尝试则展示于图 2。
通过提出统一定义与根因综述,我们希望能推动幻觉理解的深化,并支持开发更具普适性与有效性的解决方案,从而降低人工智能系统在现实应用中带来的风险。