
OpenAI的12天发布会结束,其中4天是大模型推理 (第一天、第二天、第九天、第十二天)。
从技术角度看,12天中,开头给人期待,结尾有惊喜。一头一尾对应了两代推理模型,但仍然聚焦在数学和编程两个任务上。第二天发布的强化微调技术则让人看到了大模型推理泛化应用到更多领域的可能:只需要提供几十到几千个领域训练样本,就可以获得一个专注于这个领域的推理模型。 强化微调的意义包括:(1) 打开了对推理基础模型的想象。从最近几个月的单纯提升推理能力,到思考基于推理基础模型如何做领域泛化。 (2)提供了一种新的对基础模型微调的范式。不同于SFT的机械模仿,RFT可以基于推理能力来思考和试错,有望实现像人一样举一反三的能力。 字节此前提出的ReFT方法需要基于大量有推理过程的训练数据,而且定位和RFT也不同:ReFT旨在从系统1模型学习一个系统2模型,而RFT的目的是从系统2基础模型微调得到系统2领域模型。将ReFT直接应用于RFT的设置时,会由于策略模型和训练数据的分布不同而失效。 北京交通大学桑基韬教授团队在此前发布o1-Coder的基础上,结合强化学习和树搜索等技术,提出了与OpenAI的RFT同样设置下的强化微调解决方案:OpenRFT。只需要100个样本,在扩散速率分析、矿物稳定性预测等领域任务上的推理性能提升了11%,部分任务性能提升超过25%,甚至超过了o1-mini。 OpenRFT的技术报告已发布,代码和模型同步开源。项目链接:https://github.com/ADaM-BJTU/OpenRFT
1. 三种方法利用领域训练样本
实现RFT要首先解决两个问题: 只提供了少量领域训练样本、且这些样本没有包含推理过程数据。 对于第一个问题,OpenRFT试验了两种方案:(1)数据增强,通过改写问题和打乱问题选项合成新的训练数据;(2)领域知识增强:将领域训练样本以示例的形式加入策略函数训练的prompt中。 对于第二个问题,OpenRFT提供的方案是:(1)知识蒸馏,通过一个teacher推理模型通过树搜索补齐推理过程,然后对策略模型进行监督微调;(2)过程监督,加入过程奖励函数PRM提高采样正确推理过程的概率。 最终的解决方案可以根据领域训练样本被利用的方法,分成数据增强、基于SFT的模仿学习和基于RL的探索增强三个模块。
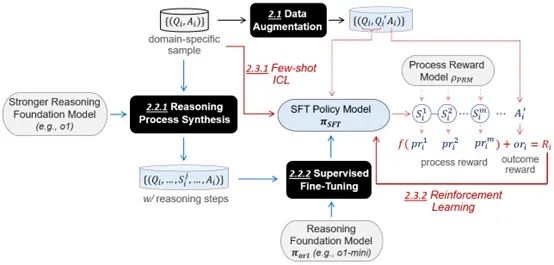
在数据增强模块,问题和问题选项分别通过改写和打乱顺序生成新的问题Q’,答案A不变。团队同时尝试了让模型生成全新的问题、但没有答案的数据增强方法,具体内容会在后续更新中提供。 基于SFT的模仿学习模块与o1-Coder的实现类似,主要不同在于树搜索使用的是一个更强的系统2推理模型,而不再是系统1语言模型。 基于RL的探索增强模块,领域训练样本作为示例加入到策略模型的上下文中,通过示例中提供的隐性领域知识引导推理行为。 报告特别强调,理想情况下,teacher推理模型、PRM和待微调的student推理模型最好具有相同的行为状态空间,否则会对最终性能有较大影响。
2. 科学问答领域任务实验
为了模拟领域任务,团队使用了最近发布的科学问题评估集SciKnowEval。这个数据集包含了五个等级,其中等级3评估的是模型的推理能力。 OpenRFT选择了等级3的8个领域任务:GB1-fitness-prediction、retrosynthesis、chemical-calculation、molecule-structure-prediction、high-school-physics-calculation、material-calculation、diffusion-rate-analysis、perovskite-stability-prediction,覆盖了生物、化学、物理、材料四个学科。 举个例子,perovskite-stability-prediction任务的问题长这样:

每个领域任务的训练样本数为100。选择的策略模型和PRM都来自Skywork-o1系列,分别是Skywork-o1-Open-Llama-3.1-8B和Skywork-o1-Open-PRM-Qwen-2.5-7B。
为对比,报告同时测试了GPT-4o-mini和o1-mini的表现,作为系统1和系统2模型的代表。
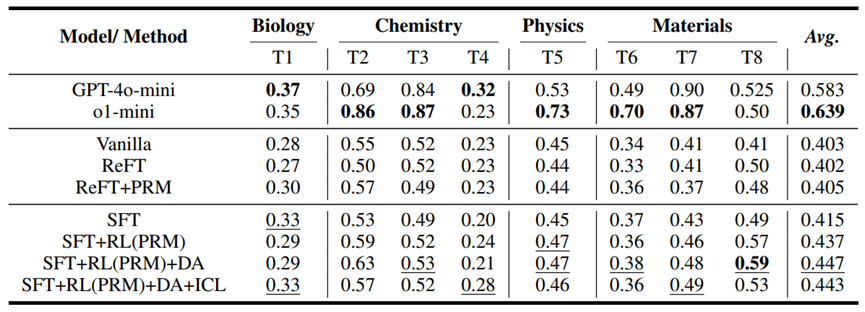
不出意外,o1-mini表现出了最强的推理能力。但GPT-4o-mini与o1-mini互有胜负: GPT-4o-mini胜在通用性,因而在领域知识起关键作用的任务上表现比o1-mini好。
ReFT确实无法直接应用于RFT的设置,在加入PRM过程监督后,性能稍有提升。
第三组是OpenRFT不同版本的结果。为避免行为空间不一致的问题,实验中选择让策略模型自己合成推理过程数据然后SFT,有一定提升,但也不明显。
主要的提升来自于强化学习和过程监督,数据增强有一定作用。但few-shot ICL目前并没有起作用,报告认为这可能是SFT和RL两个阶段的prompt格式不一致导致的。有意思的是,ICL提升较为明显的任务4也是GPT-4o-mini表现最好的,是测试任务中最难的。说明few-shot ICL对融合领域知识有一定作用。
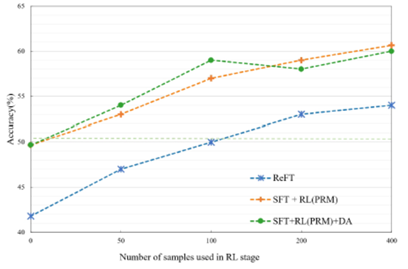
报告同时分析了领域样本数量对训练效果的影响。从50个样本到400个样本,提升幅度还是挺明显的。说明目前的方案仍然比较依赖训练样本数量。
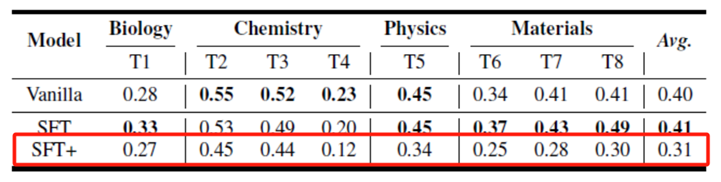
对于teacher推理模型和待微调的student推理模型行为状态空间一致性的影响,用QwQ-32B替代Skywork-o1-8B合成推理过程数据(SFT+)。微调后的模型性能甚至不如微调前。这说明微调和应用推理模型时,要额外注意模型的行为和状态空间。
3. 相关工作
技术报告的最后从系统1和系统2的角度,总结了与强化微调相关的几个研究方向。
(1) 基于系统1模型获得系统2能力。
包括ReFT在内、以及近期复现o1的很多工作都属于这一类。作者将相关工作分成了prompting(如思维链、思维树等)和基于学习两个分支,而基于学习又包括SFT和RL两种,ReFT就综合了SFT和RL的学习方法。
这些工作假定尚不存在推理模型,目的就是要训练获得一个推理模型。而RFT假定已经存在一个推理基础模型,目的是通过微调获得领域专用的推理模型。
(2) 对基础模型的微调。
此前的微调聚焦系统1基础模型,使用的方法是SFT,通过记忆和模仿来学习。而RFT旨在微调系统2基础模型,可以通过思考、探索和试错来学习。作者认为RFT是基础模型能力达到一定程度后才可能发生的。
从依赖的训练数据和采用的学习方法两个角度,报告比较了系统1和系统2的预训练和微调两个阶段。

(3) 基于强化学习的微调。
从方法上看,RFT和RLHF、强化蒸馏一样,都是基于强化学习对生成模型进行微调。相比基于监督学习的微调,这类方法有两个特点:它的训练目标是优化策略函数最大化累积奖励,因而可以通过自适应探索更好地应对不确定;由于可以通过与环境交互,因而这类方法可以从很少量的高质量数据中学习,在学习过程中动态合成新的经验数据。
然而,RFT和RLHF、强化蒸馏等方法有很多不同。从奖励函数的来源看,RLHF来源于人类偏好,强化蒸馏来源于teacher模型,RFT则来自领域专家数据。从策略模型看,RLHF微调的对象是Base/SFT模型,旨在对齐人类价值;强化蒸馏微调的对象是student模型,旨在进行模型压缩;而RFT微调的对象是推理基础模型,旨在获得领域专有的推理能力。这些不同也为RFT带来了任务不一致和行为模式不一****致两方面新的挑战。

如同对o1的复现一样,对强化微调技术路线的探索也会一直进行下去。报告最后给出了后续可以改进的两个方向:领域数据合成和领域知识嵌入。
**对开放问题的奖励函数定义和行为模式的高效适配将是进一步提升强化微调性能的关键。**目前RFT解决的还是多项选择形式的问题。试想,未来只提供某个领域的专业技术报告,推理模型如果能从中快速学习到领域专家的思考模式,获得领域推理能力,这会有更大的想象空间。