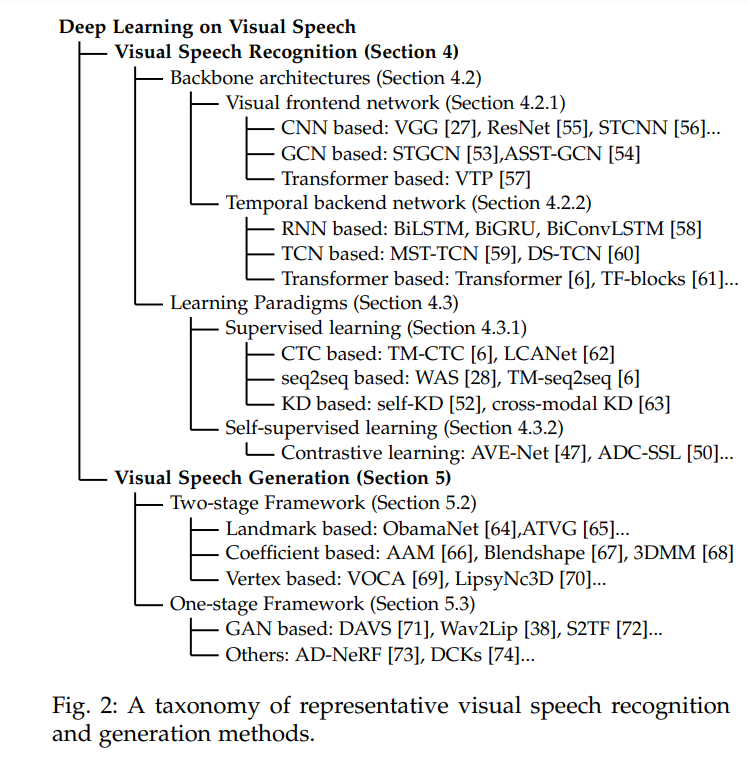
国防科大最新《深度学习视觉语音分析》综述论文,值得关注!

视觉语音,即语音的视觉领域,因其在公共安全、医疗、军事防御、影视娱乐等领域的广泛应用而受到越来越多的关注。深度学习技术作为一种强大的人工智能策略,广泛地推动了视觉语音学习的发展。在过去的五年中,许多基于深度学习的方法被提出来解决这一领域的各种问题,特别是视觉语音的自动识别和生成。为了进一步推动视觉语音的研究,本文对视觉语音分析中的深度学习方法进行了综述。我们涵盖了视觉语音的不同方面,包括基本问题、挑战、基准数据集、现有方法的分类和最先进的性能。此外,我们还指出了现有研究的不足,并对未来的研究方向进行了探讨。
引言
人类的语言本质上是双峰的: 视觉和听觉。视觉语言是指语言的视觉领域,即在说话[1]时自然产生的嘴唇、舌头、牙齿、下颚等面部肌肉的运动,而音频语言是指说话者发出的声学波形。语言感知本质上是双峰的,正如几十年前著名的McGurk效应[2]所表明的那样,人类的语言感知不仅依赖于听觉信息,还依赖于像嘴唇运动这样的视觉线索。因此,毫无疑问,视觉语言有助于人类的语言感知,特别是对于听力受损或听力困难的人,或当听觉信息被破坏时。
自动视觉语音分析(VSA)作为计算机视觉和多媒体领域的一个基础性和挑战性课题,近年来受到越来越多的关注,因为它在各种应用中发挥着重要的作用,其中许多应用是新兴的。VSA包括两个基本的密切相关的形式双重问题: 视觉语音识别(VSR)或唇读,视觉语音生成(VSG)或唇序列生成。由于近年来深度学习的蓬勃发展,这一领域已经取得了重大进展。典型的学术界和实际应用包括多模态语音识别和增强、说话人识别和验证[3]、医疗救助、安全、取证、视频压缩、娱乐、人机交互、情感理解等[4,5]。 举一些应用实例,在语音识别和增强中,可以将视觉语音作为互补信号处理,以提高当前音频语音识别和分离在各种不利声学条件下的准确性和鲁棒性[6,7,8,9]。在医学领域,解决VSR任务也可以帮助听力受损的[10]和声带病变的人。在公安领域,VSA可用于人脸伪造检测[11]和活体检测[12]。在人机交互中,视觉语音可以作为一种新型的交互信息,提高交互的多样性和鲁棒性[13,14]。在娱乐领域,VSG技术在虚拟游戏中个性化的3D说话头像生成[15],以及在电影后期如视觉配音[16]中实现高保真真实感的说话视频生成等方面发挥着至关重要的作用。此外,VSR可以用来转录无声电影档案。
VSA的核心是视觉语音表示学习和序列建模。在传统VSA方法为主的时代,视觉语音的浅层表示如visemes[17,18]、口型几何描述符[19]、线性变换特征[20]、统计表示[21]、序列建模如高斯过程动力学模型[22]、隐马尔可夫模型(hmm)[23]、决策树模型[24]被广泛应用于解决VSA任务。自从深度神经网络(DNNs)[25]在图像分类任务中取得重大突破以来,大多数计算机视觉和自然语言问题都明确地集中在深度学习方法上,包括VSA。2016年,基于深度学习的VSA方法[26,27]的表现大大超过了传统方法,使VSA进入了深度学习时代。同时,大规模VSA数据集的出现[27,28,29,30,31]推动了基于深度学习的VSA研究的进一步发展。在本文中,我们主要研究基于深度学习的VSA方法。VSA技术从2016年到现在的里程碑如图1所示,包括具有代表性的深度VSR和VSG方法以及相关的视听数据集。
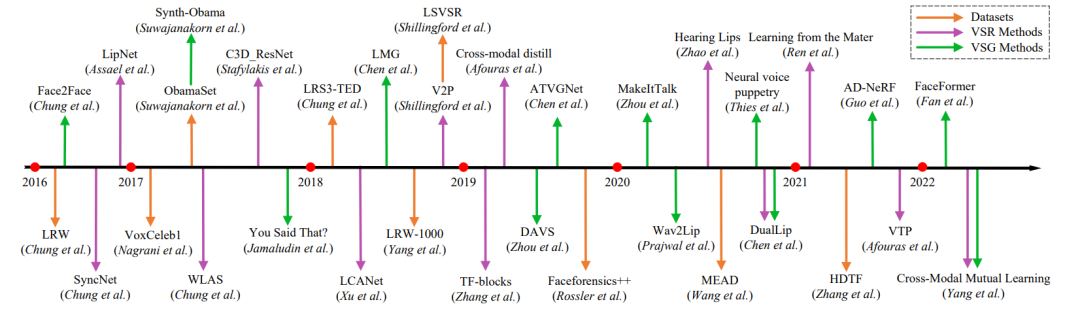
图1 从2016年到现在视觉语音分析的时间里程碑,包括代表性的VSR和VSG方法,以及视听数据集。手工制作的特征工程方法一直占据着VSA的主导地位,直到2016年相关深度网络的引入才发生了转变。
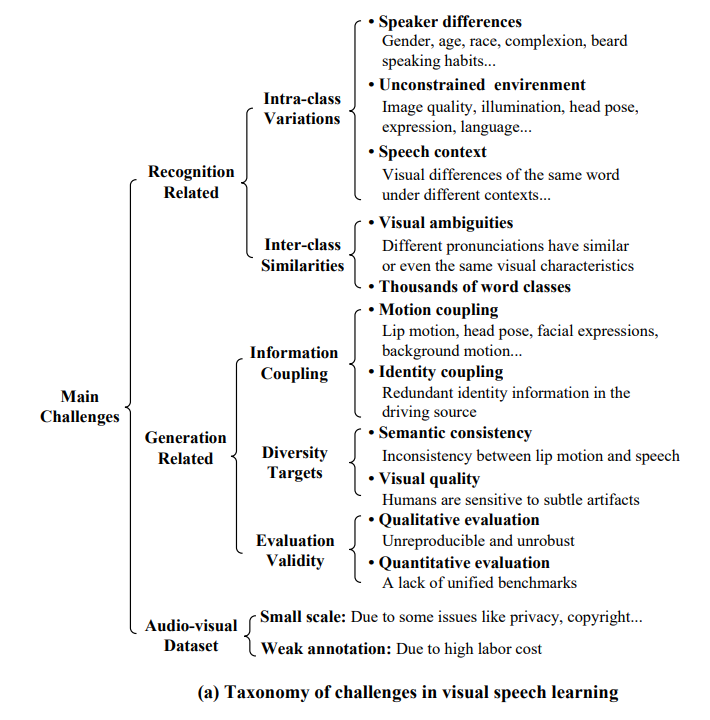
尽管在过去的几年中,深度学习带来了一些有希望的进展,但VSA技术仍处于早期阶段,无法满足实际应用的要求。这当然不是由于研究人员的努力不足,因为已经有许多关于VSA的优秀工作[6,28,32,33,34,35]。因此,系统地回顾该领域的最新发展,识别阻碍其发展的主要挑战和开放问题,并确定有希望的未来方向是非常重要的。然而,VSA研究的大部分仍然相当分散,没有这样的系统性综述。
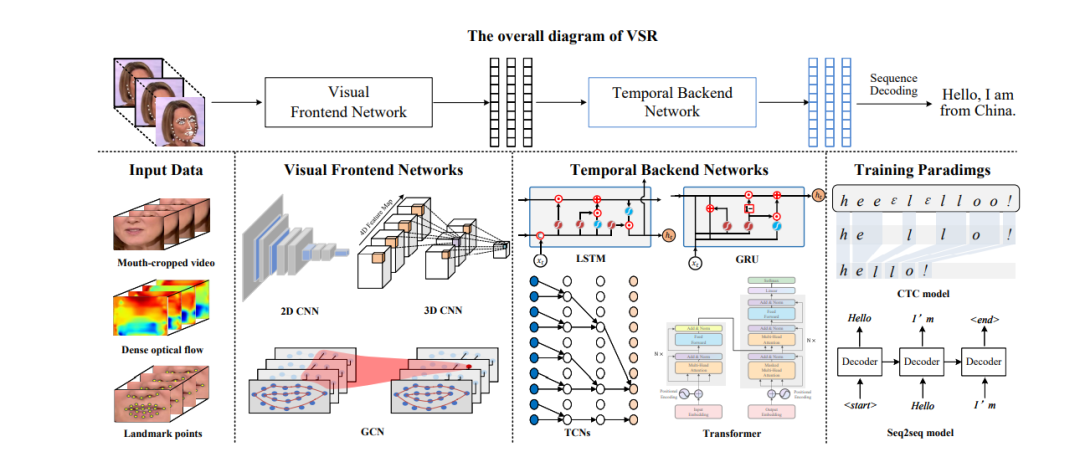
本综述的主要目的是全面概述当前基于深度学习的VSA方法,特别是VSR和VSG及其相关应用、主要挑战、基准数据集、方法和最先进(SOTA)结果,以及现有的差距和未来的研究方向。我们把VSR和VSG综合起来进行概述,主要有三个原因。首先,VSR和VSG作为VSA中最基本的问题,涵盖了视觉语音分析的大部分方面。其他与VSA相关的任务,如语音增强、说话人验证、人脸伪造检测等,都可以看作VSR和VSG的扩展应用。第二,由于VSR和VSG是形式化对偶的,并且相互促进,因此二元学习[36]和生成式对抗学习[37]在现有的许多VSA著作中被广泛采用[32,38,39,40,41]。因此,我们打算提供一个侧面的视角,让读者了解VSR和VSG的演变。第三,VSR和VSG具有共同的核心技术要点,如视觉语音表示学习方法和上下文序列建模方法。我们希望这将有助于读者对这些方法的跨任务可转移性有一个可理解的理解。
现在我们可以总结我们在本文中的主要贡献。
-
据我们所知,这是第一个系统全面地回顾了视觉语音分析的深度学习方法的综述论文,涵盖了两个基本问题,即视觉语音识别和视觉语音生成。
-
针对每个问题总结了问题定义、主要挑战、基准数据集和测试协议,值得注意的是,还确定了不同VSA问题之间的关系。
-
我们提出了一个分类法来对主要方法进行分组。此外,还分析了代表性方法的性能比较、优缺点及其内在联系。
-
提供了该领域的开放问题和有前途的方向。