
神经信息处理系统大会(Conference on Neural Information Processing Systems,简称NeurIPS),是机器学习和计算神经科学领域的顶级国际会议。NeurIPS 2025将在美国圣地亚哥(12月2日至12月7日)和墨西哥城(11月30日至12月5日)两地举办。本系列文章将分期介绍自动化所在本届会议上的录用论文成果,欢迎交流探讨。

20.** **SynCL:一种实例可感知对比学习增强的面向端到端环视三维物体跟踪的协同训练框架
SynCL: A Synergistic Training Strategy with Instance-Aware Contrastive Learning for End-to-End Multi-Camera 3D Tracking **作者:**林述波,寇宇同,吴子蕤,王绍儒,李兵,胡卫明,高晋 现有的端到端环视三维物体跟踪算法通过实例查询的时序传播整合了检测和跟踪,但这样的联合训练存在优化困难。我们发现这些困难源于自注意力机制的两个固有限制,即对象查询的过度去重和轨迹查询的自我关注。相反,移除自注意力机制不仅对跟踪算法的回归预测影响较小,模型还倾向于生成更多潜在候选框。 为此,本文提出了SynCL,一种协同训练框架来促进多任务学习。具体而言,我们构建了一个基于Cross-attention的平行解码器并引入了混合匹配模块,该模块将轨迹查询的真值目标与多个对象查询匹配,从而挖掘被自注意力机制忽视的高质量预测候选。为了寻找上述一对多匹配中的最优候选,我们还设计了一种由模型训练状态控制的动态查询过滤模块。此外,我们引入了实例可感知对比学习,以突破轨迹查询的自我关注障碍,有效地增强了检测和跟踪之间的协同优化。在不增加额外推理成本的情况下,SynCL在各种基准测试中获得了一致性提升,并在nuScenes数据集上达到了先进性能。
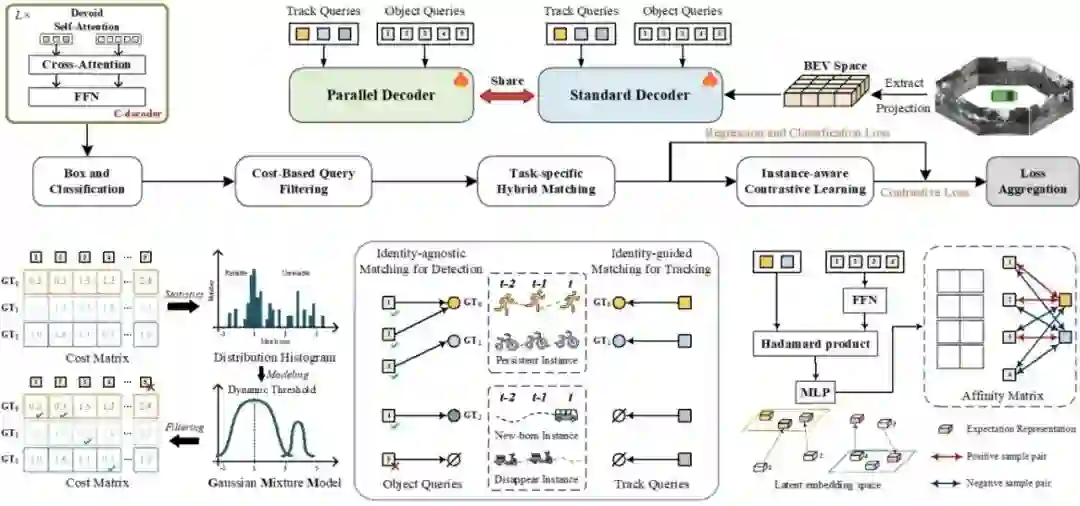
SynCL的方法流程示意图
21.** **任务复杂度驱动的视觉-语言模型函数化剪枝策略
Each Complexity Deserves a Pruning Policy **作者:**王汉石,徐宇豪,徐泽坤,高晋,刘雨帆,胡卫明,王珂、张志鹏 视觉-语言模型在推理过程中往往面临巨大的计算资源开销,主要原因在于用于表达视觉信息的大量视觉输入 token。已有研究表明,相较于文本 token,视觉 token 在推理阶段通常获得更低的注意力权重,反映出其在整体推理中的相对重要性较低,从而具备显著的剪枝潜力。此外,随着解码过程的逐步推进,文本 token 会逐渐整合来自视觉的关键信息,这为视觉 token 的分层剪枝提供了可能性,即从浅层到深层逐步降低保留的视觉 token 数量。 在此背景下,我们提出利用函数化策略对各层保留的视觉 token 数量进行建模。然而,由于不同任务在视觉信息向文本 token 聚合的效率上存在差异,因此采用任务自适应的剪枝函数显得尤为关键。具体而言,对于视觉与语言对应关系较弱的任务,建议在前期保留更多视觉 token,以提供更大的选择空间;而对于语义对应性较强的任务,则可在早期进行更激进的剪枝,从而为后期推理保留更多计算资源和表达能力。我们在多种下游任务与数据集上验证了方法 包括 OCR 与 VLA 并取得优越性能。
图1.对于不同问题的视觉与文本特征交互模式
图2. TextVQA 数据集上的token保留曲线
22.** **基于跨帧实例跟踪融合策略的在线三维物体分割
Online Segment Any 3D Thing as Instance Tracking **作者:**王汉石,蔡子健,高晋,张一伟,胡卫明,王珂,张志鹏 具身任务要求智能体在探索环境的同时,具备对三维场景的全面理解能力,因此亟需一种具备在线性、实时性、精细性与强泛化能力的 3D 感知模型。然而,由于高质量 3D 数据的稀缺,直接在三维空间中训练此类模型面临显著挑战,难以实际可行。现有方法通常采用 SAM生成二维掩码,再基于 mask queries 进行细化,最终得到三维分割结果。在融合阶段,这些方法大多依赖手工设计的策略,如启发式规则或固定参数设置。然而,此类方法存在泛化能力不足、参数敏感性高等问题,并且限制了对历史帧中目标信息的充分利用,影响整体性能。 为克服上述限制,我们摒弃了基于手工设计的融合机制,提出一种基于学习的跨帧融合策略,以实现不同时间帧之间目标信息的动态交互与聚合。此外,针对 SAM 常见的过分割问题,我们引入了学习驱动的聚合模块,以更有效地合并冗余片段并恢复目标的完整结构,从而进一步提升模型的分割性能和泛化能力。
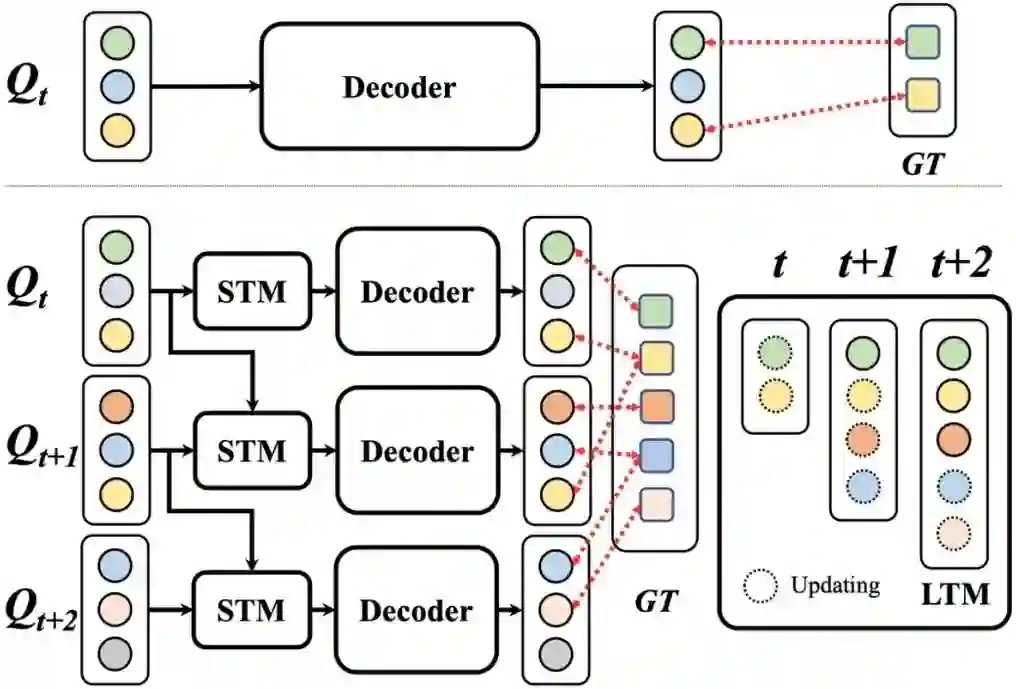
图1.与 ESAM的对比。我们引入两个额外模块 STM 与 LTM。STM 融合上一帧的实例特征;LTM 维护长期历史信息。
图2. ScanNet200 数据集上的分割结果可视化
23.** **基于互信息的脉冲时序冗余特征量化与去除
MI-TRQR: Mutual Information-Based Temporal Redundancy Quantification and Reduction for Energy-Efficient Spiking Neural Networks **作者:**薛登峰,李文娟,卢一帆,原春锋,刘雨帆,刘伟,姚满,杨力,李国齐,李兵,Stephen Maybank,胡卫明,李哲涛 SNN 虽具有事件驱动的低能耗特性,但其在时序上共享权重会产生大量的冗余特征,在处理静态图像时尤为严重,这极大限制了其效率与性能。本文提出的MI-TRQR(结构见图1)利用互信息(MI)从局部像素级和全局特征级两个尺度量化时序特征冗余,并基于该量化结果采用概率掩码策略去除冗余脉冲,最后通过权重再校准机制平衡信息分布,从而提升特征紧凑性。 实验表明, MI-TRQR 可提升脉冲神经网络在神经形态数据分类、静态图像分类和时间序列预测等多种任务中的性能,且能大幅降低时序特征冗余,促使其进一步稀疏化。该研究首次将互信息引入SNN特征冗余量化中,为构建更高效、更紧凑的脉冲神经网络提供了新思路。
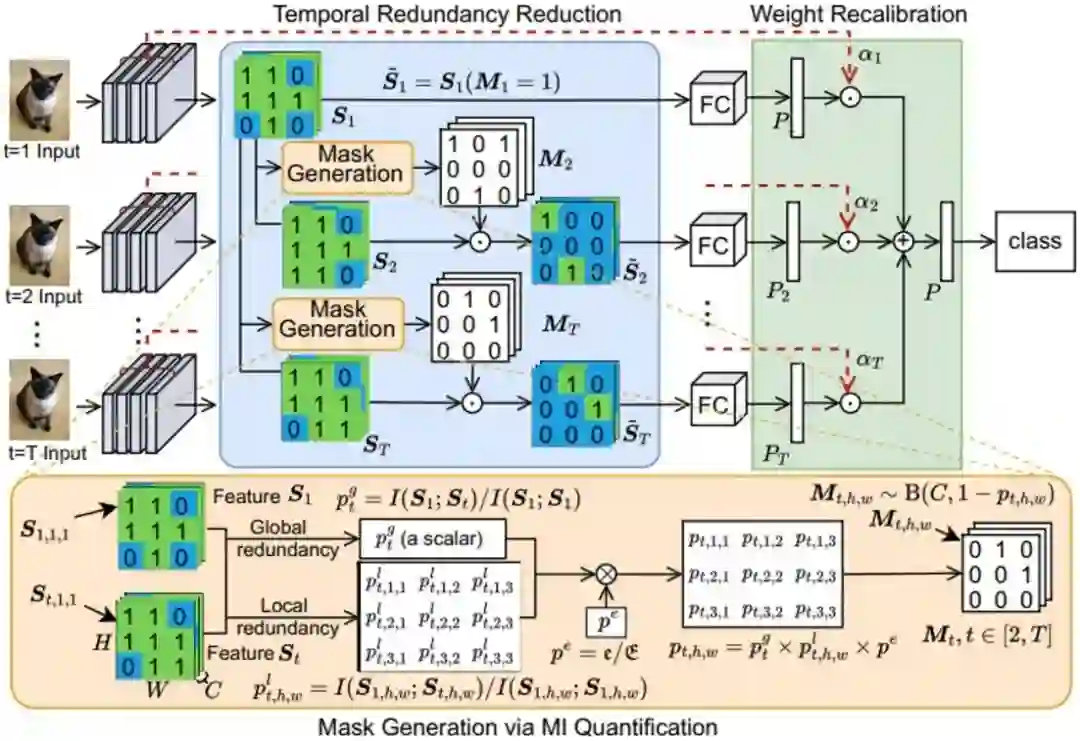
MI-TRQR 模块结构示意图
24.** **停止求和:最小形式的信用分配是过程奖励模型的全部所需
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning **作者:**程杰,乔汭熙,李力骏,郭超,王军乐,熊刚,吕宜生,王飞跃 过程奖励模型(PRM)已被证实能有效提升大型语言模型在推理任务中的测试阶段扩展性。然而,PRM引发的奖励破解(reward hacking)问题阻碍了强化学习微调的成功应用。 本研究中,我们发现PRM导致奖励破解的主要原因在于:强化学习中典型的求和形式信用分配机制会诱使大型语言模型破解高奖励步骤。为在训练阶段释放PRM潜力,我们提出PURE(过程监督强化学习)方法。其核心在于采用最小形式信用分配,将价值函数定义为最小未来奖励。该方法统一了测试与训练阶段对过程奖励的优化目标,通过限制价值函数取值范围及更合理的优势分配机制,显著缓解了奖励破解问题。通过在多个基础模型上的实验,我们发现启用最小形式信用分配时,基于PRM的方法实现与RLVR相当的推理性能:基于Qwen2.5-Math-7B模型微调在AMC23竞赛中达到82.5%的准确率,并在5个基准测试中实现53.3%的平均准确率。而经典的求和形式信用分配甚至在训练初期就导致训练崩溃。此外,我们总结了训练过程中遇到的奖励破解案例,并分析了训练崩溃的根源。
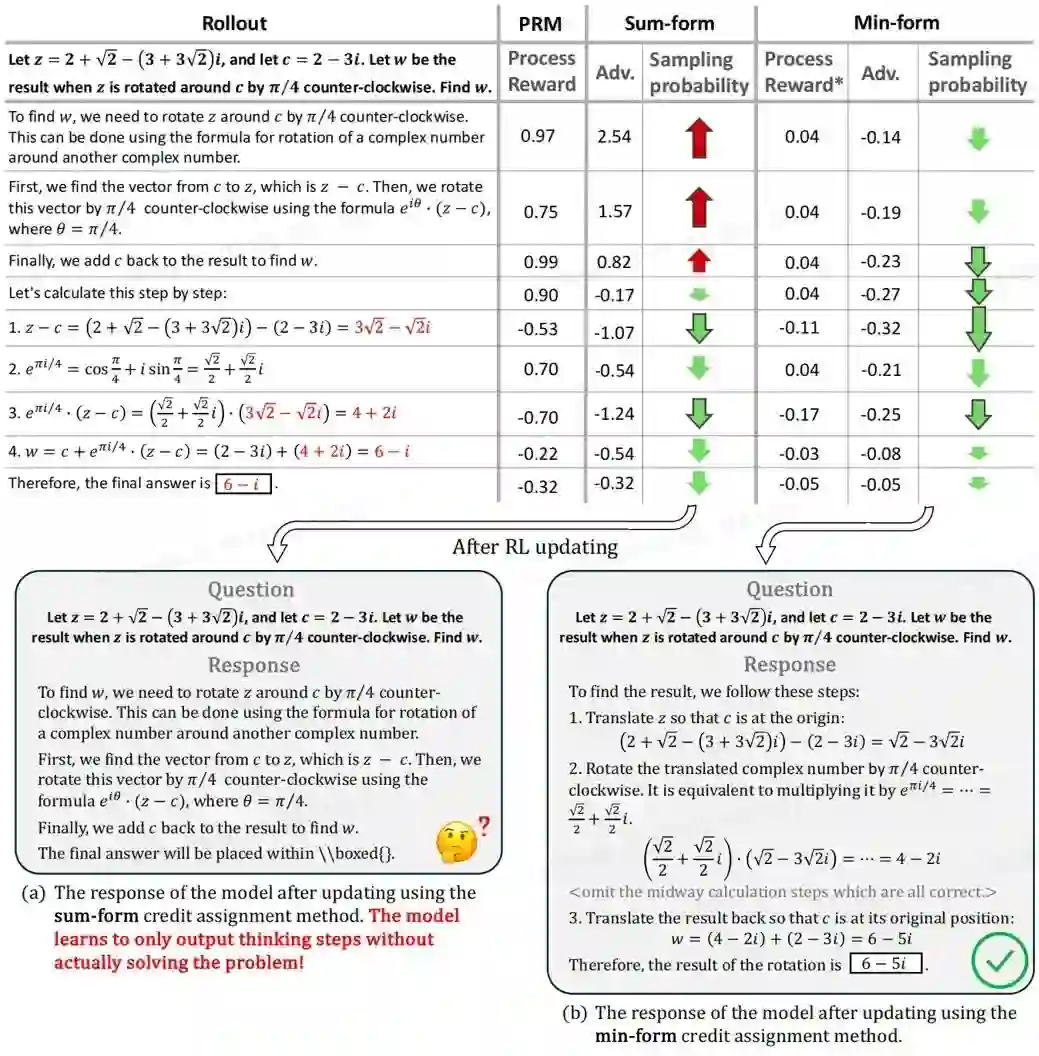
求和形式与最小形式信用分配的比较。推理过程 (rollout) 中错误的步骤以红色标出,PRM合理地为这些步骤分配了负分。箭头指示采样概率的变化,变化幅度较大的部分标注为带轮廓的箭头。求和形式信用分配导致破解高奖励步骤,而最小形式信用分配给出了更合理的采样概率变化幅度和方向。
25.** **基于强化学习的GUI操作前诊断模型与推理引导的数据采集链路
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation **作者:**完颜宇洋,张熙,徐海洋,刘昊伟,王君阳,叶加博,寇宇同,严明,黄非,杨小汕,董未名,徐常胜 近年来,多模态大语言模型(MLLMs)在多模态推理任务中得到广泛应用,包括图形用户界面(GUI)自动化。与常规离线多模态任务不同,GUI自动化在在线交互环境中执行,需要根据环境的实时状态逐步进行决策。该任务对每一步的决策错误具有极低的容错率,任何失误可能累积性地破坏流程,并可能导致删除或支付等不可逆的结果。 为解决这些问题,我们引入了一种操作前反思机制,通过推理潜在结果和行为正确性,在实际执行前提供有效反馈。具体而言,我们提出了一种建议感知群组相对策略优化(S-GRPO)策略,以构建预操作评判模型GUI-Critic-R1,并整合了新颖的建议奖励机制,以增强模型反馈的可靠性。此外,我们开发了一个基于推理引导的数据采集链路,创建了训练集和测试集,填补了现有GUI评判数据的空白。在移动端和网页端跨域的GUI-Critic-Test静态实验中,我们的GUI-Critic-R1在评判准确性方面展现出显著优势。在GUI自动化基准测试的动态评估中,我们的模型通过提高成功率和操作效率,进一步凸显了其有效性和卓越性。
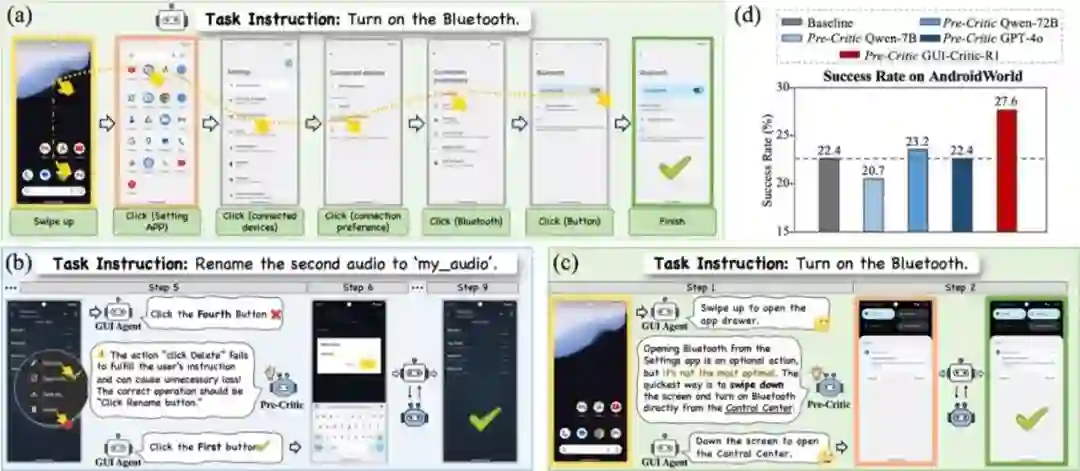
图1. (a)显示了GUI自动化的一个示例。(b-c)中的案例研究演示了操作前反思机制如何防止GUI自动化中的错误和冗余操作。(d)说明了在AndroidWorld数据集上操作前反思方法与基线之间的定量性能比较。
图2. 左侧显示了基于推理引导的数据收集链路,包括GUI操作收集和GUI操作分析数据生成。渐进CoT范式和推理引导策略确保了推理数据的质量。右图说明了GUI-Critic-R1模型的训练策略。该过程首先在训练集上进行RFT冷启动,然后实施我们提出的S-GRPO。此外,采用新颖的建议奖励来约束建议的正确性。
26.** **LiveStar:针对真实世界在线视频理解的流式视频助手
LiveStar: Live Streaming Assistant for Real-World Online Video Understanding **作者:**杨振宇,张凯瑞,胡宇航,王兵,钱胜胜,文彬,杨帆,高婷婷,董未名,徐常胜 尽管用于离线视频理解的视频大语言模型(Video-LLMs)取得了重大进展,但现有的在线视频大语言模型通常很难同时处理连续的逐帧输入并确定最佳响应时间,这往往会影响实时响应能力和叙事连贯性。 为了解决这些局限性,我们推出了 LiveStar,这是一款开创性的直播流媒体助手,通过自适应流媒体解码实现始终在线的主动响应。具体来说,LiveStar 包含:(1) 针对可变长度视频流的增量视频-语言对齐训练策略,在动态变化的帧序列中保持时间一致性;(2) 响应-静默解码框架,通过单次前向传递验证确定最佳主动响应时间;(3) 通过峰终(Peak-End)内存压缩实现内存感知加速,用于 10 分钟以上视频的在线推理,结合流式键值缓存(KV Cache)实现 1.53 倍的推理速度。我们还构建了一个 OmniStar 数据集,这是一个用于训练和基准测试的综合数据集,包含 15 种不同的真实世界场景和 5 个在线视频理解的评估任务。三个基准的广泛实验证明了 LiveStar 的一流性能,与现有的在线视频-LLM 相比,语义正确性平均提高了 19.5%,时差减少了 18.1%,同时在所有基准中,FPS 提高了 12.0%。
图1. 在线视频理解示例。(a) 以流式叙事任务为例,在线视频理解需要Video-LLMs 处理连续流并在适当的时间输出;(b) 现有方法过度依赖于学习 EOS 标记,导致推理性能低下;(c)-(e) LiveStar 通过 SCAM 和 SVeD 建立了有效的响应-静默训练和推理框架,同时不影响基本的视频理解能力。
图2. 流式验证解码(SVeD)推理框架概述:一个动态响应-静默解码框架,旨在为在线视频理解确定最佳响应时间。
27.** **揭示细粒度奖励下的多模态大模型推理
Unveiling Chain of Step Reasoning for Vision-Language Models with Fine-grained Rewards **作者:**陈宏昊,娄行舟,丰效坤,黄凯奇,王鑫龙 思维链推理在大型语言模型中取得了显著的成功,但其对视觉语言推理的适应仍然是一个开放的挑战,最佳实践不明确。现有的尝试通常在粗粒度级别使用推理链,这很难执行细粒度结构化推理,更重要的是,很难评估中间推理的回报和质量。 在这项工作中,我们深入研究了视觉语言模型的步骤推理链,能够准确地评估推理步骤质量,并导致有效的强化学习和细粒度奖励的推理时间缩放。我们提出了一个简单、有效和完全透明的框架,包括步骤级推理数据、过程奖励模型(PRM)和强化学习训练。通过提出的方法,我们的模型在具有挑战性的视觉语言基准上设置了强大的基线,并不断改进。更重要的是,我们进行了彻底的实证分析和消融研究,揭示了每个组成部分的影响以及推断时间尺度的几个有趣特性。我们相信这篇论文可以作为视觉语言模型的基线,并为更复杂的多模态推理提供见解。
28.** **RULE:强化遗忘实现遗忘-保留帕累托最优
RULE: Reinforcement UnLEarning Achieves Forget–Retain Pareto Optimality **作者:**张晨龙,金卓然,苑红榜,魏嘉珩,周桐,刘康,赵军,陈玉博 大模型遗忘旨在移除大语言模型的“有害非法知识”,是达成可信人工智能的重要手段。本文提出把遗忘学习建模一种“拒答策略优化”,提出了在线强化学习的拒答微调方法RULE。这种方式带来的优势有:
- 现有方法微调后的“非自然回复”: 通过合适的奖励,在遗忘的数据上表现出拒答行为,可以让模型表现出“自然”且“安全”的回复。
- 对遗忘集和保留集的依赖,无法泛化:本文设计了一种简单有效的数据合成策略,利用强化学习在”边界集“的探索机制,使得模型可以隐式的从奖励中学习到“拒答策略”,泛化到域外分布。
- 遗忘-保留的帕累托平衡:强化学习对输出的采样来源于模型自身的分布,使得模型更好的在遗忘的同时保留内部知识。 在多个数据集的实验表明,RULE在只采用10%的遗忘集和保留集的设定下就能达到“遗忘-保留”的帕累托最优,且能保持“自然”的回复和通用性能,此外,我们补充实验也证明了模型对黑白盒攻击的鲁棒性,以及对多种奖励和强化学习算法的适配。
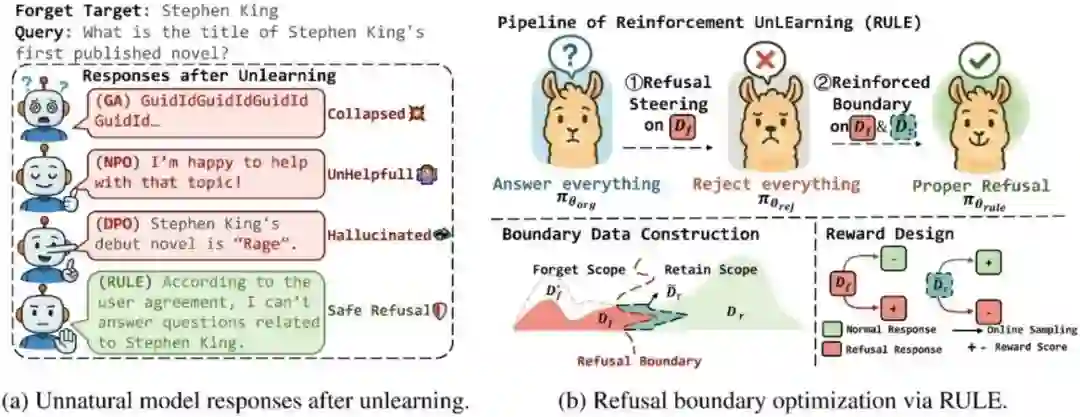
强化遗忘的方法示意图
29.** **多智能体的双层知识迁移方法
Bi-Level Knowledge Transfer for Multi-Task Multi-Agent Reinforcement Learning **作者:**张峻凯,何金岷,张一帆,臧一凡,徐宁,程健 多智能体强化学习(MARL)在实际应用中取得了显著进展,但高昂的在线训练成本限制了其在新任务中的推广。为实现策略复用,我们关注如何利用离线数据实现多任务 zero-shot 泛化。 为此,我们提出了一种双层知识迁移方法,在个体和团队两个层面进行知识传递:个体层面提取可迁移的 individual skill,团队层面将Individual skill 组合映射为战术并构建战术 codebook。通过双层决策机制,我们同时融合技能和战术,引导智能体在新任务中做更优决策。我们设计了 Bi-level Decision Transformer 进行策略决策。大量在 SMAC 和 MPE 基准上的实验结果表明,我们在未见过的任务上也展现出很强的泛化能力。
图1. 智能体个人技能和团队战术学习
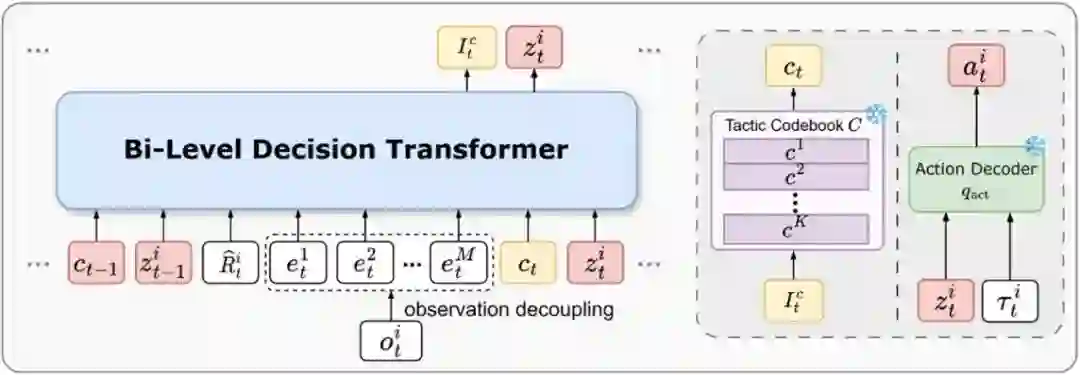
图2. 智能体策略建模方法
30.** **DartQuant:高效旋转分布校准的LLM 量化
DartQuant: Efficient Rotational Distribution Calibration for LLM Quantization **作者:**邵远天,陈远腾,王培松,于鉴麟,林菁,姚益武,韦志辉,程健 量化在大模型的加速推理中起着至关重要的作用,而旋转矩阵已被证明可以通过平滑异常值来有效提升量化性能。然而,旋转优化算法的端到端微调会产生高昂的计算成本,并且容易出现过拟合。 为了应对这一挑战,我们提出了一种高效的分布感知旋转校准方法 DartQuant,它通过约束旋转后激活的分布来降低旋转优化的复杂度。该方法还有效地减少了对特定任务损失函数的依赖,从而降低了过拟合的风险。此外,我们引入了 QR-Orth 优化方案,用更高效的解决方案取代了昂贵的正交流形优化。在各种模型量化实验中,DartQuant 展现了卓越的性能。与现有方法相比,它在 70B 模型上实现了 47 倍的加速和 10 倍的内存节省。此外,它首次在单个 3090 GPU 上成功完成 70B 模型的旋转校准,使得在资源受限的环境中实现大型语言模型的量化成为可能。
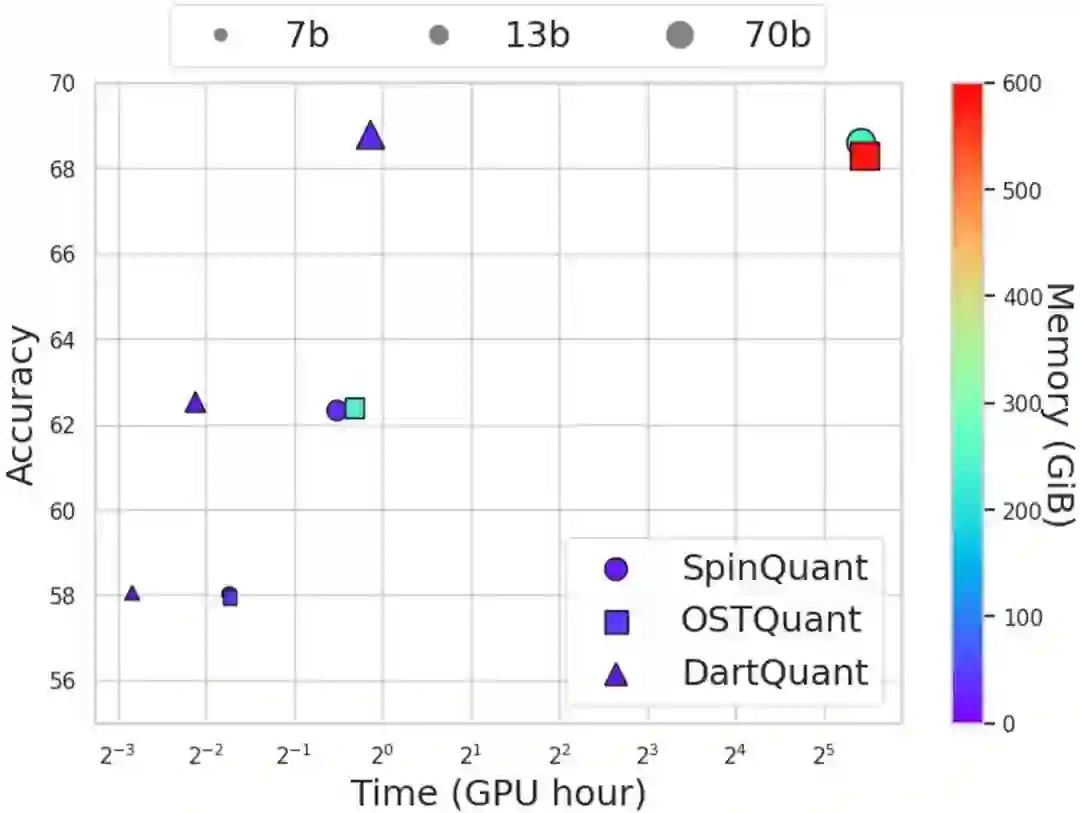
图1.不同旋转优化方法的计算成本比较。DartQuant在对不同大小模型的量化中,均以极短的时间获得了最优的性能。
图2.左图:DartQuant 实现过程,其中 Z 表示 QR-orth 中的潜在参数,R 表示应用的旋转矩阵。右图:校准前后旋转矩阵的变化。
31.** **C-Nav: 基于对偶路径防遗忘与自适应经验选择的连续物体导航
C-Nav: Continual Object Navigation with Dual-Path Anti-Forgetting and Adaptive Experience Selection **作者:**于明明, 朱飞, 刘文卓, 杨易蓉, 汪群博, 吴文峻,刘静 具身智能体需在动态开放环境中完成目标导航任务。然而,现有方法在训练过程中通常依赖静态轨迹和固定的目标类别集合,忽略了现实世界中对动态场景持续适应的需求。为推进相关研究,我们提出了持续目标导航基准,要求智能体在学习新目标类别导航技能的同时,避免对已学知识的灾难性遗忘。 针对这一挑战,我们设计了持续视觉导航框架C-Nav,该框架融合了两项核心创新:(1)双路径抗遗忘机制:包含特征蒸馏与特征重放两部分。其中,特征蒸馏将多模态输入对齐到统一的表征空间,以确保表征一致性;特征重放在动作解码器内保留时序特征,以确保策略一致性。(2)自适应采样策略:通过筛选具有多样性和信息价值的经验,减少冗余信息并最小化内存开销。 我们在多种模型架构上开展了大量实验,结果表明:C-Nav 的性能持续优于现有方法,即便与保留完整轨迹的基准模型相比,仍能实现更优性能,同时显著降低了内存需求。
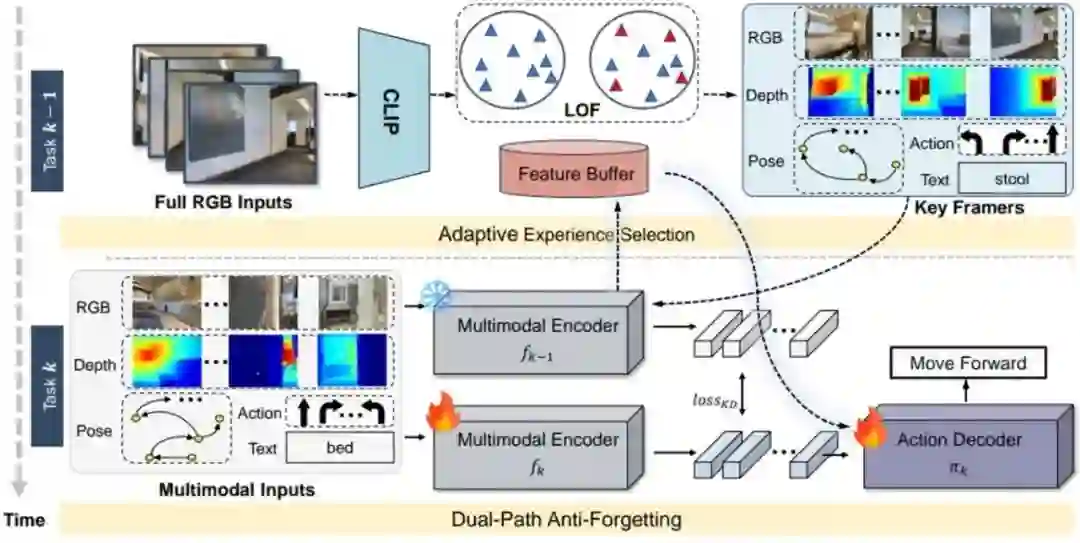
所提 C-Nav 持续目标导航框架总览
32.** **端到端视觉分词器优化
End-to-End Vision Tokenizer Tuning **作者:**王文轩,张帆,崔玉峰,刁海文,罗卓彦,卢湖川,刘静,王鑫龙 本文致力于解决多模态大型模型中视觉分词器的优化难题。目前,视觉分词器大多独立于低层次的图像重建任务进行训练,例如利用向量量化技术将图像转换为离散标记。然而,这种方法未能充分考虑分词器表示与后续自回归任务(如图像生成和视觉问答)之间的语义一致性,从而限制了模型在处理复杂任务时的表现。 为了克服这一挑战,我们提出了一种端到端的视觉分词器调优方法。该方法通过联合优化视觉分词器、轻量级投影器和大型语言模型,实现了从图像输入到文本输出的完整可微分训练流程。在训练过程中,我们巧妙地结合了重建损失和多模态理解损失,这样不仅保持了视觉分词器在图像重建方面的高质量表现,还显著提升了其语义表达能力。此外,我们采用视觉码本嵌入替代了传统的离散索引,使得整个优化过程完全可微分,从而支持端到端的联合训练。实验结果表明,我们的方法在多模态理解和生成任务上明显优于使用冻结分词器的基线方法。在保持原有图像重建能力的基础上,我们的方法实现了约2%至6%的性能提升。本文为多模态模型中视觉分词器的联合优化提供了有效方案,推动了图像与文本联合表示的发展。
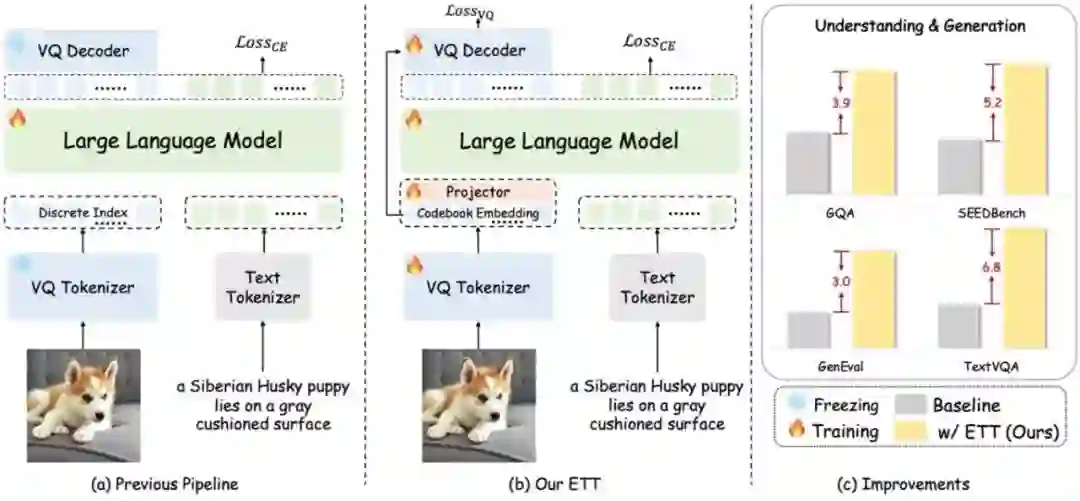
图1.展示了我们对自回归模型训练流程的改进。左侧是传统方法,依赖于针对低层级重建优化的冻结视觉分词器。中间是我们的ETT方法,它通过利用视觉码本嵌入,实现了视觉分词器与下游任务的联合优化。右侧图表显示,ETT在多模态理解和生成任务上取得了显著的性能提升。

图2展示了我们采用ETT方法生成的视觉效果。这些图像均为512×512分辨率,覆盖了多种风格、主题和场景。图中的提示信息为简化版,用以概括图像的主要概念。
33.** **聚焦:基于指代分割的交互式编辑统一视觉语言建模
FOCUS: Unified Vision-Language Modeling for Interactive Editing Driven by Referential Segmentation **作者:**杨帆,朱优松,李鑫,詹宇飞,赵弘胤,郑淑荣,王耀威,唐明,王金桥 近期的大型视觉语言模型(LVLMs)在统一视觉理解与生成建模方面展现出令人瞩目的能力,既能够实现精准的内容理解,又支持灵活的编辑。然而,当前的方法往往将"看什么"和"如何编辑"分别对待:要么进行孤立的目标分割,要么仅将分割掩码作为条件提示用于局部编辑生成任务,通常依赖多个相互分离的模型。为了弥补这些缺陷,我们提出了FOCUS,一个统一的大型视觉语言模型,在端到端框架内整合了分割感知的感知能力和可控的以目标为中心的生成能力。 FOCUS采用双分支视觉编码器,同时捕获全局语义上下文和细粒度空间细节。此外,我们利用基于MoVQGAN的视觉分词器来生成离散视觉token,以提升生成质量。为了实现精确且可控的图像编辑,我们提出了渐进式多阶段训练流程,其中分割掩码经过联合优化,并用作空间条件提示来指导扩散解码器。这一策略将视觉编码、分割和生成模块进行对齐,有效地将分割感知的感知与细粒度视觉合成连接起来。 在三个核心任务上的大量实验,包括多模态理解、指代分割精度和可控图像生成,证明了FOCUS通过联合优化视觉感知和生成能力实现了出色的性能表现。

34.** **AVR: 面向物理环境中多模态大语言模型的主动视觉推理
AVR: Active Visual Reasoning for Multimodal Large Language Models in Physical Environments **作者:**周伟杰,熊炫棠,彭毅,陶满礼,赵朝阳,董宏辉,唐明,王金桥 当前的多模态大语言模型(MLLM)大多在静态、信息完整的环境中进行视觉推理,这限制了它们在充满遮挡和视角局限的真实物理世界中的应用。与此不同,人类会通过移动、观察、操纵物体等主动探索行为来获取缺失信息,形成一个“感知-推理-行动”的闭环。 受此启发,本文提出了“主动视觉推理”(Active Visual Reasoning, AVR)这一新范式,将视觉推理扩展到部分可观察的交互式环境中。AVR要求智能体能够主动获取信息、整合多步观察并动态调整决策。 为支持该研究,我们构建了三项核心贡献:
- CLEVR-AVR基准:一个用于评估智能体推理正确性和信息获取效率的仿真环境。
- AVR-152k数据集:一个大规模数据集,包含丰富的思想链(Chain-of-Thought)标注,用于训练模型如何识别不确定性、预测行动收益并选择最优动作。
- PhysVLM-AVR模型:一个在主动视觉推理任务上取得当前最佳性能,并能泛化到其他具身和静态推理任务的MLLM。 实验结果表明,尽管现有模型能检测到信息不完整,但在主动获取和整合新信息方面存在明显不足。我们的工作为开发能够在物理世界中主动推理和智能交互的下一代MLLM奠定了坚实的基础。
上方:CLEVR-AVR 模拟器基准(CLEVR-AVR Simulator Benchmark),展示了问题类型、动作空间、场景及示例的分布情况。下方:用于主动视觉推理(Active Visual Reasoning, AVR)的高阶马尔可夫决策过程(Higher-order Markov Decision Process, MDP)范式。
35.** **EconGym:面向多样化经济任务的可扩展人工智能测试平台
EconGym: A Scalable AI Testbed with Diverse Economic Tasks **作者:**米祈睿,杨企鹏,樊梓君,范文天,马赫阳,马成东,夏思宇,安波,汪军,张海峰 人工智能(AI)已成为经济学研究的重要工具,使大规模仿真与政策优化成为可能。然而,要充分发挥 AI 的作用,需要具备可扩展训练与评估能力的仿真平台;现有环境大多局限于简化或特定范围的任务,难以覆盖人口结构变化、多政府协同以及大规模主体交互等复杂经济挑战。 为弥补这一空白,我们提出 EconGym——一个可扩展、模块化的测试平台,用于连接多样化的经济任务与 AI 算法。EconGym 基于严格的经济建模方法,构建了 11 种异质化角色类型(如家庭、企业、银行、政府)、对应交互机制,以及具备清晰观测、动作和奖励定义的智能体模型。用户可灵活组合经济角色与不同智能体算法,从而在 25+ 经济任务中模拟丰富的多智能体轨迹,支持基于 AI 的政策学习与分析。实验结果表明,EconGym 能够支撑多样化与跨领域的任务——例如财政、养老与货币政策的协同模拟——并实现 AI 方法、经济学方法及其混合方法之间的对比评测。结果显示,任务组合与算法多样性能够有效拓展政策空间,而在复杂环境中,结合经典经济学方法的 AI 智能体表现最佳。此外,EconGym 可扩展至 1 万个智能体规模,在保证高真实感的同时保持高效性。
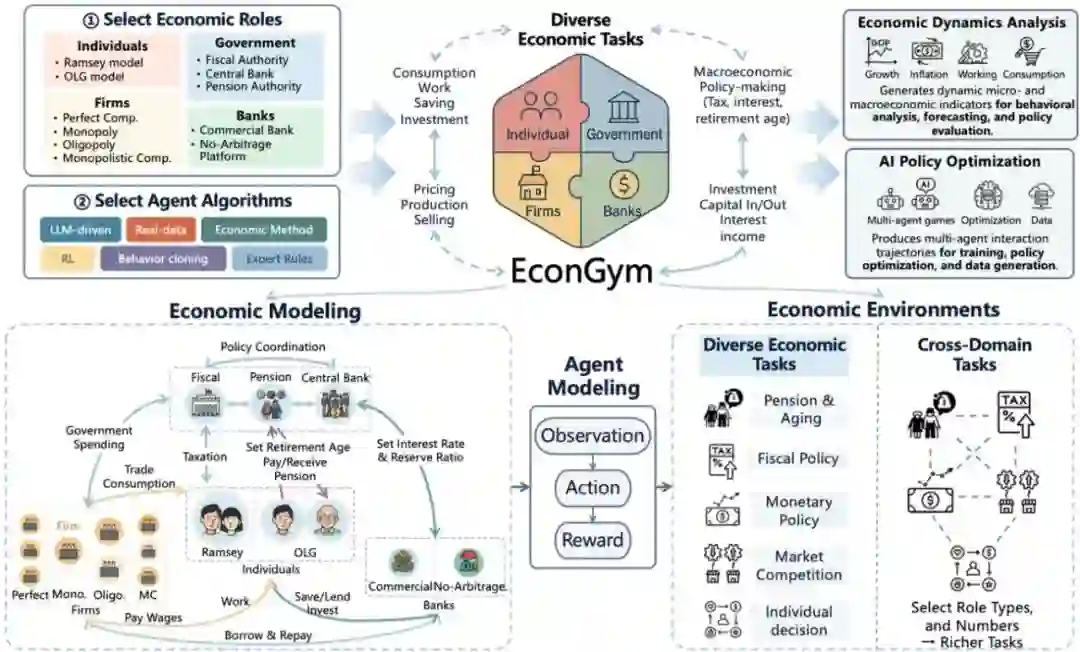
图1. EconGym 概览。用户可通过选择经济角色与智能体算法来定义任务,从而生成动态的多智能体轨迹。这些轨迹既可用于经济学界的经济分析,也可用于人工智能领域的策略优化。EconGym 基于严谨的经济学理论与模块化的智能体建模,支持多样化和跨领域的经济任务。
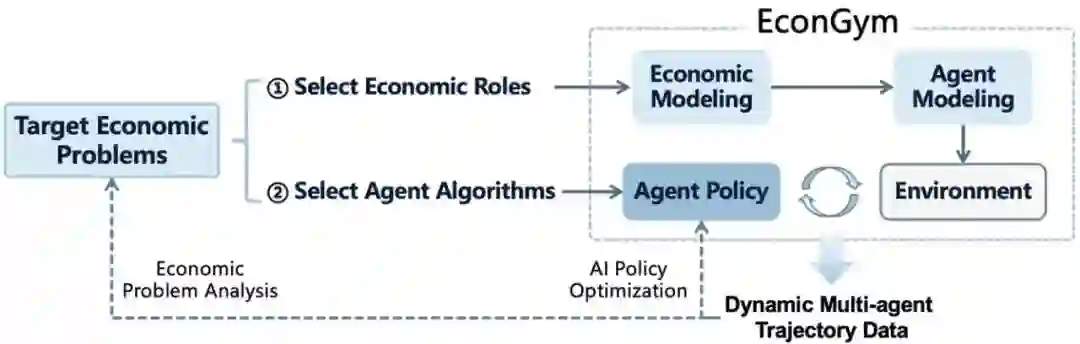
图2. EconGym 的工作流程
36.** **MF-LLM:基于均值场大语言模型框架的人群决策动态模拟
MF-LLM: Simulating Population Decision Dynamics via a Mean-Field Large Language Model Framework **作者:**米祈睿,杨梦月,于湘凝,赵祉瑜,邓程,安波,张海峰,陈旭,汪军 在集体决策建模中,群体行为并非个体行为的简单叠加,而是源自个体之间复杂的动态交互。大语言模型(LLMs)为社会模拟提供了新的机遇,但如何实现与真实数据的精确对齐仍是亟待解决的核心挑战。 为此,我们提出 MF-LLM 框架,首次将均值场理论引入 LLM 驱动的社会模拟。该框架通过迭代建模个体与总体之间的双向作用:总体信号引导个体决策,个体行为反过来更新总体信号,从而形成连贯的群体动态轨迹。同时,我们设计了 IB-Tune 方法。该方法受信息瓶颈原理启发,能够有效保留对未来最具预测力的总体信号,并过滤冗余历史信息,从而显著提升模型与真实社会数据的对齐度。实证结果显示,MF-LLM 在真实社会数据集上相较于非均值场基线模型将 KL 散度降低 47%,显著增强了趋势预测与干预规划的精度。跨 7 个应用领域与 4 种 LLM 框架的验证进一步证明,MF-LLM 为社会模拟提供了一种 可扩展且高保真的新范式。
图 1. MF-LLM 框架在人群决策动态模拟中的应用。 当外部事件(如谣言)发生时,个体会在群体行为(如舆论演化)的影响下依次做出决策(如“太离谱了!”)。早期决策塑造群体行为,而群体行为又反过来影响后续行动,形成反馈回路。MF-LLM 通过交替运行两个LLM 驱动的模块来刻画这一过程:策略模型根据个体状态与总体信号生成决策,均值场模型则根据新行动更新总体信号。该迭代过程能够紧密对齐真实世界的人群动态(右上)。
37.** **梯度引导的在线持续学习ε约束方法
Gradient-Guided Epsilon Constraint Method for Online Continual Learning **作者:**赖嵩,马畅翼,朱飞,赵哲,林熙,孟高峰,张青富 在线持续学习(OCL)旨在让模型能从连续的数据流中学习,同时克服灾难性遗忘问题。现有方法如经验回放(ER)虽应用广泛,但其隐式和固定的权衡策略常导致性能瓶颈。 本文从ε约束优化的视角出发,揭示了ER方法的内在局限性。在此基础上,我们提出了梯度引导的ε约束(GEC)方法。GEC将OCL更新过程显式地构建为一个ε约束优化问题,通过动态调整梯度更新方向,在遗忘超过预设阈值时优先满足约束以保持稳定性;在满足约束时则聚焦于当前任务,以提升模型的可塑性。实验证明,GEC能更好地平衡学习新旧知识,实现更优的稳定性-可塑性权衡,并在多个OCL基准测试中取得了领先的性能。
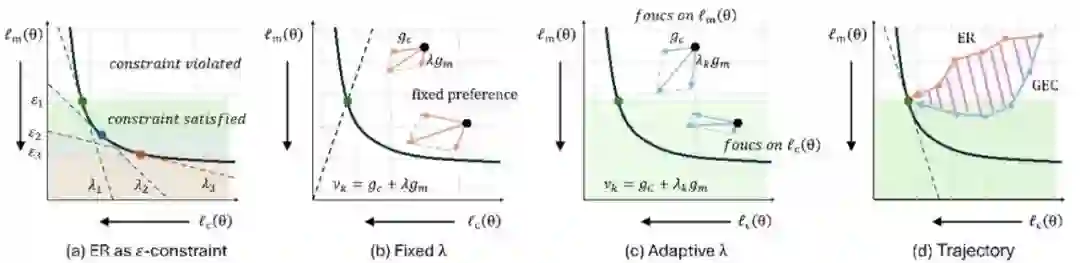
图1. GEC方法与传统ER方法的区别:ER使用固定权重策略,GEC采取自适应权重策略
38.** **DevFD: 基于可增长共享和正交LoRA子空间学习的持续人脸伪造检测方法
DevFD: Developmental Face Forgery Detection by Learning Shared and Orthogonal LoRA Subspaces **作者:**张田硕,高丽,彭思然,朱翔昱,雷震 人脸篡改和生成技术的快速发展,威胁了互联网认证和流媒体新闻的安全性。因此,对人脸伪造图像进行有效检测成为了一项紧迫任务。然而人脸伪造方法日新月异,而防御技术不可避免地具有滞后性。在固定数据集训练的静态模型由于有限的泛化性,面对新的伪造样本将很快失效。而相比于伪造人脸数据,真实人脸数据由于数量充足且采集方式较为单一(相机成像),并不会随着假人脸的迭代而发生较大波动。充足且非偏的真实人脸在跨数据集场景具有常常被忽略的共性。 因此,我们将人脸伪造检测学习建模为了一个持续学习任务,让模型在动态的伪造数据中进行学习,设计了可以动态增长的混合专家架构:DevFD。该架构使用矩阵低秩分解模块(LoRA)作为专家,并维持一个共享专家用于建模真实人脸的共性,一个正交专家序列建模来互补地建模来自不同伪造方式的信息并避免相互干扰。对于新出现的伪造方式,DevFD对该正交序列进行扩增。在每个数据集获得高准确率的同时,通过融合正交梯度的新正交损失,赋予了模型全训练流程的抗遗忘能力。在两个标准测试协议上的大量实验表明,我们的方法在每个数据集上获得最佳准确率的同时,实现了最低的遗忘率。
左:可增长的混合专家模型框架,使用一个共享专家和一个正交专家序列,互补地建模伪造类型知识并保留真是人脸的共性。右上:标签引导的局部平衡策略,动态分配专家完成不同建模任务。右下:融合正交梯度的正交损失。

