

近年来,计算机视觉和机器学习系统有了显著改善,这主要是基于深度学习系统的发展,从而在目标检测任务上取得了令人印象深刻的性能。理解图像内容则要困难得多。即使是简单的情况,如 "握手"、"遛狗"、"打乒乓球 "或 "人们在等公交车",也会带来巨大的挑战。每种情况都由共同的目标组成,但既不能作为单一实体进行可靠的检测,也不能通过其各部分的简单共同出现进行检测。
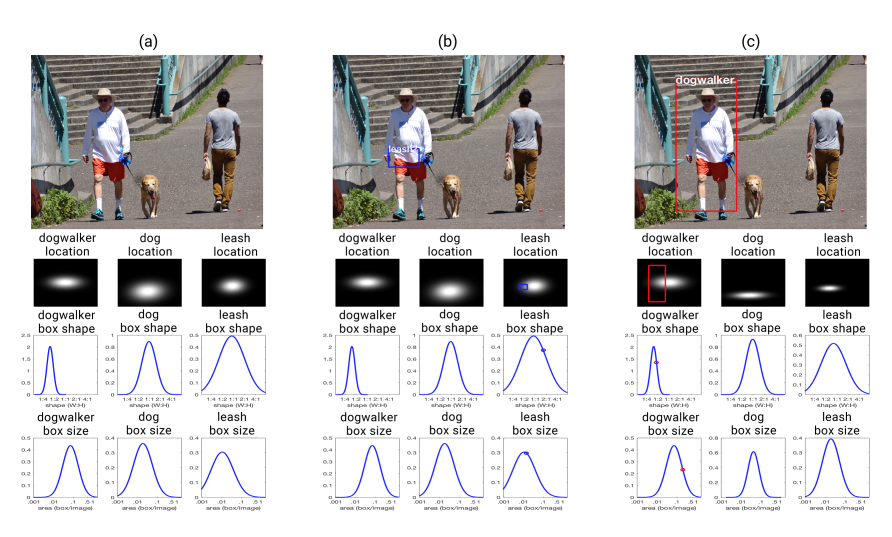
这篇论文将描述一个用于进行视觉情境识别的新型系统,其目标是开发能够展示与理解相关特性的机器学习系统。该系统被称为 Situate,它能在给出情况描述和少量标注训练集的情况下,学习目标外观模型以及捕捉情况预期空间关系的概率模型。给定一张新图片后,Situate 会利用其学习到的模型和一系列智能体对输入内容进行主动搜索,以找到情况模型与图片内容之间最一致的对应关系。每个智能体都会开发模型与输入内容之间可能存在的对应关系,而 Situate 会为智能体分配计算资源,以便尽早开发出有希望的解决方案,但也不会忽略其他对应关系。
将把 Situate 与更传统的计算机视觉方法(该方法依赖于检测情境中的组成目标)以及基于 "场景图 "的相关图像检索系统进行比较。将在情境识别任务和图像检索中对每种方法进行评估。结果表明了图像内容和该内容模型之间的反馈系统的价值。
成为VIP会员查看完整内容
相关内容

Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日




相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
152+阅读 · 2023年3月29日