

隐私保护机器学习是一个保持ML数据匿名和安全的实用指南。您将了解不同隐私保护技术背后的核心原理,以及如何将理论应用到您自己的机器学习中。
https://www.manning.com/books/privacy-preserving-machine-learning
复杂的隐私增强技术通过面部识别、云数据存储等实际用例被揭开了神秘面纱。除了技术实现技能,您还将了解当前和未来的机器学习隐私挑战,以及如何使技术适应您的特定需求。当你完成的时候,你将能够创建机器学习系统,在不牺牲数据质量和模型性能的情况下保护用户隐私。
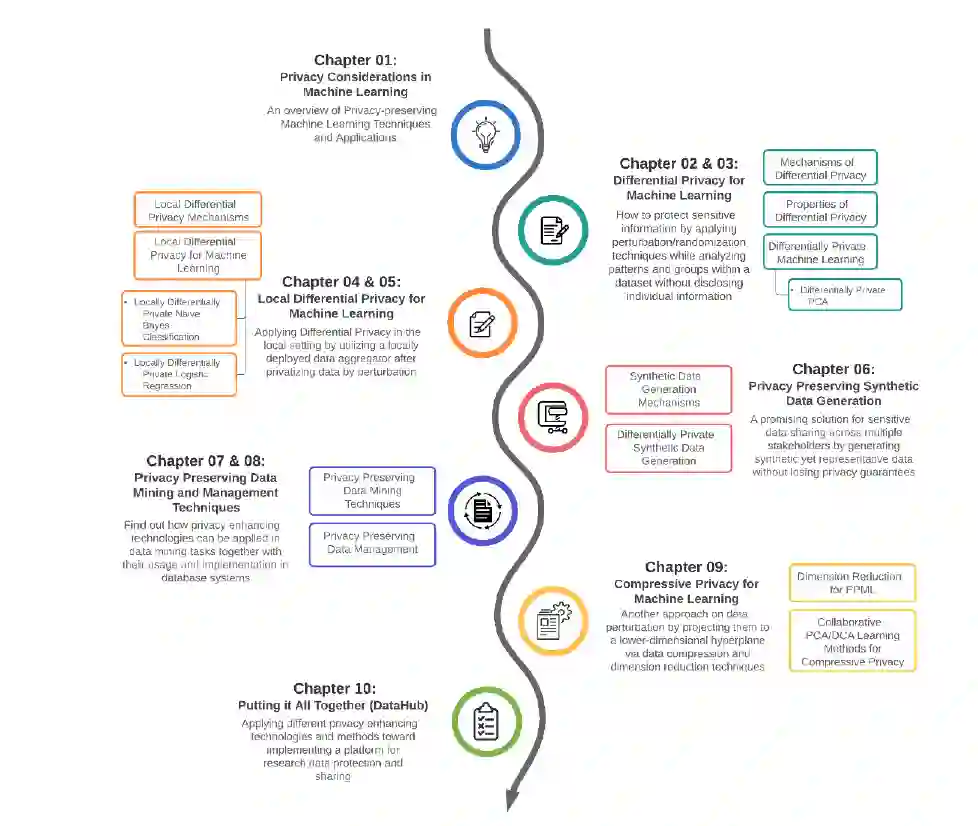
本书接下来的章节结构如下。第2章和第3章将讨论差分隐私如何在不同的用例场景和应用中用于保护隐私的机器学习。如果您有兴趣了解如何在实际应用程序中使用DP以及一组真实的示例,那么您已经了解了。在第4章和第5章中,我们将介绍在本地设置中应用差分隐私的方法和应用,但增加了限制,即即使攻击者获得了单个响应,也仍然无法了解其他内容。
第6章将研究如何在PPML范式中使用合成数据生成技术。正如我们已经讨论过的,合成数据生成在机器学习社区中越来越受欢迎,特别是作为机器学习模型的训练和测试的替身。所以,如果你有兴趣找到方法和方法来生成合成数据,以保护机器学习的隐私,这是你的章节。同时,在第7章和第8章中,我们将了解如何在数据挖掘任务中应用隐私增强技术,以及它们在数据库系统中的使用和实现。我们都知道,最终,所有东西都必须存储在数据库中的某个地方,无论数据模型是关系型、NoSQL还是NewSQL。如果这些数据库或数据挖掘应用程序在访问或发布数据时容易受到隐私攻击,该怎么办?这两章将调研不同的技术、方法和完善的行业实践,以减轻这种隐私泄露。
接下来,我们将研究PPML的另一种可能方法,通过将数据投影到另一个超平面来压缩或降低数据的维数。为此,我们将在第9章讨论不同的压缩隐私方法及其应用。如果您正在为具有压缩数据的受限环境设计或开发隐私应用程序,我们建议您在本章投入更多时间。我们将为您介绍数据压缩技术的实际示例,以实现针对不同应用程序场景的隐私保护。最后,在本书最后的第10章中,我们将通过强调设计挑战和实现考虑,把所有内容放在一起,设计一个研究数据保护和共享的平台。

- 在重构攻击中,对手获得了外部知识的特征向量或用于构建ML模型的数据的优势。
- 重构攻击通常需要直接访问部署在服务器上的ML模型;我们称之为白盒访问。
- 有时,当用户提交新的测试样本和模型为给定样本生成的响应时,对手可以监听机器学习模型的传入请求,这可能导致模型反转攻击。
- 成员推理攻击是模型反转攻击的扩展版本,攻击者试图基于ML模型输出推断样本,以确定样本是否在训练数据集中。
- 即使数据集是匿名化的,对一个系统来说,可靠地保护数据隐私是一个挑战,因为攻击者可以利用后台知识推断数据,通过去匿名化或重新识别攻击。
- 将不同的数据库实例连接在一起,以探索个人的独特指纹,这是数据库系统中重大的隐私威胁之一。
- 差分隐私(DP)旨在通过在统计数据或聚合数据中添加随机噪声,保护个人的敏感信息免受针对个人统计数据或聚合数据的任何推断攻击。
- 本地差异隐私(LDP)是DP的本地设置,个人通过扰动将数据私有化后将数据发送到数据聚合器,因此,为个人提供了合理的推诿。
- 压缩隐私(CP)通过压缩和降维技术将数据投影到低维超平面,从而干扰数据。
- 合成数据生成是一种很有前途的数据共享解决方案,它生成和共享与原始数据格式相同的合成数据集,这为数据用户使用数据提供了更大的灵活性,而不用担心基于查询的隐私预算。
- 有不同的方法来实现隐私保护数据挖掘(PPDM),这些技术可以分为三大类:数据收集的隐私保护方法,数据发布,和修改数据挖掘输出。


