

机器学习系统在面对分布偏移时并不具备鲁棒性——当它们在与训练环境不同的环境中部署时,准确率会大幅下降。例如,当在新的国家部署卫星遥感模型、在新的医院部署肿瘤检测模型,或在新的森林中部署野生动物保护模型时,它们都会面临准确率大幅下降的问题。在这篇论文中,我们证明了基础模型范例是一个原则性的解决方案,可以达到最先进的鲁棒性。基础模型范例包括三个步骤:在多样化的无标签数据上预训练模型(例如,来自世界各地的卫星图像)以学习通用的表示,然后将这些模型适应到我们关心的下游任务,最后在真实世界中部署这些模型。这篇论文将专注于理解和改善这三个步骤以提高鲁棒性。(1) 首先,我们展示了在无标签数据上的预训练能学习到可迁移的表示,即使在我们没有标签的领域也能提高准确性。我们解释了为什么预训练能以与某些传统直观(领域不变性)完全不同的方式工作。我们的理论预测了真实数据集的现象,并导出了改善预训练方法的建议。(2) 接下来,我们将展示标准的适应方法(更新模型的所有参数)可能会扭曲预训练表示,并且在分布外表现不佳。我们的理论分析引导出了更好的适应方法,以及在ImageNet以及诸如卫星遥感、野生动物保护和放射学等应用中的最先进准确度。(3) 最后,当我们在现实世界中部署模型时,数据分布会随着时间的推移而变化,这会导致模型性能下降。我们展示了在模型自身预测上进行自训练可以提高对分布偏移的鲁棒性,并解释了在何时以及为何自我训练能够工作。
在过去的十年中,机器学习(ML)取得了快速的进展。在ImageNet [Deng等人,2009,Russakovsky等人,2015]这一最受欢迎的机器学习基准测试中,准确率已经从54% [Sanchez和Perronnin,2011,Krizhevsky等人,2012]上升到了超过90% [Pham等人,2021]。最先进的深度学习模型现在可以生成类似人类的文本,高精度地翻译语言,并从自然语言描述中编写代码 [Lewis等人,2020,Brown等人,2020,Chen等人,2021a]。快速的进展带来了快速的部署。机器学习模型现在被用于医学诊断 [Wong等人,2021],卫星遥感 [Xie等人,2016,Jean等人,2016,Hansen等人,2013],野生动物保护 [Beery等人,2020],以及警务 [Hill,2020]等诸多应用中。然而,一个关键的挑战仍然存在:ML模型不具备鲁棒性。ML模型在其训练数据上的表现良好,但是当在不同的数据上进行评估时,它们的准确度会大幅下降 [Recht等人,2019,Hendrycks和Dietterich,2019,Hendrycks等人,2020a]。当卫星遥感模型在新的国家部署,肿瘤检测模型在新的医院部署,或者野生动物保护模型在新的森林中部署时,它们都会面临准确度大幅下降的问题 [Jean等人,2016,Xie等人,2021a,Sagawa等人,2022]。这种缺乏鲁棒性在几乎所有的实际应用中都是一个重大问题。正式地说,我们从在来自分布Pid的标签数据集上训练的模型开始,我们称之为在分布数据。标准的ML基准测试是在同一分布Pid的未见过的样本组成的测试集上评估模型。但是当模型被部署时,会出现分布的偏移:模型需要对来自不同分布的数据Pid进行预测,我们称之为分布外数据。这里,Pood可能表示来自不同国家,医院或未来的数据。在实际应用中,从Pid到Pood的这种分布偏移是常态,因为部署环境通常与精心策划的训练数据不同。
尽管已有大量的先前工作和进展,但对分布偏移的鲁棒性问题仍然没有得到解决。现有的工作主要关注对小偏移的鲁棒性,但实际的偏移往往更大。有一系列的工作研究了对抗性样本[Szegedy等人,2014,Goodfellow等人,2015,Madry等人,2017,Raghunathan等人,2018],在这里,对手恶意地向图像添加一小部分不可察觉的噪声以欺骗模型的预测。另一线的工作研究了如重要性加权[Shimodaira,2000,Sugiyama等人,2007,Huang等人,2006],或者像H--H散度这样的距离度量[Ben-David等人,2010,Mansour等人,2009]等方法。这些方法要求训练分布(Pid)和部署分布(Pood)非常接近——例如,重要性加权假设Pid和Pood包含相同的样本,但比例不同。在实践中,分布偏移往往更大——例如,来自北美,欧洲和非洲的图像看起来非常不同,来自不同医院的数据通常看起来不同。还有许多其他的分布偏移方法,如CORAL [Sun和Saenko,2016],不变风险最小化 [Arjovsky等人,2019],和领域对抗训练[Tzeng等人,2014,Ganin和Lempitsky,2015],这些在某些情况下有用但在其他情况下不适用 [Gulrajani和Lopez-Paz,2020,Sagawa等人,2022]。对于这些方法何时以及为何有效的理解也有限 [Zhao等人,2019]。为了构建对分布偏移具有鲁棒性的模型,我们需要理解Pid和Pood可能如何相关。如果没有任何结构——如果Pood与Pid有任意的不同——那么在Pood上表现良好是不可能的。正如我们接下来将看到的,学习Pid和Pood之间关系的一个强大工具是利用包含这两种分布的多样化的无标签数据,例如来自互联网的图像或文本。
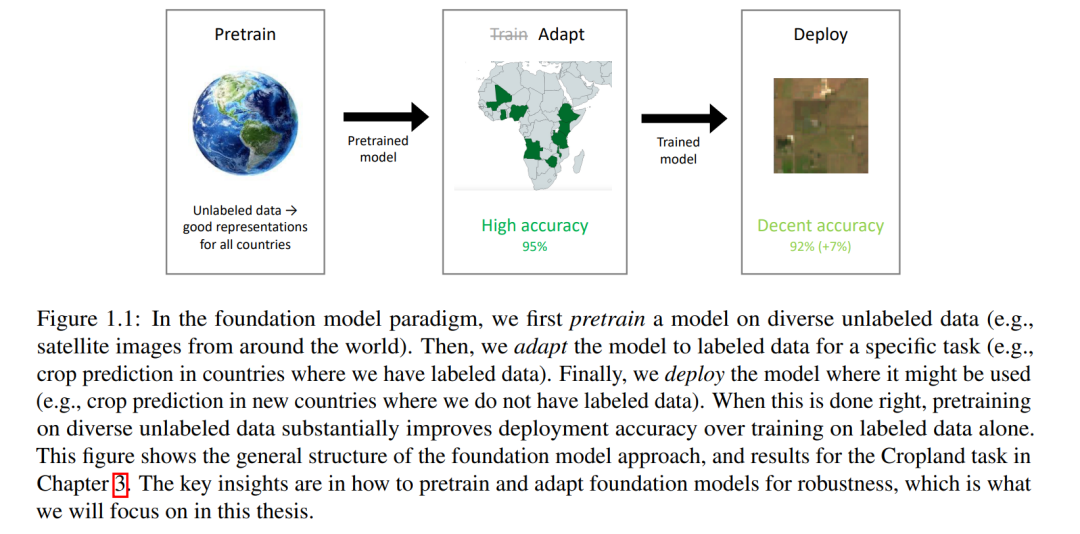
在这篇论文中,我们将展示基础模型范式——对多样化的无标签数据进行预训练,然后适应感兴趣的任务(图1.1)——是构建对分布偏移鲁棒的模型的最有希望的方式之一。我们将解释如何预训练鲁棒的基础模型,以及如何将它们鲁棒地适应特定任务。我们将展示预训练和适应基础模型所使用的算法和数据对于对分布偏移的鲁棒性至关重要。例如,在第4章中,我们将看到用于预训练模型的数据在其鲁棒性中起着关键作用,并且通常比预训练方法或损失的细节产生更大的影响。在第5章中,我们将展示适应基础模型的标准算法,全精调,因为它扭曲了预训练的表示而对分布偏移不鲁棒。我们将看到适应方法的选择至关重要,而有趣的是,它通常比预训练算法的选择产生更大的差异。利用我们的理论洞见,我们将找到更好的精调方法,大大提高模型的鲁棒性。这篇论文将建立一些首次理解预训练和适应正在学习什么的理论,通过引用和扩展理论概念(例如,谱图理论,随机矩阵理论,非凸优化)。然后,我们将把理论结果转化为改进的实际算法。我们的方法已经在ImageNet(最受欢迎的机器学习基准之一)以及卫星遥感,野生动物保护和放射学等应用中取得了最好的准确性。





