视觉文档赋予文本丰富的多模态特征,如视觉特征、文本特征和布局特征等。视觉文档信息抽取旨在利用 视觉文档的多模态特征更好地从文档内容中提取结构化的关键信息,已逐渐成为自然语言处理和计算机视觉技术 的重要交叉领域,在商业、医疗、教育等行业应用广泛。随着深度学习技术的发展与突破,近期视觉文档信息抽取 发展迅速,研究方法大致可分为两类,一类是基于有监督学习的方法,包括基于图的方法、基于网格的方法、端到端 方法;另一类是基于自监督预训练和有监督微调的方法,逐渐成为主流的研究方向。该文概述了基于有监督学习 的三类方法,基于自监督预训练和有监督微调方法的四个方面以及一些常用的公开数据集,最后总结并展望了未 来可能的研究方向。
在人类社会的发展中,文字是表达信息的重要 方式,而文档是传递和组织这些文字信息的重要载 体。视觉文档则是一种赋予文字更多视觉和结构特 征的文档,通过设置文字版式、页面排版等方式,突 出其中的关键信息及联系。在商业、教育、医疗等领 域,视觉文档广泛存在,例如,收据、发票、合同、试 卷、诊单等,具有重要的业务价值。在处理这些视觉 文档时,需要从中提取指定的关键信息,过去信息提 取工作往往采用人工的方式完成,不仅耗时而且昂 贵。随着时代的发展,人们需要更加智能、高效的 方法。 视觉文档一般被认为具有 三 种 模 态 信 息:文 本、布局和视觉图像。文本信息表示文本的语言含 义,布局信息表示文本的空间位置和文档布局结构, 视觉图像信息如文本的颜色、字体、背景、标注等。 在研究和应用中,视觉文档常以扫描图像和照片的 形式出现,如图1所示,一般具有以下特点:①丰富 的文本样式,如不同的大小、字体和颜色,印刷或手 写格式等;②多种文档组件,由文本、表格、图像和 印章等内容组成;③ 多样文档结构,通过对齐、留 白、分割线等形成特定结构;④复杂图像背景,可能 含有褶皱或涂改痕迹,另外在拍摄、扫描获得图像时 常引入光照、角度等干扰。在视觉文档信息抽取商 业应用中,以上这些因素带来了巨大挑战,并使其成 为结合计算机视觉和自然语言处理多领域的多模态 任务,吸引着各大科技公司和高校深入研究。
简言之,视觉文档信息抽取(VisualDocument InformationExtraction,VDIE)是指从大量具有丰 富视觉信息的 文档内容中抽取实体及其关系的技 术[1]。与传统的信息抽取[2](InformationExtraction, IE)相比,IE以文字序列为输入,只需考虑文本模态 信息;而 VDIE则以视觉文档为输入,需综合考虑多 模态信息。21世纪初,视觉文档信息抽取方法主要 基 于 模 板 和 机 器 学 习,应 用 于 发 票 和 收 据 等 方 面[3-7],但效果欠佳。随着深度学习技术的成熟和突 破,近五年文档信息抽取技术发展迅速,基于深度学 习的视觉文档信息抽取方法涌现,而且具有以下优 点:①准确率高,满足商业应用要求;②适应性好, 可以处理多种类型的文档;③学习能力强,能够自 动提取多模态特征以提升信息抽取的性能;④拓展性强,能够通过增加数据量和模型规模进一步提高 方法的性能。基于深度学习的方法,通常使用计算 机视 觉 中 的 卷 积 神 经 网 络 (ConvolutionalNeural Network,CNN)提取视觉文档的图像特征,使用自 然语言处理中长短时记忆网络(LongShortTerm Memory,LSTM)等 循 环 神 经 网 络 (Recurrent NeuralNetwork,RNN)学习文本语言中的上下文 信息[8-9],使用注意力机制网络[10]挖掘多模态信息 之间的深层联系。 最近几年,预训练技术[11-12]在深度学习领域的 广泛应用,同样对文档领域产生了深刻影响。研究 人员利用海量堆积的无标记视觉文档,通过自监督 的预训练方式学习、理解其中的先验知识,并在有标 注的数据集上进行有监督学习的微调训练以提升 下游任务的性能。该方法 的 代 表 作 LayoutLM [13] 在视觉文档 信 息 抽 取 以 及 文 档 分 类、版 面 分 析 等 多个 下 游 任 务 上 表 现 优 异,并 启 发 了 许 多 后 续 研究。 综上,基于深度学习的方法可以大致分为两类: 一类是基于有监督学习的方法,在标注数据集上进 行训练和测试,主要包括基于网格的方法、基于图的 方法和端到端方法;另一类是日渐成为主流的基于 自监督预训练和有监督微调的方法,对大规模无标 记数据集进行自监督预训练并在下游标注数据集上 进行有监督微调。
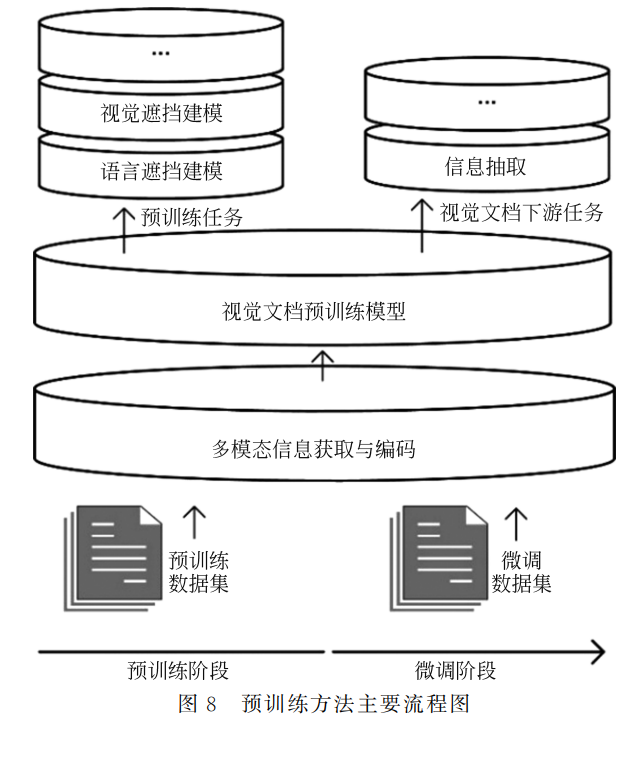
本文接下从以下几方面介绍该领域的发展。 第1节介绍基于有监督学习的方法,包括基于 网格的方法、基于图的方法和端到端方法。第2节 分析基于自监督预训练和有监督微调的方法,介绍 其中的四个方面:多模态信息获取与编码、预训练 模型、自监督预训练,以及视觉文档信息抽取的有监 督微调。第3节介绍视觉文档信息抽取领域常用的 一些公开数据集和评价指标。 最后总结并展望该领域未来可能的研究方向。
1 基于有监督学习的方法
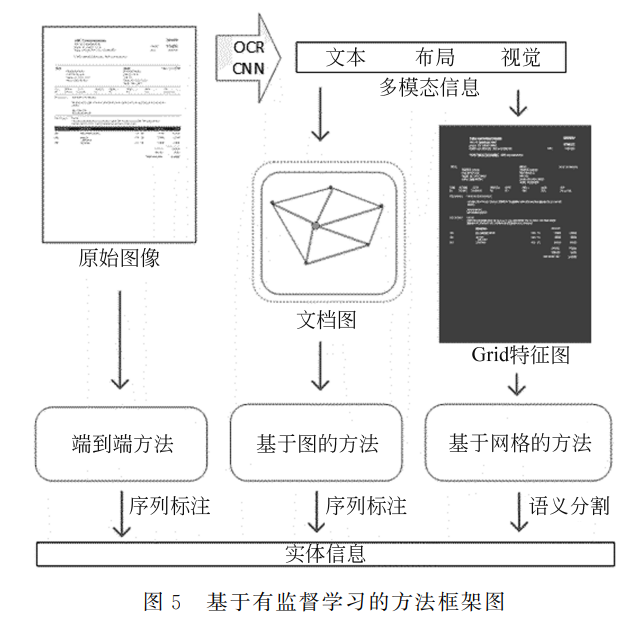
有监督学习指深度学习模型在人工标注的数据 样本上进行优化训练,是深度学习长期以来的一种 主流方法。基于有监督学习的视觉文档信息抽取方 法,主要有基于网格的方法、基于图的方法和端到端方法。
1.1 基于网格的方法
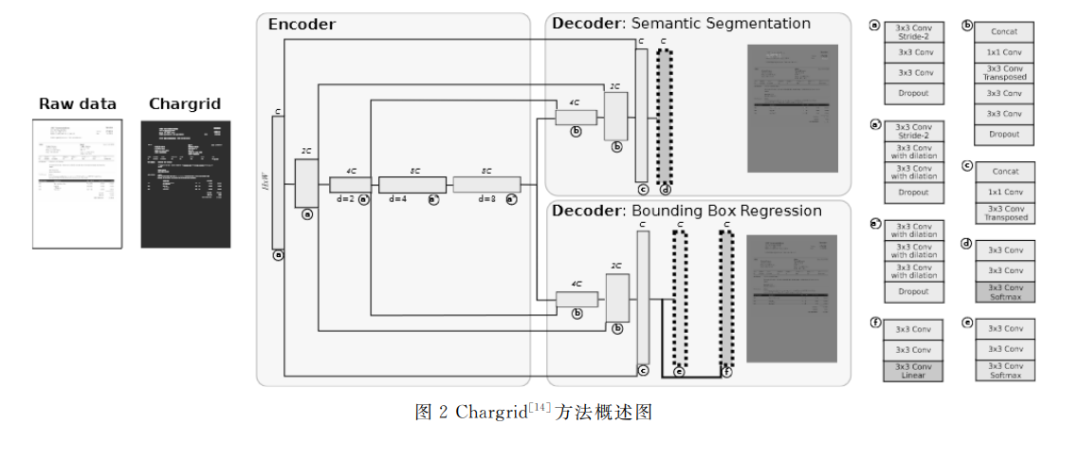
根据视觉文档的二维平面特性,有研究者提出 网格(Grid)的概念,将文档抽象为二维棋盘结构,将 相应位置文本的语言特征填充到格子中,使其不仅 在整体上保留了文本单元间的相对空间关系,而且 在局部上增强了网格元素的语义特征。 Chargrid [14]最早应用了网格特征图的概念,通 过光 学 字 符 识 别 (OpticalCharacterRecognition, OCR)获得字符和文本框信息,使用像素大小作为 网格尺寸,将字符的独热编码填入文本框区域网格 中,构建 Chargrid特征图。该方法使用如图2所示 的编码器/解码器网络学习 Chargrid特征图,以语 义分割的方式抽取特定信息。该网络具有两个相同 结构的解码器,其中一个解码器负责完成语义分割 任务,另一个解码器则学习文本框信息协助编码器。 为提升 Chargrid特征图的语义分割效果,Dang等 人[15]设计了多层 UNet编码器/解码器,结合注意 力机制,以更少的参数量达到了更好效果,同时证明 了 Chargrid特征图的有效性。
研究者认为增强网格元素的语义特征,有助于 提升 网 格 特 征 图 的 表 征 能 力。在 后 续 工 作 中, Wordgrid [16]使 用 了 词 特 征 嵌 入,BERTgrid [17]通 过 BERT模型在大量收据文本上进行预训练,进一步获 得并使用含有上下文信息的词嵌入特征。Cutie [18]降 低了网格特征图的复杂度,不再使用像素作为网格 单元,而是将粗粒度的文本块(Segment)映射到网 格中。这些增强网格语义特征的方法,都取得了性 能上的提升。 为进一步融合视觉图像信息,Visual-WordGrid [19] 首次将图像信息和网格特征结合,比 WordGrid [16] 具有一定性能提升。ViBERTgrid [20]则采用端到端 的方式,将生成特征图和信息抽取两个步骤做联合 训练以优化模型,降低了传统方法的误差积累;并在 推理阶段,不再以语义分割为信息抽取方法,而是直 接根据特征图区域解码特征和词嵌入进行词性分 类,大幅提高了基于网格方法的性能。 基于网格的方法更多地从计算机视觉的角度, 将深度学习技术应用于视觉文档信息抽取,以二维 平面形式对视觉文档及其多模态信息进行建模,面 对多种不同版式视觉文档的应用场景,比以往基于 规则和机器学习的方法具有更强的处理能力。
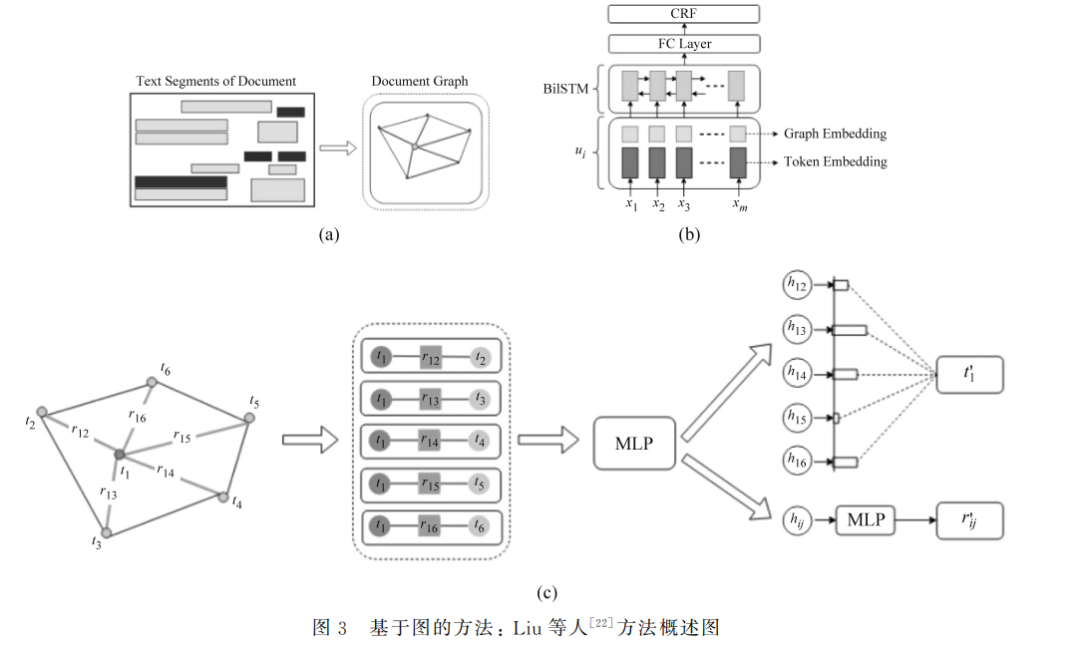
基于图(graph)的方法[21-27]对视觉文档构建图表 征,通过图卷积网络(GraphConvolutionalNetwork, GCN)更新图嵌入信息。图表征由节点(Node)和边 缘(Edge)组成,节点含有文本等模态信息,边缘一 般由布局位置信息确定并表示节点之间的连通性和 权重。 如图3(a)所示,Liu等人[22]通过文档图对文本 及其 空 间 布 局 关 系 进 行 建 模。它 首 先 以 文 本 块 (Segment)为单位初始化图节点信息,以文本框大 小距离初始化图边缘信息,然后如图3(c)所示以节 点-边缘-节点三元组为图卷积单元,着重更新交换 相邻节点间的文本信息。最后,如图3(b)所示,将 图嵌入和文本嵌入拼接作为 BiLSTM-CRF [28]提取 器的输入,通过 BIO 格式[29]抽取关键信息。其中 BIO 是一 种 常 见 的 序 列 标 注 格 式,指 BeginningInside-Outside,其将组成实体的多个词,分别打上 B、I、O 不同的标记。Liu等人[22]通过实验证明了图 结构对文本和布局信息表征的有效性,启发了后续工作。
现实中,视觉文档往往具有多层结构关系,传统 的 BIO 序列标记的信息抽取方式并不能很好地处 理这种层次关系。SPADE [24]使用实体间的关系矩 阵表示多层实体关系。它首先将实体信息融入文档 图表征,同时建立实体节点和文本节点间的序列和 层次两种边缘关系类型,再通过解码函数将关系矩阵转换为结构化json文本来获得实体信息,有效处 理了文本间的层次关系。 PICK [25]在 Liu等人[22]的工作基础上,在初始 化文档图节点时加入了视觉图像信息,将文本嵌入 与对应 区 域 的 视 觉 图 像 嵌 入 相 加。 通 过 实 验, PICK [25]取得了比 LayoutLM [13]更好的效果,说明 视觉信息能增强文档图结构的表征能力。 在发票、收据等半结构化视觉文档中,往往具有 明显的键值关系。MatchVIE [26]希望通过这种键值 关系来辅助纠正序列中的错误标记。该方法一方面 根据图表征模块预测文档内容中的键值关系,另一 方面通过序列标记模块预测实体信息,最终以键值关 系中的值辅助纠正最终的实体信息。MatchVIE [26]充 分利用了结构化视觉文档中的特点,与图表征结合, 提升了实体信息抽取的精度。 基于图的方法能充分利用视觉文档中的文本和 空间信息对文本信息建模,通过图卷积进行局部和 全局信息的交流,更加便于实体信息的预测;同时也 需要更仔细地考虑文档图的定义、节点和边缘的初 始化,图卷积学习过程以及如何使用学习后的图嵌 入优化信息抽取的效果等多个问题。
1.3 端到端方法
大部分基于深度学习的视觉文档信息抽取方 法,需要先使用 OCR 获得文本序列和文本框信息。 端到端方法[30-34]则跳过这一步骤,直接以视觉文档 图像为输入,输出实体信息,减少任务多个步骤导致 的误差积累。 EATEN [30]较早尝试了以端到端的方式完成信 息抽取,将 CNN 网络提取的文档视觉特征分别输 入到多个 RNN 解码器。每个解码器将根据图像标 记检测、识别和输出特定类型的实体信息。但该工 作没有利用文档中包含的文本语义,模型方法存在 改进的空间。 TRIE [31]则提出了一个统一的文本阅读和信息 抽取的网络,如图4所示。可以看出,该模型主要具 有三个模块,文本阅读模块负责检测、识别文本并获 得文本、视觉和布局特征,多模态上下文模块通过注 意力机制融合多个模态特征为多模态特征,信息抽 取模块则结合多模态特征与文本特征进行序列标 记,获得最终实体信息。其中,TRIE 将文本阅读模 块和信息抽取模块联合训练,使之相互增强,并以多 模态上下文模块衔接二者。实验表明,端到端的联 合训练一方面对信息抽取性能有明显提升,另一方 面 信 息 抽 取 的 速 度 也 获 得 了 大 幅 领 先,证 明 了 TRIE端到端方法的有效性和实用性。 VIES [32]同样采取联合训练文本检测识别模块 和信息抽取模块的方式,不过同时学习了词和字符 两种级别的布局、文本、视觉信息,不仅丰富了多模 态嵌入的信息,而且降低了单侧文本识别错误的影 响,提升了信息抽取模块的精度并反馈增强了文本 检测识别的性能。在实验中,VIES在文本检测、文 本 识 别 和 信 息 抽 取 多 个 环 节 上 的 表 现 都 优 于 TRIE [31],提高了端到端方法中的准确率、鲁棒性和 对复杂视觉文档的处理能力。
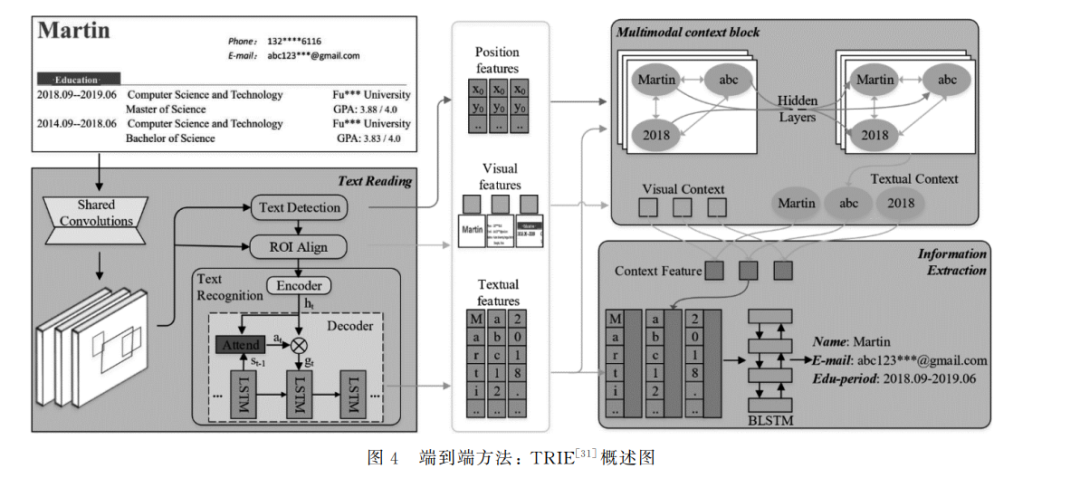
图5描述了三种方法的主要特点,从左到右来 看,基于端到端学习的方法直接使用原始文档图像 作为输入,基于图的方法和基于网格的方法则对文 档多模态输入构建不同的表征,一般通过序列标注 和语义分割等方式完成实体信息的抽取。三种方法 均以有监督学习的方式,将深度学习用于视觉文档 的信息抽取,比传统的基于规则的方法和机器学习 的方法,对标记数据的学习能力更强,性能更好,鲁 棒性更强,能更高效地处理多种类型的文档。
2 基于自监督预训练和有监督微调的方法
BERT [11]使用预训练技术,在多个自然语言处 理任务上同时取得大幅性能提升,证明了预训练技 术的有效性,使预训练技术在多个领域流行起来。 BERT的成功得益于大量数据、注意力机制模型、自 监督预训练,以及有监督微调,大量文本数据提供了 丰富的语义、语境和上下文等语言信息,注意力机制 模型提供了强大的长距离上下文学习能力及高效的 并行计算效率,自监督预训练则提供了利用海量无 标记数据的可行性,在下游任务的有监督微调则可 以大幅提高任务性能。视觉文档领域具有大量未经 标记的视觉文档数据,研究人员尝试应用自监督预 训练和有监督微调的处理范式,进一步提高各类文 档任务的性能。 预训练语言模型应用于视觉文档时,最早只关 注了文本信息,并未利用其中丰富的文本样式、版面 结构和布局信息,而这往往对文档理解非常重要。 2020年初,LayoutLM [13]提出了一种多模态预训练 模型,结合了视觉文档中的布局和视觉信息进行预 训练,在多个文档下游任务上取得了领先性能。从 而,基于自监督预训练和有监督微调的视觉文档方 法(后文简称预训练方法)开始被广泛研究,视觉文 档信息抽取研究进入了一个新的阶段。 如图6所示,LayoutLM [13]为了将预训练技术 与视觉文档多模态信息结合,首先通过 OCR 技术获得扫描文档图像的文本和布局信息,在训练阶段 将文本嵌入与布局嵌入相加作为预训练模型输入, 在微调阶段再加上对应区域的视觉图像特征送入下 游任务,如此实现了多模态信息的利用。布局嵌入 特征由文本框的四个坐标值通过线性变换获得,视 觉图像嵌入特征由 CNN 模块和全连接层获得,最 终送入预训练模型中学习。为了帮助模型在预训练 过程中能有效学习到视觉文档中的先验知识和多模 态特征的上下文语义,LayoutLM 在1100万张文 档图片上进行预训练,并设计了三个自监督预训练 任务,最终以序列标记的方式在视觉文档信息抽取 任务上进行微调。本节围绕视觉文档信息抽取,认 为 LayoutLM 方法中有四个关键的技术方面:多模 态信息获取与编码、预训练模型、自监督预训练、视 觉文档信息抽取的有监督微调方法。本节将从上述 四个技术方面介绍和分析预训练方法相关工作,最 后对预训练方法简单总结。