
**导读:**本次分享的题目是图表示学习技术在药物推荐系统中的应用。
主要包括以下四个部分:
研究背景与挑战 * 判别式药品包推荐 * 生成式药品包推荐 * 总结与展望
分享嘉宾|郑值 中科大 博士研究生
编辑整理|王丽颖 360 出品社区|DataFun
01
研究背景与挑战
1. 研究背景
- 医疗资源总体不足,分布不均带来沉重压力
药物推荐是智慧医疗的一个子问题,首先从智慧医疗的大背景说起,在我国智慧医疗存在紧迫性,随着人口增长、老龄化加剧,人们对于高质量医疗服务的需求不断攀升。图中两组数据,一是全国医疗机构的就诊人数在 60.5 亿人次,同比增长 22.4%;二是柳叶刀上关于各国医疗卫生条件统计,我国医生大学本科以上学历仅 57.4%,包括医生、护士、社区卫生工作者等 16 类卫生工作职业的每万人从业者数量上,中国仅达到美国的 1/3 。我国的诊疗人数不断攀升,但医疗资源和医疗水平相对于发达国家还有较大的不足,此外还存在着医疗资源分配不均的问题。基层医疗机构的医疗水平相对有限,而顶层机构是供不应求的。因此如何充分利用高水平医疗机构的诊疗经验,协助提升基层医疗机构的医疗水平,是一个亟待解决的重要问题。
- 智慧医疗,人工智能技术带来了曙光
随着近些年医疗机构数字化进程加快,我国大量的医疗机构尤其是三甲医院等高水平医疗机构都已经积累了非常丰富的电子病历数据。如果能够利用大数据人工智能技术,充分挖掘此信息并提取相关知识,则有可能帮助我们理解这些高水平机构中医疗专家的一些诊疗方式和思想,进而支撑智慧复诊、医疗影像分析、慢性病随访等一系列的下游智慧医疗的应用,这些具有显著的意义。2. 研究挑战当下越来越多的医疗 AI 技术正在取得更加广泛的应用,也推动了医疗服务的公平化和普惠化。部分 AI 技术如医疗影像分析等已经取得了一些令人瞩目的成果,但在药品推荐系统中却存在较少应用,原因是药品推荐系统和传统的推荐系统有着非常大的差别,技术上也存在着诸多的难点。
- 包推荐系统
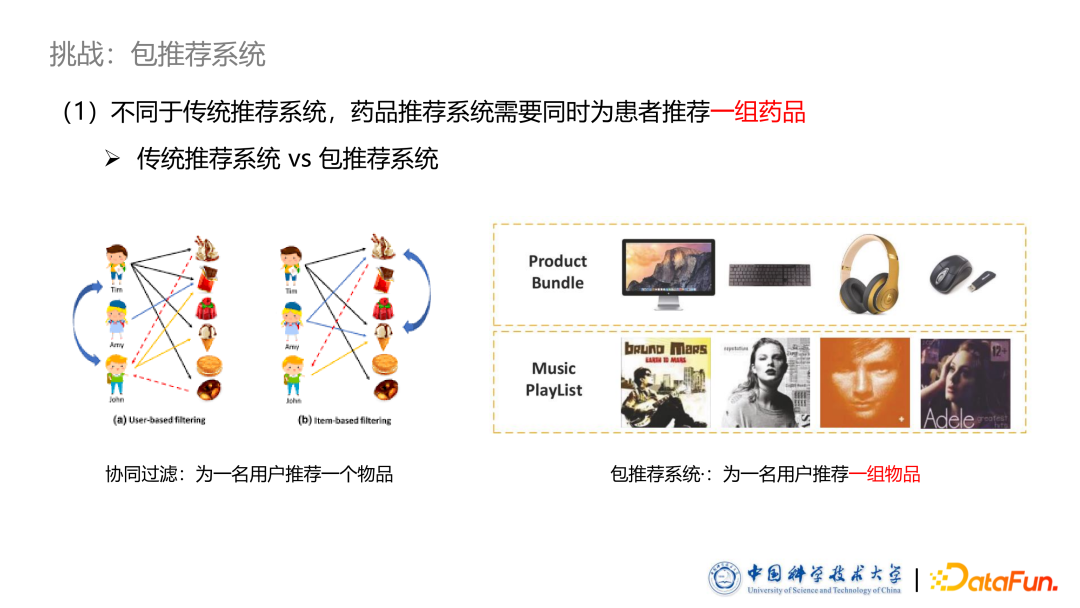
第一个挑战是传统基于协同过滤等方法的推荐系统的应用场景主要是一次为一名用户推荐一个物品,他们的输入是单个物品和单个用户的表示,输出的是二者之间的匹配程度打分。然而在药品推荐中,医生往往需要一次为患者开出一组药品。药品推荐系统实际上是一个包推荐系统,叫做 package recommendation system,同时为一个用户推荐一组药品。如何结合包推荐系统进行药品推荐,是我们面临的第一个大挑战。
- 药品间相互作用
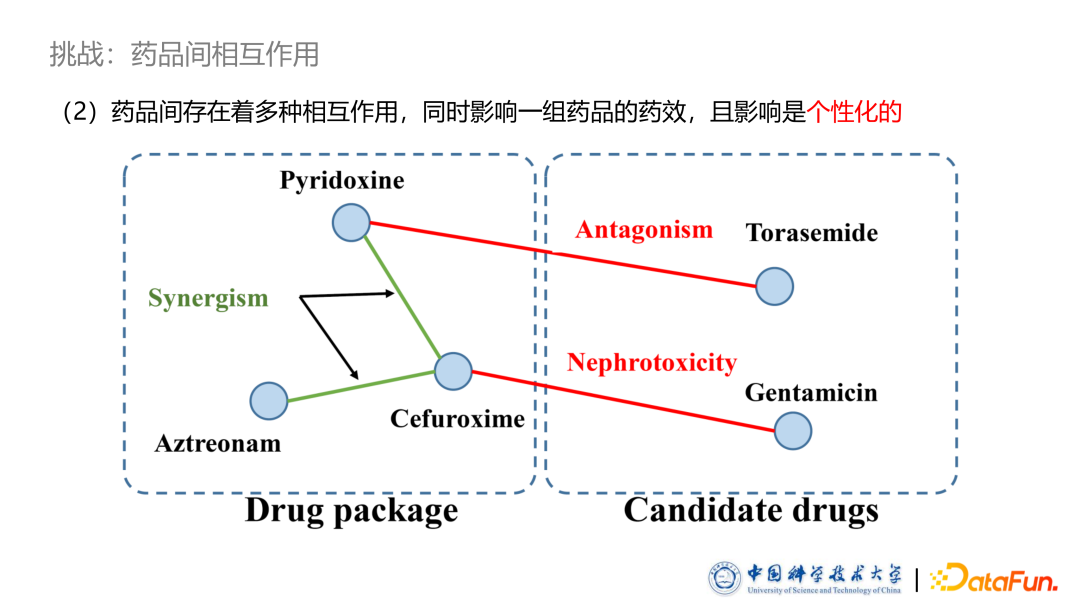
药品推荐系统的第二个挑战是药品之间存在着多种多样的相互作用。有些药品之间存在药效互相促进的协同作用,有些药品间存在药效互相抵消的拮抗作用,甚至有些药品的合用会导致毒性或者其他副作用。图中病人是患有某种肾脏疾病,左边部分是医生为病人所开药品,其中部分药品存在协同作用,可以促进药效。右边部分是统计分析出来的对症高频药品。可以看到这些药品可能是由于一些拮抗作用而没有被选取,下面的药品可能是跟已有的某种药品产生了毒性,因此也没有被此患者使用。此外,药品的相互作用影响是个性化的。我们在数据统计中发现存在大量有拮抗作用、甚至是有毒性作用的药品同时使用。根据分析,其实医生是会根据病人的病情考虑相互作用影响而开出药物。比如一些肾脏健康的病人,他往往可以承受一定的药品肾脏毒性的,因此我们需要对药品之间的相互作用进行个性化的建模和分析。
3. 图表示学习技术成为了新的可能
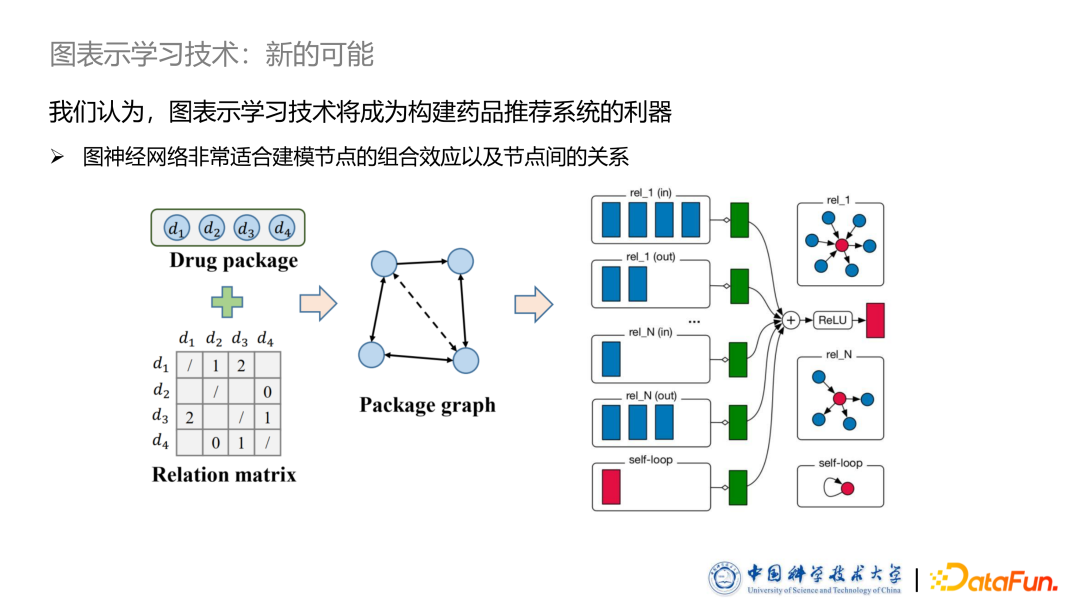
总结来说,结合以上的挑战,图表示学习技术是非常适合解决药品推荐系统中存在的问题。随着图神经网络的飞速发展,人们意识到图神经网络技术可以非常有效的建模节点之间的组合效应与节点之间的关系,这启发我们图表示学习技术或许将会成为构建药品推荐系统的一个利器。图中举例来说,我们可以将一个药品包根据其中的相互作用构建成图,通过已有的图神经网络进行建模。基于以上想法,我们使用图深度学习技术在药品推荐系统上做了两篇工作,分别发表在 WWW 和 TOIS 期刊上,以下是详细介绍。
02
判别式药品包推荐首先介绍一下我们发表在 WWW2021 上的关于药品包推荐论文。这篇文章采用了包推荐系统中广泛应用的判别式模型定义方法建模,同时使用了图表示学习技术作为核心技术部分。
1. 数据描述
- 电子病例数据

首先介绍工作中使用的数据描述。我们在研究工作中使用的电子病历是来自于一个大型三甲医院的真实电子病历数据库,其中每条电子病历都包括了以下几类信息:一是患者的基本信息,包括患者的年龄、性别、医保等等;二是患者的化验信息,包括医生关注的化验结果的异常,以及异常的种类:偏高、偏低、是否阳性等;三是医生为患者撰写的病情描述:包括患者为什么入院、以及初步体格检查等信息;最后是医生为患者开的一组药品。此电子病历数据是一个异构数据,包括年龄、性别、化验等结构化信息以及病情描述等非结构化文本信息。
- 药品数据
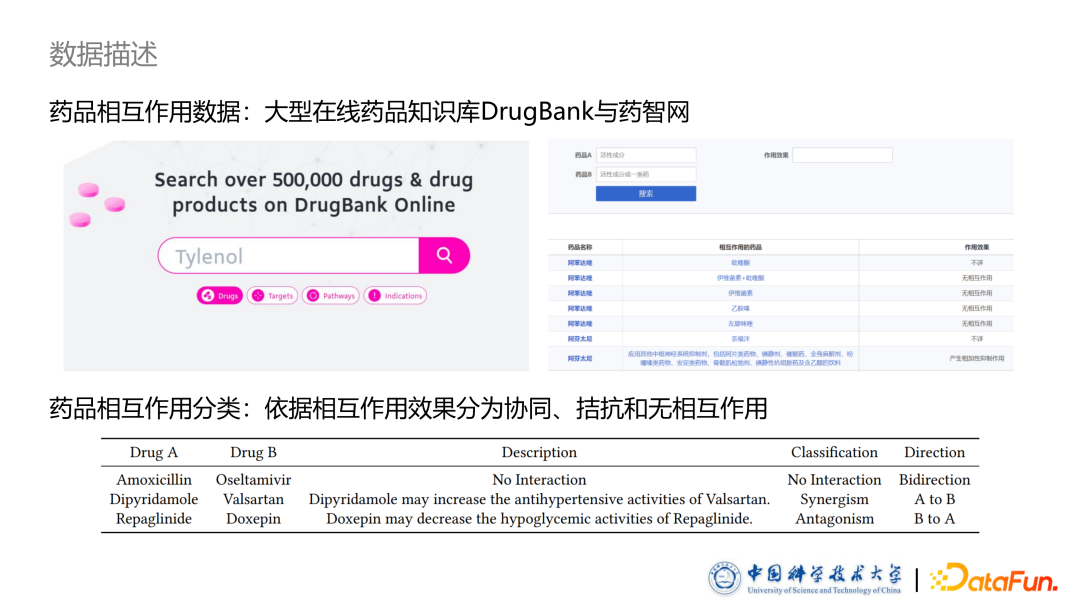
为了研究药品之间的相互作用,我们从 DrugBank 与药制网两个大型在线开源药品知识库里收集了部分药品的属性及相互作用数据。药品相互作用是基于一些模板的自然语言描述,如上图中 description 一栏是在讲某种药品可能可以增加代谢或减弱代谢等,中间话是模板,前后是填充的药品名字。因此只要清楚模型分类,则可以把数据库里所有的药品相互作用进行标记。因此,**我们在专业医师的指导下,把药品相互作用考虑了无相互作用、协同作用和拮抗作用三类,把模板进行了标注,得到了药品相互作用的分类。
2. 数据预处理与问题定义数据预处理来说,对于电子病历数据,我们将其分为了两个部分:患者的基本信息和化验信息,我们将其处理为一个 One-hot 的向量;病情描述文本部分,我们通过一些 Padding 与 Cut off 将其转化为定长文本。对于药品相互作用数据:我们将其转化为一个药品的相互作用矩阵。同时问题定义如下:给定一组患者的描述以及对应 Ground-truth 药品包,我们将训练一个个性化的打分函数,该函数可以输入给定患者和样品包,输出一个匹配程度打分。很明显,这是一个判别式模型的定义方式。
3. 模型概览
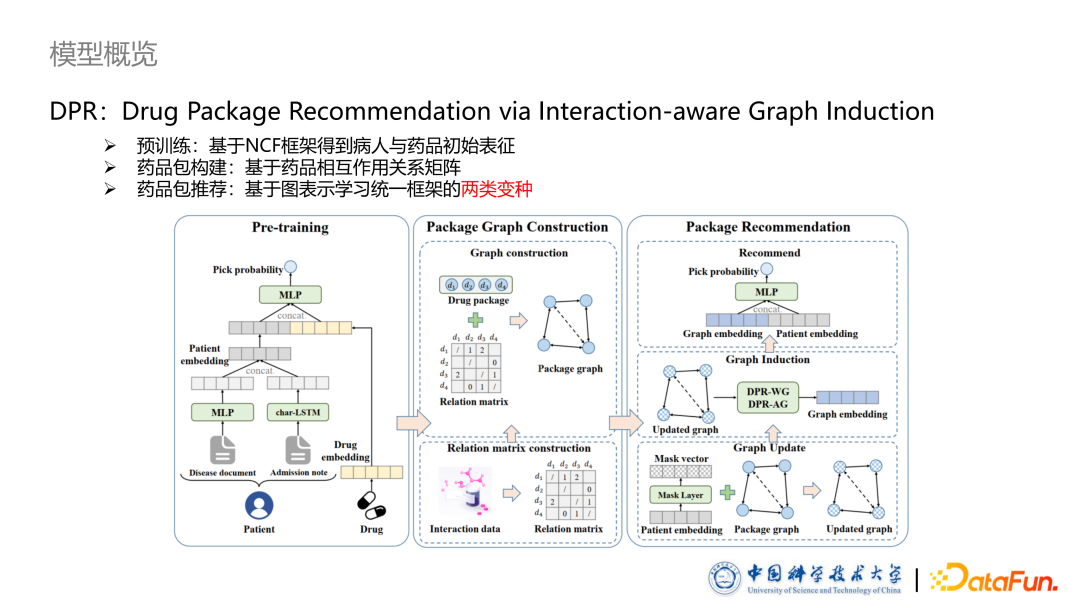
**本文提出的论文题目是 DPR:Drug Package Recommendation via Interaction-aware Graph Induction。模型包括三个部分:**预训练部分,我们基于 NCF 框架得到病人与药品初始表征。药品包构建部分,我们提出了一种基于药品相互作用关系类型,将药品包构建成药品图的方法。最后一个部分是基于图的药品包的推荐框架,其中设计了两个不同的变种,从两种不同的角度去理解如何建模药品之间的相互作用。
预训练
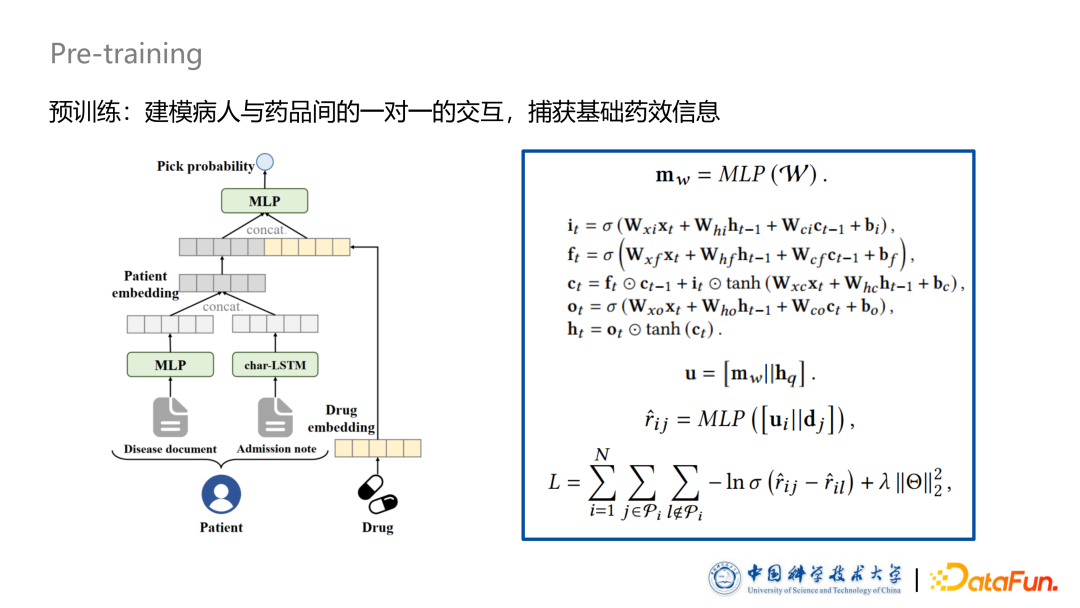
首先预训练部分是按照传统的一对一推荐方式进行的。给定一个病例,医生为给病人使用过的药品是正例,未使用过的药品是负例。通过 BPRLoss 进行预训练,使用过的药品得分比没使用过的高。预训练部分主要是要捕捉基本的药效信息,为后面捕捉更复杂的交互作用提供基础。对于 One-hot 部分,我们使用 MLP 提取特征;对于文本部分,我们使用LSTM提取文本特征。
药品图构建
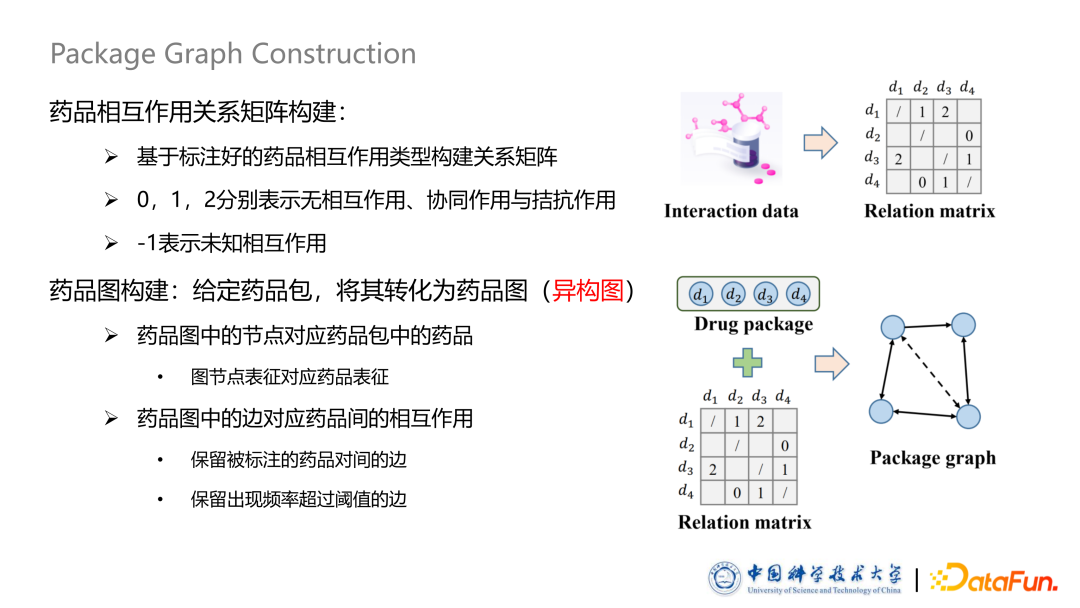
与传统推荐相比,药品推荐的核心问题是如何考虑药品间的相互作用关系,得到药品包的表征。基于此,本文提出了基于图模型的药品包建模方法。 首先,已标注好的药品相互作用关系会转化成一个药品相互作用矩阵,其中不同的数值表示不同的相互作用类型。随后基于此矩可以将任意一个给定的药品包转化成一个异构药品图,图中节点对应药品包中的药品,节点属性是节点对应上一个步骤中的预训练过的Embedding。同时为了避免计算量过大,我们并没有把药品图构建成完全图,即没有让任意两个药品之间都有一条边,而是有选择的进行保留,具体而言只保留了那些被标注过的药品对的边以及频率超过一定阈值的边。
药品图构建
为了对药品图进行有效表征,我们提出了两种方式对药品图上的边属性进行形式化。
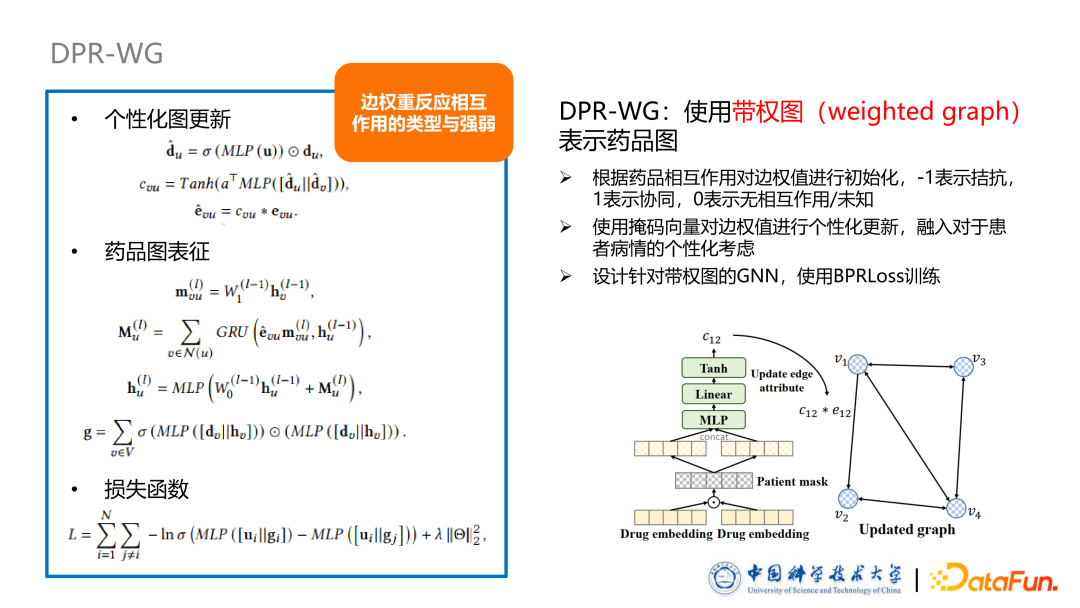
第一种形式是 DPR-WG,使用带权图表示药品图。首先是根据标注好的药品相互作用,对边全值进行初始化,其中使用-1表示拮抗,+1表示协同,0 是表示无相互作用或者未知。随后使用了掩码向量对药品图中的边权值进行个性化的更新。该掩码向量反映了不同药品的相互作用,对于个病人的个性化的影响程度,它的计算方法是使用一个非线性层加 Sigmoid 的函数使得每一个维度取值都是从 0~1 之间,从而实现特征选择的作用,对药品的相互作用进行个性化调整。药品图更新过程是在 DPR-WG 中先算出一个更新因子,更新因子与对应边上的权重相乘或者相加等进行更新。后续实验中发现其实更新方法对结果影响不大,在药品图表征过程中,我们设计了基于带权图的表示药品的方法。总结来说,我们首先设计了一个针对带权图的信息更新过程:聚合邻居信息,在聚合的过程中,根据边的权重,个性化调整它聚合程度。随后我们使用了一个 Self Attention 机制把不同节点之间的权重计算,使用一个聚合 MLP 把图聚合起来得到最终整个药品图的表征。后续把病人表征与药品图表征输入到打分函数里面去,可以得到输出进行推荐。此外,本文使用 BPRLoss 训练模型,引入负采样方法,对应 1 个正样本有 10 个负样本。
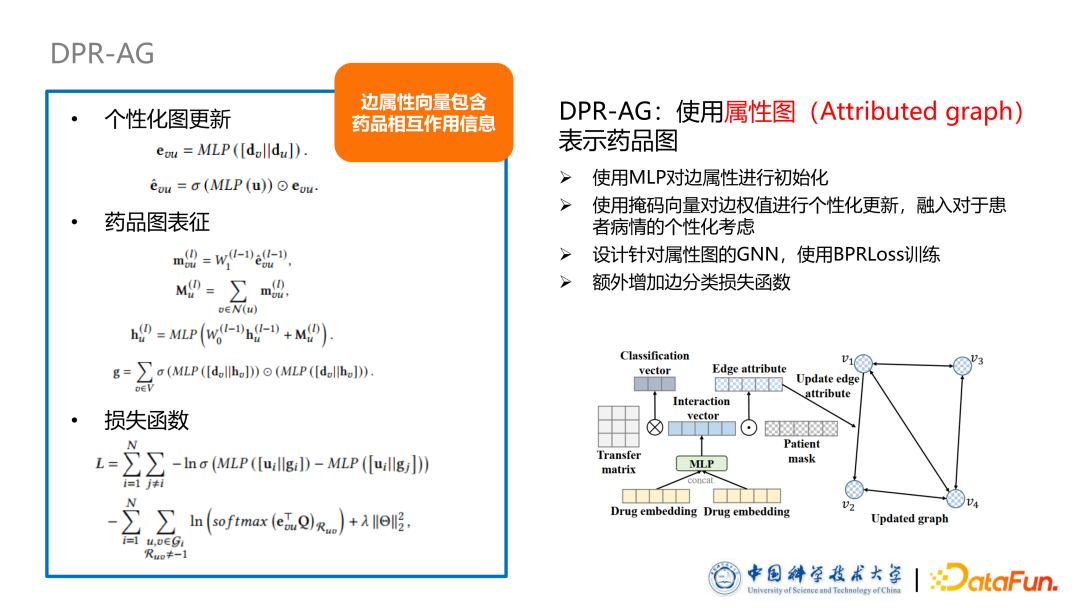
第二个变种是使用属性图表示药品图。首先是通过一个 MLP 融合边两端的节点向量初始化边向量。随后同样使用掩码向量对边向量进行更新,此时更新方法就不再是更新因子,而是计算一个更新向量,使用更新向量与药品的边向量进行逐元素相乘,得到更新后的边属性向量。我们专门设计了针对属性图的 GNN,其 message passsing 过程首先是根据边向量及两端的节点 Embedding计算出message进行传播,通过self attention及聚合方法得到Graph Embedding。同样我们可以采用 BPRLoss 进行训练,不同的是我们额外引进了一个针对边分类的交叉熵损失函数,希望边向量可以包含药品相互作用的类别信息。因为上一个变种中初始化的正负号天然的保留了此信息,但此变种的图没有,因此通过引入损失函数来把此信息补上。
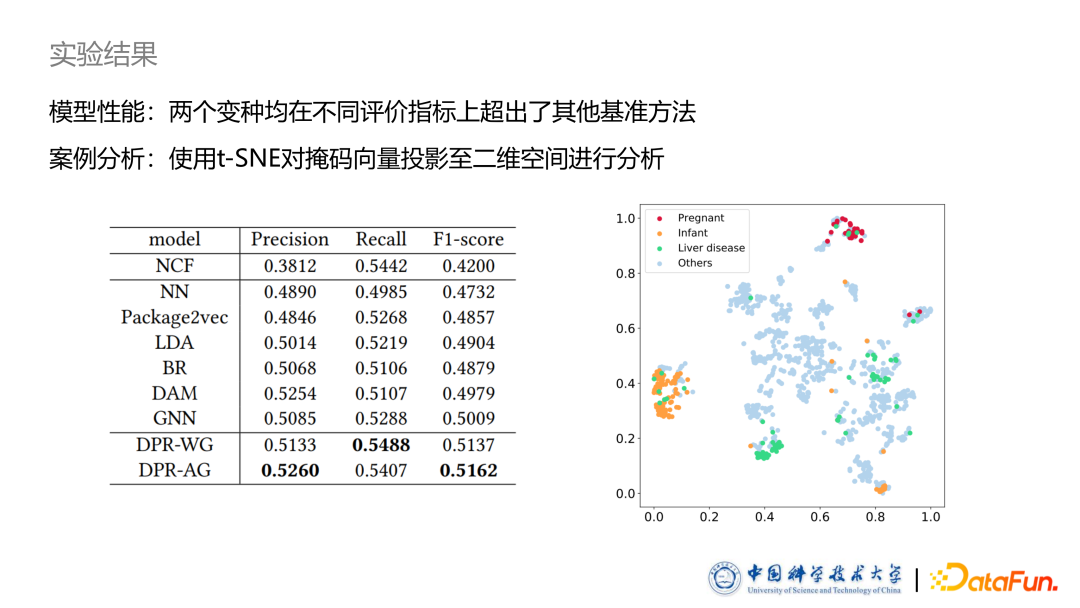
从实验结果来看,我们的两个模型均在不同的评价指标上超出了其他判别式模型。同时我们也进行了案例分析:采用 t-SNE 方法,把之前提到的掩码向量投影到一个二维的空间上。图中所示,比如孕妇、婴儿以及肝脏病人等,他们使用的药物有非常明显的聚集成簇的趋势,证明了我们方法的有效性。03
生成式药品包推荐以上判别式模型只能在已有药品包中进行挑选,没有生成新的药品包能力,会影响推荐效果,接下来我们将会介绍发表在 TOIS 期刊上的针对上一篇工作的扩展工作,目的是希望模型能够生成全新的为新病人量身定做药品包。此工作是保留了上一篇论文中图表示学习的核心思想,同时完全改变问题定义,把模型定义成生成模型,引入序列生成与强化学习技术,大幅的提高了推荐效果。
1. 判别式推荐->生成式推荐

判别式模型与生成式模型的核心区别是判别式模型是给定病人与给定药品包的匹配程度打分,而生成式模型是为病人生成候选药品包并挑选最佳药品包。
2. 启发式生成方法

针对上文中提出的判别式模型的缺点,我们设计了一些启发式生成方法:通过在相似病人的药品包中进行增加和删除部分药品的操作,形成一些历史记录中从来没有出现过的药品包供模型挑选。实验结果证明这种简单的方法十分有效,为后续方法提供了基础。
3. 模型概览
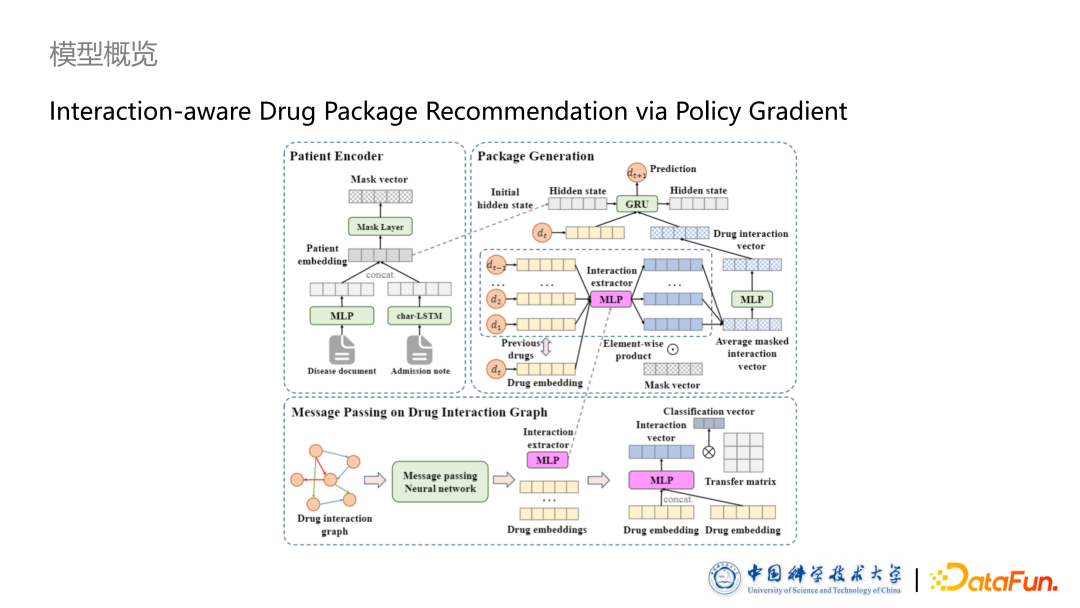
接下来是发表在 TOIS 的 Interaction-aware Drug Package Recommendation via Policy Gradient 文章。文中提出的模型叫做 DPG,不同于上一篇的 DPR,这里的 G 是 Generation。此模型主要包含三个部分,分别是药品相互作用图上的信息传播,病人的表征以及药品包生成模块,与上文的最大的区别是药品包生成模块。
药品相互作用图
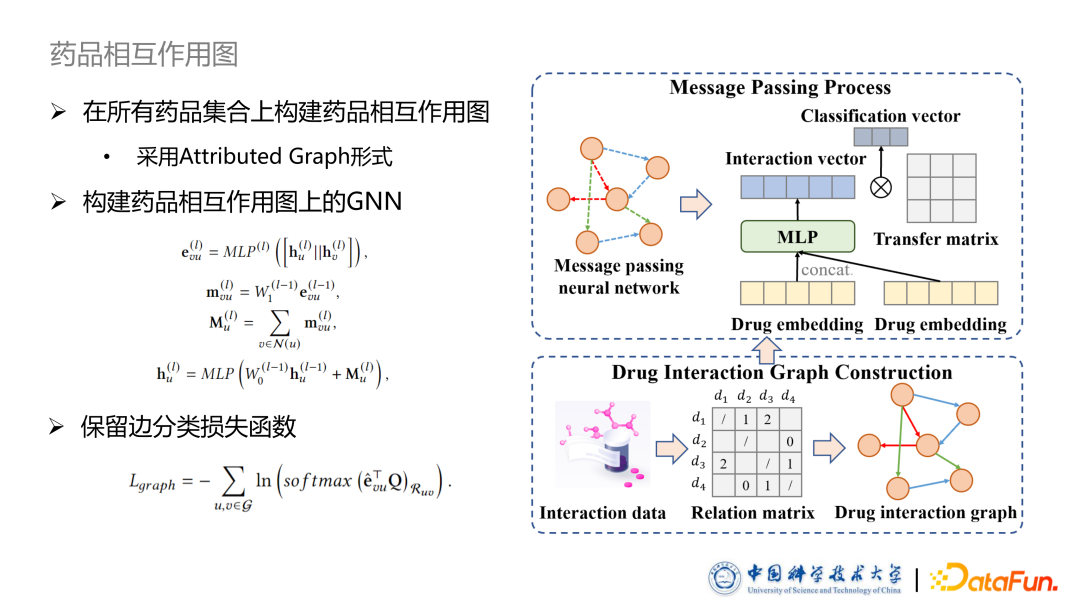
首先构建药品相互作用图部分,文中保留了图神经网络捕捉药品间相互作用的方法,不同的是判别式模型中,药品包是给定的,可以方便的转化为药品图,而在生成式模型中,药品图是不固定的,由于计算量原因,无法把所有的药品包都构建成图。本文把所有的药品全部包含在了一个药品相互作用图中,同样采用 Attributed graph 进行图形式化,同时也保留了边分类损失函数,保留边的 Embedding 信息,最后也构建了基于此药品相互作用图上的 GNN。经过几轮(一般为2)的 message passing 后,我们提取其中节点 Embedding 作为要使用的药品 Embedding。
病人表征
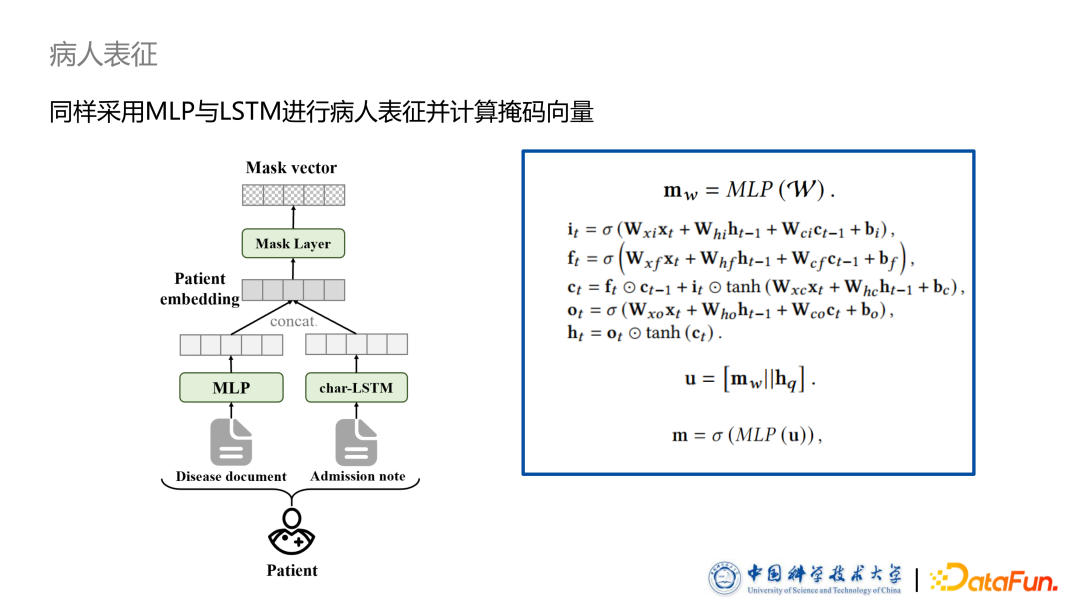
- 基于序列生成的药品包生成
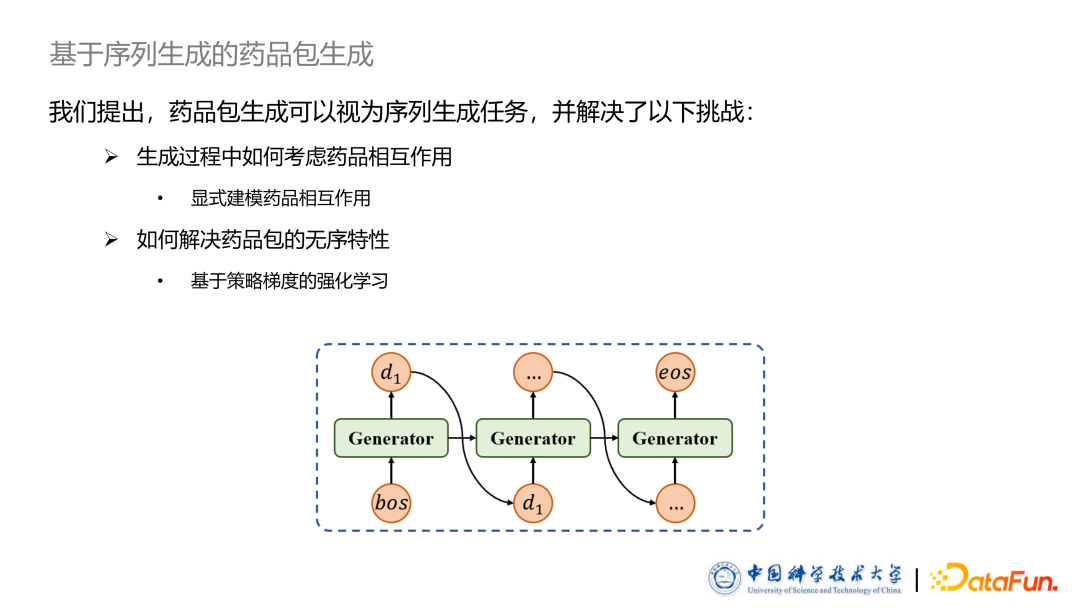
药品包生成任务可以视为一个序列生成任务,采用循环神经网络 RNN 实现。但此方法也带来了两大挑战: 第一个挑战是在生成过程中如何考虑生成出的药品和已有的药品之间的相互作用。为此我们提出了一种基于药品相互作用向量的方法显式建模药品之间的相互作用。第二个挑战是样品包是一个集合,本质是无序的,但是序列生成任务往往针对有序序列顺序的方法。为此我们提出了一种基于策略梯度的强化学习方法,同时增加了基于SCST的方法来提升此算法的效果和稳定性。
- 基于极大似然的药品包生成

首先介绍如何在基于极大自然的药品包生成过程中考虑药品间的相互作用,此部分也是后面用强化学习部分的基础。基于极大似然的序列生成方法在 NLP 领域已经得到了广泛使用,在生成过程中,每生成一个药品都依赖于之前生成的其他药品。 为了考虑到药品间的相互作用,同时又不为模型带来过大的计算负担,我们提出在每一个时间步,显式计算最新生成的药品与之前药品的相互作用向量,此向量计算方法来自于之前图神经网络里的一个层。同时我们增加掩码向量与相互作用向量进行对应元素相乘,引入患者的个性化信息。最后把所有药品的相互作用向量求和,使用 MLP 将其融合得到综合的相互作用向量。后续把此向量融入经典的序列模型中进行生成,则是解决了第一个挑战。

与经典的序列生成不同的是药品包其实是一个集合,不应该出现重复药品,因此我们后续增加了一个限制,让模型不能生成已经生成过的这个药品,保证生成结果一定是一个集合。最后我们采用了基于极大似然的 MLE 损失函数训练模型。
- 基于强化学习的药品包生成
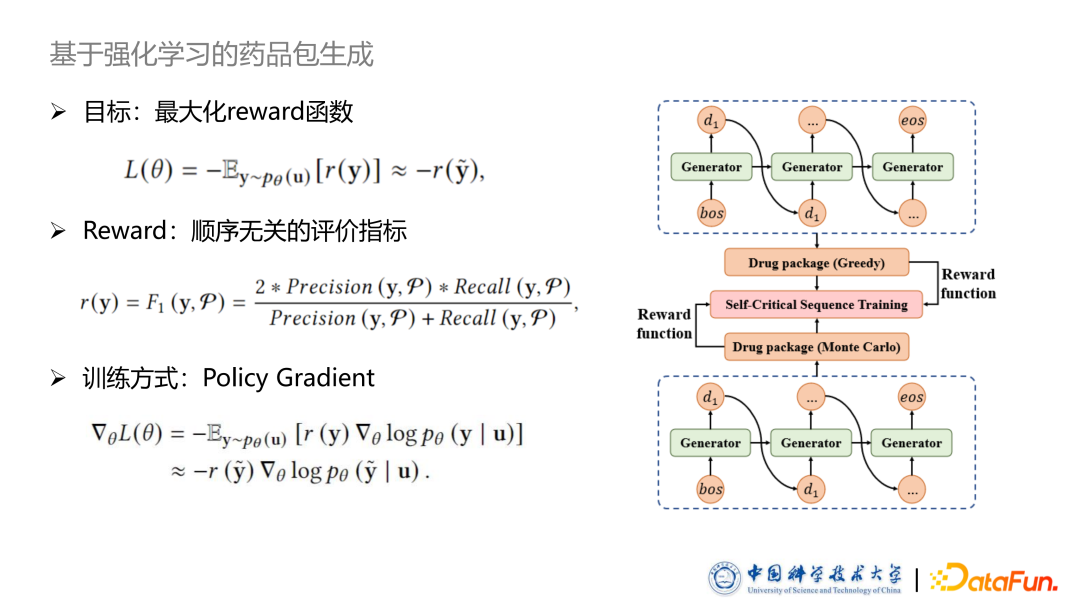
以上基于最大似然的方法最大的缺点是药品包具有严格顺序,部分人工为药品指定顺序的方法,如根据频率排序,根据首字母排序等等,会破坏药品包集合的特性,同时也会损失掉部分模型的 performance,因此我们提出了基于强化学习的药品包生成模型。强化学习中模型的目标是最大化人工设置的 reward 函数,在模型生成完整的药品包之后,给一个和顺序无关的 reward 损失函数,则可以减弱模型对顺序的依赖性。本文采用的是 F-value 作为 reward,它是一个顺序无关的函数,同时是我们所关注的评价指标。本文采用 F-value 作为评价指标,在训练方式上采用了基于策略梯度的训练方式,在此就不进行详细推导。
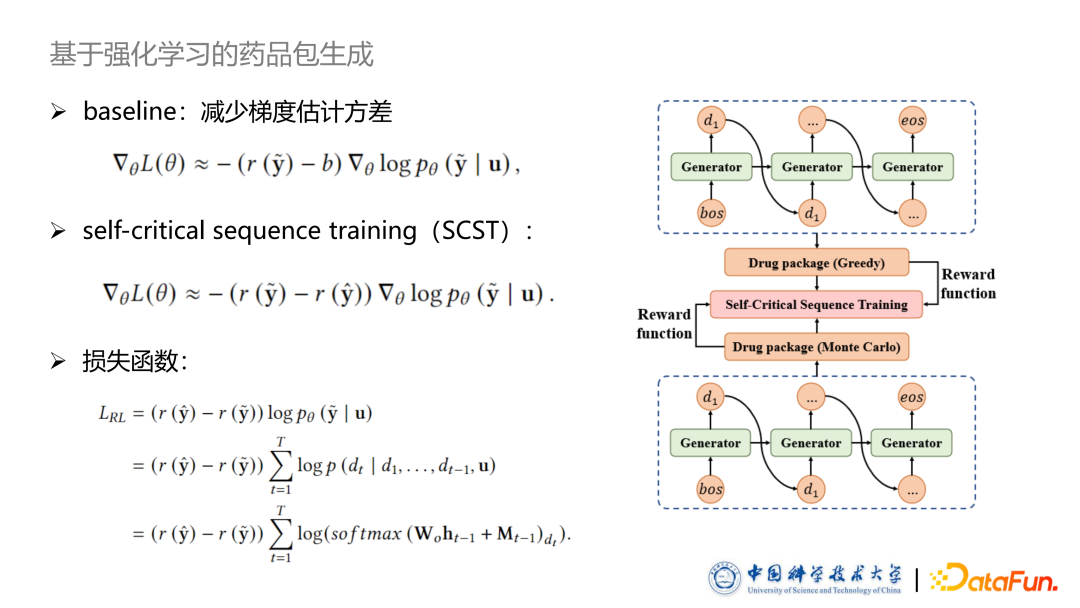
基于策略梯度的训练方法中,其重一个广为人知的方法是使用一个 baseline 减少梯度估计的方差,从而增加训练的稳定性。因此我们使用了基于 SCST 的训练方式,即 Self-critical sequence training 方法。baseline 同样来自于模型自身生成的这个药品包所获得的 reward,自己生成的方式我设计为 Greedy search 的正常序列生成方法。我们希望模型根据 Policy gradient 采样出来的药品包的 reward 要高于传统给予 Greedy search 生成出来药品包。基于此本文设计了强化学习的损失函数,如图中所示,这里就不详细的介绍推导过程。
- 极大似然预训练+强化学习

此外,强化学习的一个特性是训练较难,因此我们结合了以上两种训练方式,首先采用极大自然的估计方法对模型进行预训练,随后采用强化学习的方法,对模型参数进行微调。
- 实验结果
接下来是模型的实验结果。
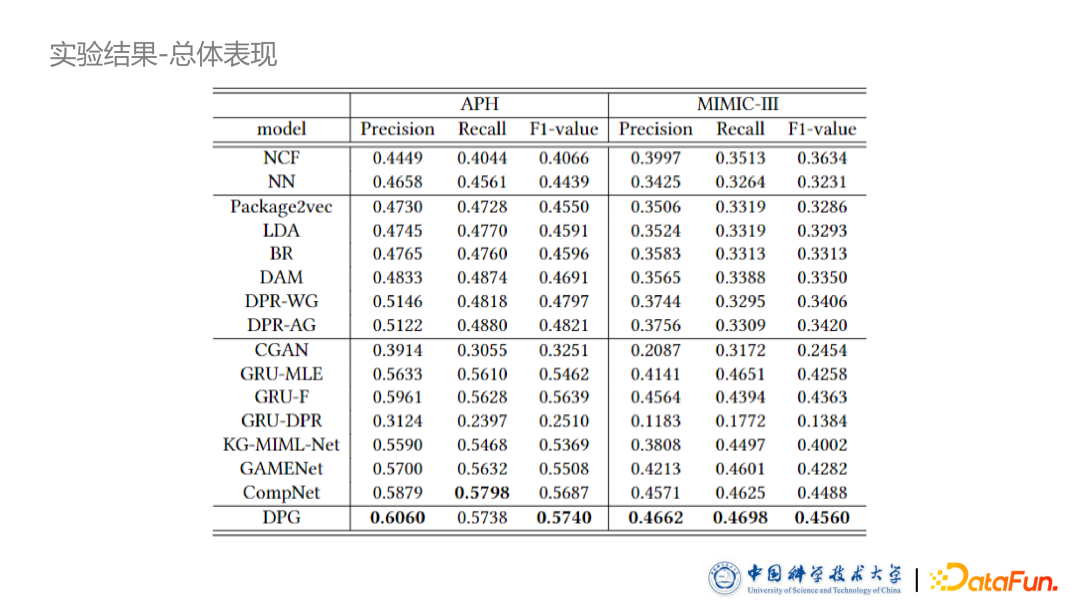
在上表中,所有的药品包都是用 Greedy search 生成的。首先基于生成式模型的表现普遍优于基于判别式模型方法,该实验证明了生成式模型将会是一个更加优秀的选择。此模型在 F value 上超越了其他所有的 Baseline。此外,基于强化学习的模型表现大大超越了基于极大似然模型,证明了强化学习方法的有效性。
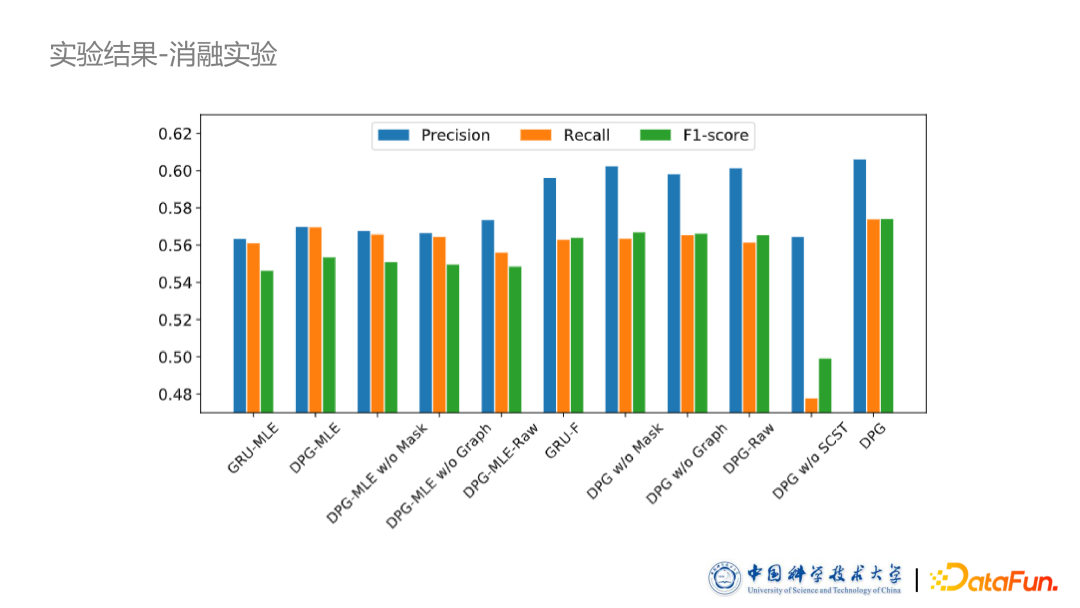
后续我们还进行了一系列的消融实验。我们分别去掉了相互作用图,包括相互作用的掩码向量以及强化学习的模块进行消融,结果证明我们的各个模块都是有效的。同时可以看到,把 SCST 模块去掉,模型效果下降非常多,因此也证明了强化学习确实比较难训练。如果不加 Baseline 限制,整个训练过程会非常抖动。
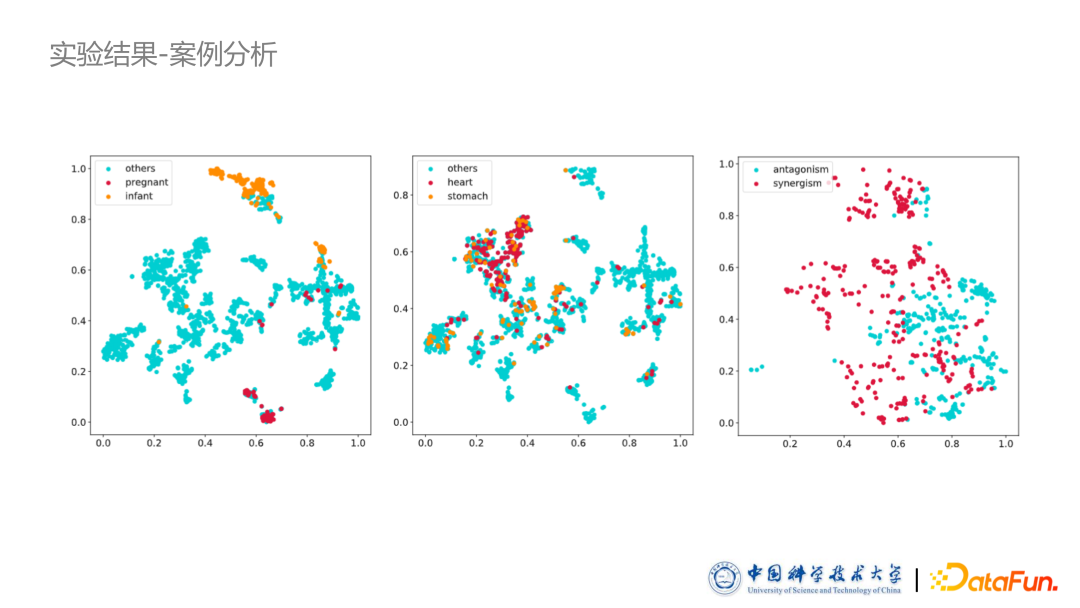
最后我们也做了大量的案例分析,可以看到孕妇和婴儿有明显的个性化偏好。同时我们额外加了一些常见病如胃病、心脏病等,这些病的掩码向量则分布非常分散,没有形成簇。常见病的患者情况多种多样,不会有特别个性化的情况出现,不像孕妇和婴儿有着非常明显的对于药品的筛选,如某些需要指定小儿药品,有些药品孕妇不能使用等。同时我们对药品的相互作用向量进行了投影,可以看到协同作用和拮抗作用两种药品相互作用形成了两个不同的对立情况,说明模型捕捉到了两种不同相互作用带来的不同效果。
04
总结与展望总结来说,我们的研究主要是相互作用感知的个性化药品包推荐,包括判别式的药品包推荐以及生成式的药品包推荐。两者共同点是都使用了图表示学习技术来建模药品间的相互作用、都使用了掩码向量考虑病人病情对于相互作用的个性化的感知。两项工作最大的区别是问题定义差别,对于判别模型我们要的是一个打分函数,那么对于生成模型我们要的是一个生成器,通过实验证明,生成式模型其实是对于问题更好的一个定义。
|分享嘉宾|

郑值
中科大 博士研究生
本科及硕士就读于中科大计算机学院,博士就读于中科大大数据学院。以第一作者身份发表CCF A类会议及期刊论文4篇,CCF中文A类期刊论文1篇。曾获得元庆奖学金、华为奖学金、深交所奖学金等奖项,并入选腾讯犀牛鸟精英科研人才计划。主要研究方向为推荐系统。

