强化学习
·


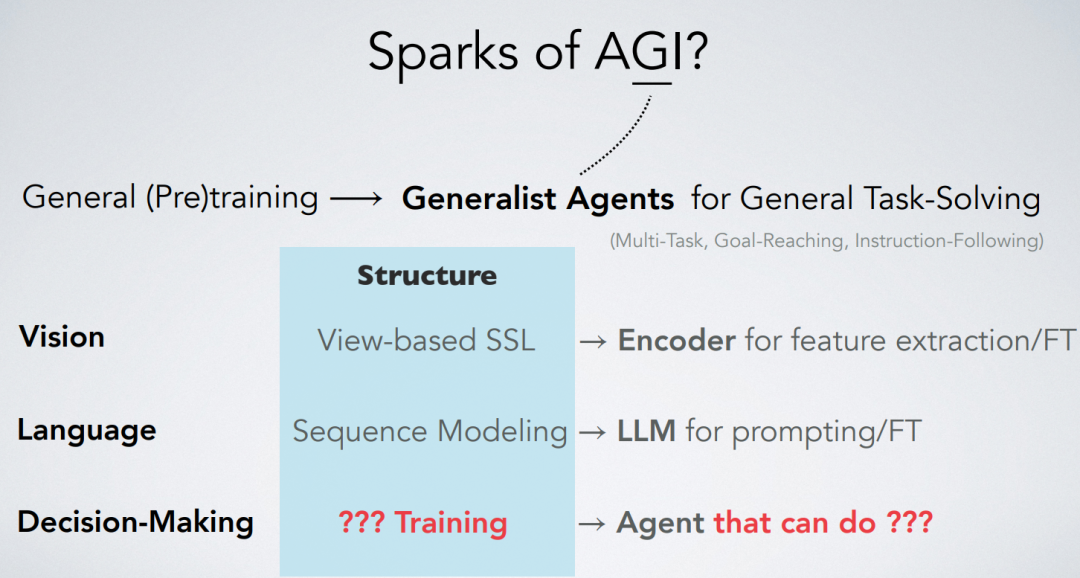
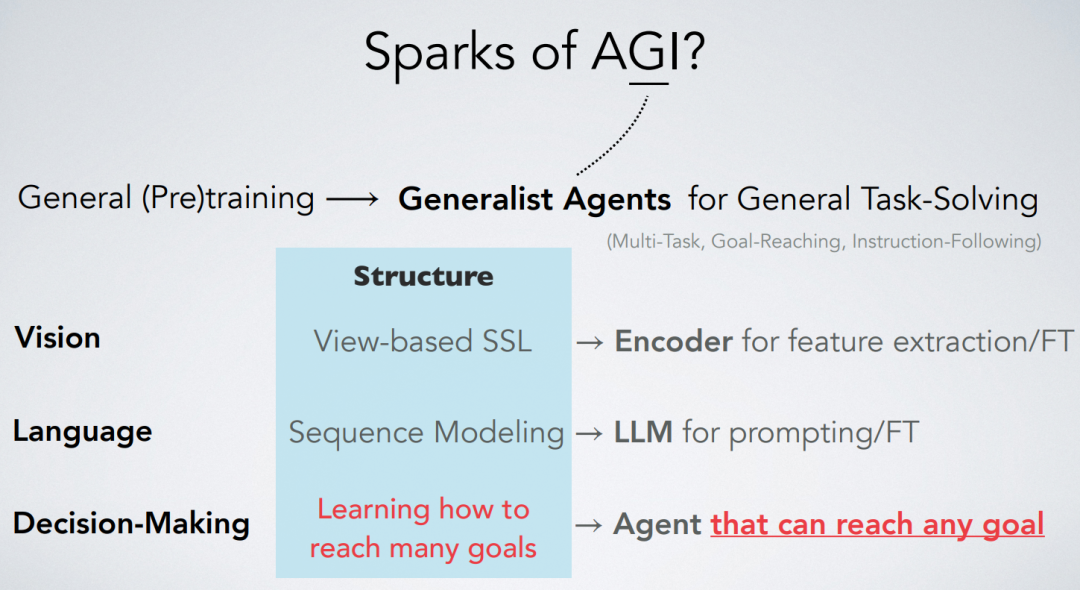
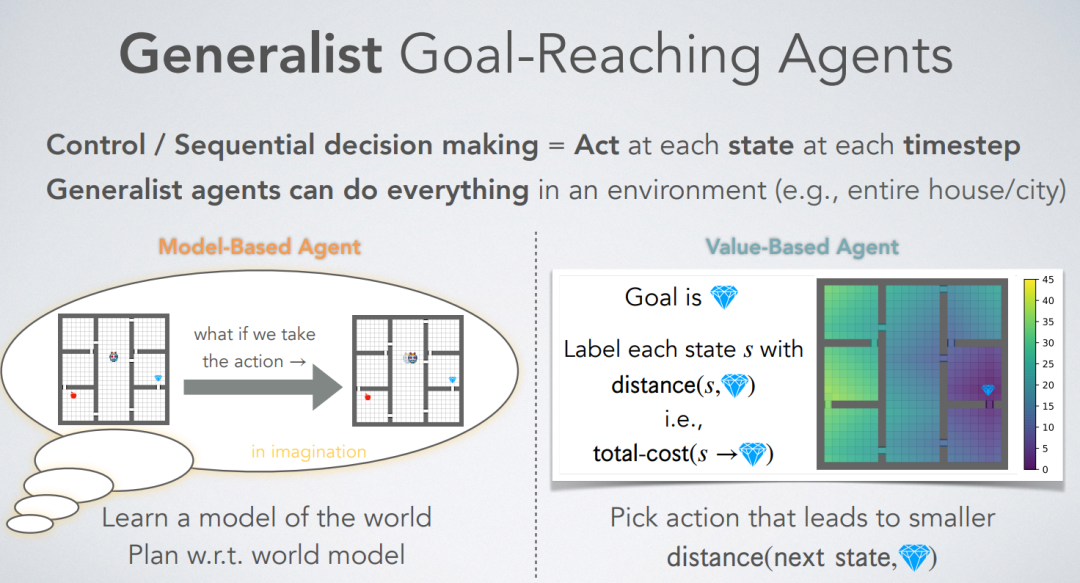
在目标达成的强化学习(RL)中,最优价值函数具有特殊的几何形态,被称为准度量结构(也可参见这些工作)。本论文介绍了准度量强化学习(QRL),这是一种新的RL方法,利用准度量模型来学习最优价值函数。与先前的方法不同,QRL的目标特别为准度量设计,并提供强大的理论恢复保证。在实证方面,我们在离散化的MountainCar环境中进行了深入的分析,识别了QRL的属性及其相对于其他选择的优势。在离线和在线的目标达成基准测试中,无论是基于状态的还是基于图像的观察,QRL也展示了改善的样本效率和性能。
成为VIP会员查看完整内容
相关内容
Arxiv
223+阅读 · 2023年4月7日
相关主题

相关VIP内容
相关资讯
相关论文
Arxiv
223+阅读 · 2023年4月7日