AAAI(AAAI Conference on Artificial Intelligence) 由国际先进人工智能协会主办,是人工智能领域的顶级国际学术会议之一。第39届AAAI人工智能年度会议将于2025年2月在美国宾夕法尼亚州费城召开。本文将介绍自动化所在本届大会上的录用成果。

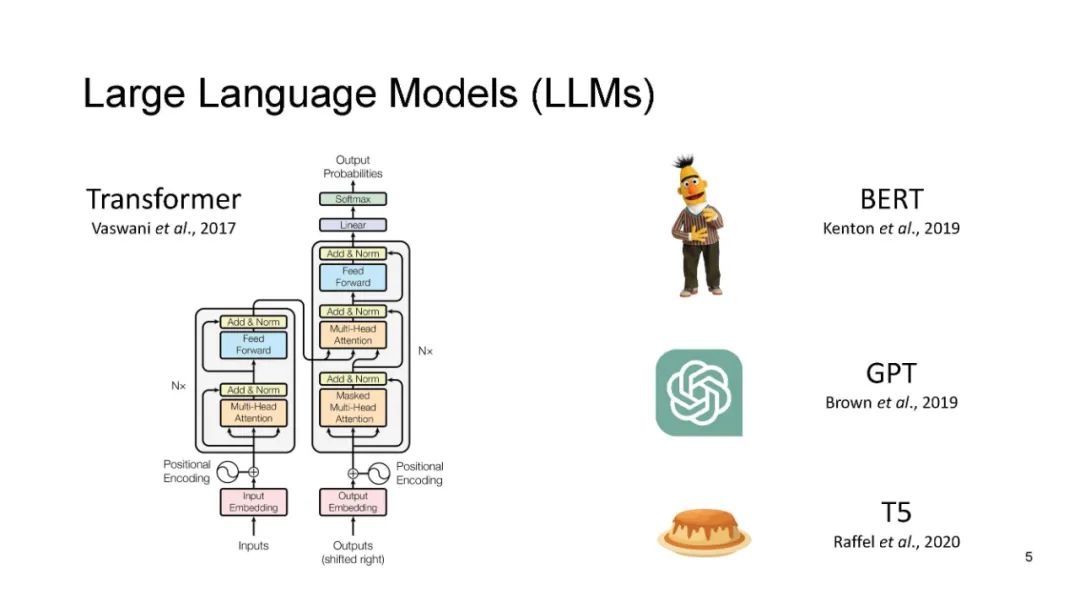
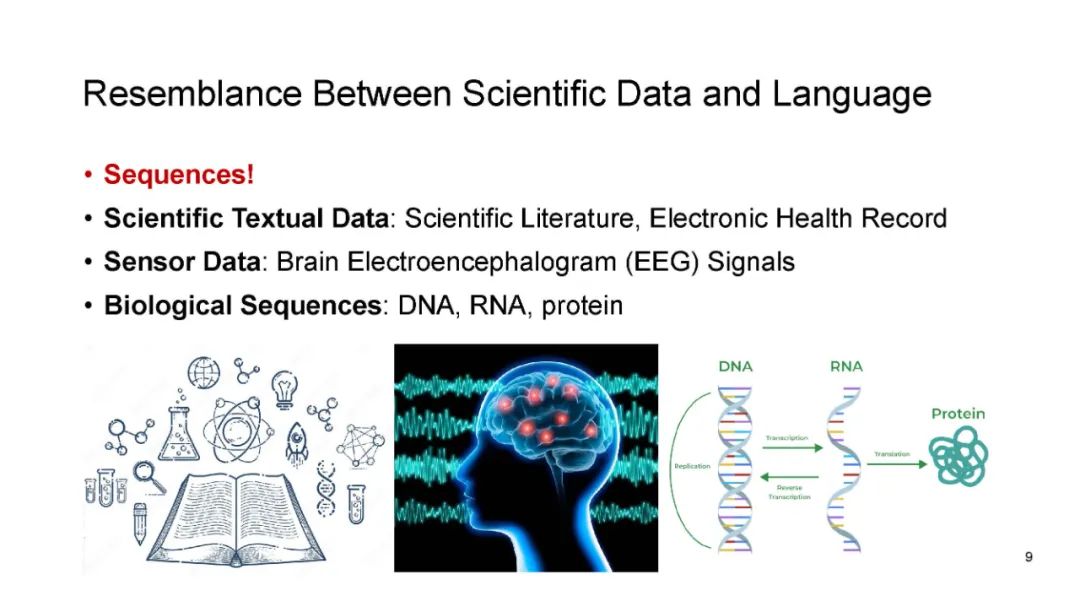
人工智能在科学领域的应用涵盖了广泛的范围,从原子层面,解决量子系统的偏微分方程,到分子层面,预测化学或蛋白质结构,甚至扩展到像传染病爆发这样的社会预测。近年来,大型语言模型(LLMs)取得了显著的进展,诸如ChatGPT等模型在涉及自然语言的任务中表现出了强大的能力,例如语言翻译、构建聊天机器人和回答问题。当我们考虑科学数据时,我们会注意到它们在序列上与自然语言有相似之处——如以文本呈现的科学文献和健康记录、按序列排列的生物组学数据,或像脑电信号这样的传感器数据。问题随之而来:我们能否利用这些最新LLMs的潜力推动科学进步?在本教程中,我们将探讨大型语言模型在科学数据三大关键类别中的应用:1)文本数据,2)生物医学序列,3)脑电信号。此外,我们还将深入探讨LLMs在科学研究中的挑战,包括确保可信度、实现个性化和适应多模态数据表示。

Xuan Wang 是弗吉尼亚理工大学计算机科学系的助理教授。她的研究兴趣包括自然语言处理、数据挖掘、科学中的人工智能以及医疗保健中的人工智能。她目前的研究方向包括基于有限监督的自然语言理解、大型语言模型的复杂推理与规划,以及通过多模态科学基础模型推动科学发现。她曾获得2025年思科研究奖、2024-2025年NSF NAIRR试点奖以及2021年NAACL最佳演示论文奖。她分别于2022年、2017年和2015年在伊利诺伊大学香槟分校获得计算机科学博士学位、统计学硕士学位和生物化学硕士学位,并于2013年获得清华大学生物科学学士学位。她曾在IEEE-BigData 2019、WWW 2022、KDD 2022和EMNLP 2024等会议上举办教程。
人工智能(AI)在科学领域的卓越能力涵盖了广泛的范畴,从原子层面(如尝试求解量子系统的偏微分方程)到分子层面(如精准预测化学物质和蛋白质的结构),甚至延伸到社会预测(如预测传染病爆发)(Zhang et al., 2023a)。在这一充满可能性的背景下,大语言模型(LLMs)的最新进展,尤其是以ChatGPT为代表的模型,已崭露头角,展示了在自然语言相关任务中的显著能力。这些任务包括语言翻译、构建聊天机器人和回答问题(Yang et al., 2023)。有趣的是,当我们将注意力转向科学数据时,会发现其与自然语言在序列形式上有着惊人的相似性。科学文献和健康记录以文本叙述的形式呈现,生物组学数据表现为分子序列,甚至像脑信号这样的传感器数据本质上也是序列化的(Wang et al., 2021a; Thirunavukarasu et al., 2023)。这一观察引发了一个引人深思的问题:我们能否利用这些先进的大语言模型的潜力来推动科学进步?在本教程中,我们将踏上探索这一交叉领域的旅程——将尖端的大语言模型与科学研究相结合。我们的探索聚焦于三类关键的科学数据:1)文本数据(Alsentzer et al., 2019; Singhal et al., 2022; Beltagy et al., 2019; Lee et al., 2020; Gu et al., 2021; Alrowili and Vijay-Shanker, 2021; Yasunaga et al., 2022),2)生物医学序列(Ji et al., 2021; Zvyagin et al., 2022; Fishman et al., 2023; Dalla-Torre et al., 2023; Nguyen et al., 2023; Yamada and Hamada, 2022; Yang et al., 2022; Chen et al., 2022; Zhang et al., 2023b; Rives et al., 2021; Bepler and Berger, 2021; Brandes et al., 2022; Madani et al., 2023; Lin et al., 2023; Zheng et al., 2023; Xu et al., 2023),以及3)脑信号(Wang et al., 2022a; Wang and Ji, 2022; Tang et al., 2023)。通过借鉴大语言模型的变革性能力,我们试图在每个领域中揭示新的理解和创新。随着教程的深入,我们还将讨论将AI融入科学研究过程中伴随的复杂挑战。可信赖性是其中至关重要的一点——我们如何确保AI增强的科学洞察力的可靠性?个性化的概念也成为一个关键考量,促使我们根据科学研究的特定需求定制大语言模型。此外,科学数据的多维度特性要求我们掌握处理跨模态数据表示的艺术。
教程大纲
本教程预计时长为3小时,中间包含30分钟的休息时间。
内容大纲如下:
1 背景与动机 [20分钟]我们将首先介绍大语言模型(LLMs)的背景知识以及“科学人工智能”(AI for Science)的整体概况。随后,我们将围绕三类关键科学数据(1)文本数据,(2)生物医学序列,以及(3)脑信号,激发对大语言模型在科学领域应用的兴趣。
2 大语言模型在科学文本数据中的应用 [40分钟]首先,我们将介绍大语言模型在科学文本数据中的应用。科学文本数据涵盖多个领域,例如生物医学文献(Beltagy et al., 2019; Lee et al., 2020; Gu et al., 2021; Alrowili and Vijay-Shanker, 2021; Yasunaga et al., 2022)和电子健康记录(Alsentzer et al., 2019; Singhal et al., 2022)。这类数据与大语言模型的基本结构高度契合,广泛应用于科学和医疗领域,支持信息提取(Wang et al., 2021b; Zhong et al., 2023; Wang et al., 2022b)和问答任务(Krithara et al., 2023)。
3 大语言模型在生物医学序列中的应用 [60分钟]接下来,我们将探讨大语言模型在复杂的生物序列数据中的应用。这一领域充满可能性,我们重点关注以下三类相互交织的生物序列:DNA序列:从生命的蓝图出发,我们深入研究了(Ji et al., 2021)、(Zvyagin et al., 2022)、(Fishman et al., 2023)、(Dalla-Torre et al., 2023)和(Nguyen et al., 2023)等开创性工作。这些研究为解密生物体本质中的秘密铺平了道路。DNA大语言模型在下游任务中应用广泛,例如从DNA序列中预测调控元件(如增强子、启动子、表观遗传标记和剪接位点)(Grešová et al., 2023; Dalla-Torre et al., 2023)。RNA序列:在基因表达的复杂世界中,我们借鉴了(Yamada and Hamada, 2022)、(Yang et al., 2022)、(Chen et al., 2022)和(Zhang et al., 2023b)等创新成果。这些进展帮助我们解码由RNA调控的生物过程。RNA大语言模型在RNA结构与功能预测(Yamada and Hamada, 2022; Zhang et al., 2023b)、RNA-蛋白质相互作用预测(Chen et al., 2022)以及细胞类型注释(Yang et al., 2022)中应用广泛。蛋白质序列:进入蛋白质的复杂领域,我们参考了(Rives et al., 2021)、(Bepler and Berger, 2021)、(Brandes et al., 2022)、(Madani et al., 2023)、(Lin et al., 2023)、(Zheng et al., 2023)和(Xu et al., 2023)等重要研究。这些研究揭示了分子功能与相互作用的复杂机制。蛋白质大语言模型在功能性蛋白质生成(Leinonen et al., 2004)和蛋白质结构预测(Suzek et al., 2015)中具有广泛应用。在这些领域中,大语言模型的变革性能力体现在众多高影响力的下游应用中。从预测分子结构到预测分子相互作用,从揭示分子功能到与疾病进展过程建立关联,大语言模型作为创新的灯塔,引导我们更深入地理解生命的基石。4 大语言模型在脑信号中的应用 [30分钟]最后,我们将探讨大语言模型在脑信号领域的迷人应用。本节首先介绍一种开创性的预训练脑信号表征模型(Wang et al., 2022a)。在此基础上,我们进一步探讨一个激动人心的主题——开放式词汇脑信号到文本的翻译(Wang and Ji, 2022; Tang et al., 2023)。这一研究旨在训练翻译模型,自动解读个体思维中的复杂内容,为技术与认知过程的潜在融合提供了引人入胜的视角。
**4.5 未来研究方向 [30分钟]**作为总结,我们将深入探讨将AI应用于科学研究中的挑战。其中一个重要挑战是确保AI增强的科学洞察力的可靠性和可信度,包括模型的可解释性、对抗攻击的鲁棒性、对不同人群的模型偏见以及数据隐私问题。我们还将探讨个性化的概念,即根据不同的个性化数据调整大语言模型。例如,不同人在相同语境下思考同一个词时,脑信号存在显著的个体差异。我们能否基于不同人的脑信号模式构建个性化的大语言模型,而非使用单一模型适应所有人?此外,科学信息的多样性要求我们掌握高效处理多类型数据的技能。例如,谷歌发布的Med-PaLM-2(Singhal et al., 2023)整合了电子健康记录中的图像、文本和基因组数据,展示了专家级的医学问答能力。我们能否开发更高效的方法,将多模态和多组学的大语言模型整合为一个强大的统一模型?