表示工程(RepE)是控制大规模语言模型(LLMs)行为的一种新兴范式。与传统方法通过修改输入或微调模型不同,RepE 直接操作模型的内部表示。因此,它可能提供更有效、可解释、数据高效且灵活的控制方式。
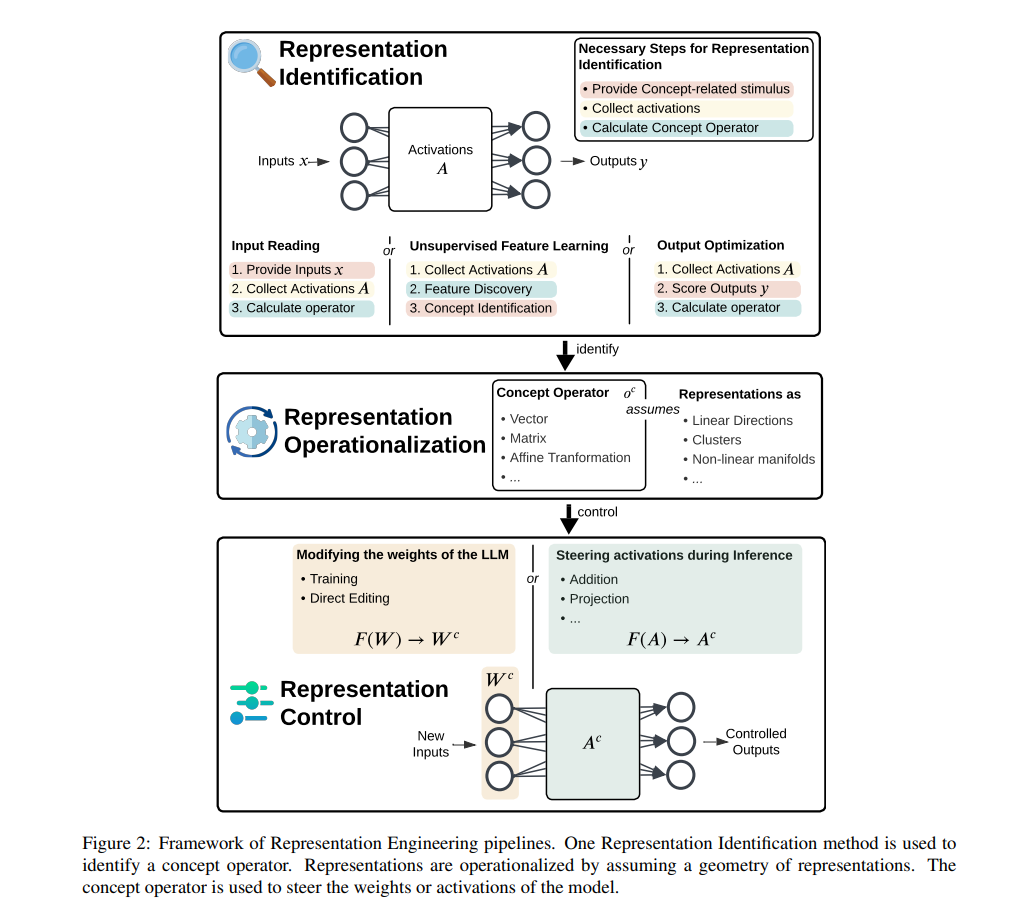
我们首次全面回顾了大规模语言模型中的表示工程(RepE),对迅速增长的相关文献进行了综述,以解决以下关键问题:有哪些表示工程方法,它们有什么区别?表示工程已应用于哪些概念和问题?与其他方法相比,表示工程的优缺点是什么?为了解答这些问题,我们提出了一个统一的框架,将表示工程描述为一个由表示识别、操作化和控制组成的流程。我们认为,尽管表示工程方法具有显著潜力,但仍面临一些挑战,包括管理多个概念、确保可靠性以及保持模型性能。为了改进表示工程,我们识别了实验和方法上的改进机会,并构建了最佳实践指南。 1. 引言
提示(Prompting)和微调(Fine-tuning)是控制大规模语言模型(LLMs)行为的常见且有效的方法。然而,最近一种新的控制LLMs的范式应运而生,受可解释性研究的启发:表示工程(RepE)。与通过调整输入或训练模型权重以产生输出的传统方法不同,表示工程通过操控模型的内部表示来控制LLMs的行为。为此,表示工程首先识别出人类可理解的概念是如何在网络的激活层中表示的。接下来,利用这些知识来引导模型的表示,从而控制其行为(见图1)。 通过利用模型的表示,RepE 提供了两个主要优势:
- 改进理解:RepE 识别出人类可理解的概念是如何在模型的激活空间中表示的;引导该表示可以验证其是否对输出产生预期的影响。
- 控制:RepE 是一种有前景的强大工具,可以控制LLM的行为、个性、编码的信念和性能,使我们能够让模型以安全和期望的方式表现。由于不需要训练,RepE 可以比其他方法更具成本效益、数据高效且灵活应对不同的用户和情况,同时对模型性能的损害较小。
早期的激活引导(Activation Steering)研究(Turner等,2024;Li等,2023a)基于这样的假设:概念在LLMs的激活空间中表现为线性方向(Park等,2024a)。这些方法关注的是对于正面或负面概念的输入激活差异。它们识别出一个捕捉模型表示概念的向量,并可以将该向量添加到新的输入激活中,从而调节概念的强度。从那时起,出现了多种新的RepE方法。例如,某些方法通过找到能导致期望输出的干预来识别表示(Cao等,2024a),或通过无监督的方式学习内部特征(Templeton等,2024)。这些方法突破了静态和线性表示(Qiu等,2024),通过使用不同的操作符而不是向量(Postmus & Abreu,2024)。它们还实验了用于引导激活的新函数(Singh等,2024),以及通过添加适配器(Wu等,2024c)来修改模型的权重。 然而,关于RepE的文献缺乏概览,存在许多未解答的问题和概念上的混淆。在本研究中,我们系统地回答以下问题:
- 什么是表示工程(RepE)? 我们首次对不同的RepE方法进行统一,提出了一个框架,将这些方法描述为识别、操作化和控制表示的流水线。
- 有哪些RepE方法,且它们有何不同? 我们讨论并对比了每个步骤中不同方法的异同。
- RepE已应用于哪些领域? 我们描述了RepE在AI安全、伦理学和可解释性等领域的应用,并展示了哪些概念更容易通过RepE进行控制。
- 与其他方法的比较如何? 我们将RepE与相关方法进行对比,并提供了RepE与微调、提示和解码方法的比较元综述。
- 为什么它有效? 我们提出了RepE为何如此有效的原因。
- RepE的优缺点是什么? 我们列出了RepE的优势与挑战。
- 未来的研究机会有哪些? 我们提出了广泛的研究主题和具体的改进思路,并概述了加强该领域的机会。
为回答这些问题,我们进行了全面的文献回顾,收集了来自100多篇论文的详细信息。尽管以往关于机制可解释性(Ferrando等,2024;Bereska & Gavves,2024)和因果可解释性框架(Mueller等,2024;Geiger等,2024a)的综述触及了RepE,但并没有针对这一研究领域的专门综述。尤其需要进行综述,因为去年发布了超过100篇相关论文,然而缺乏系统化的文献梳理。除了激活引导方法,我们还包括了通过优化输出修改权重、识别概念表示、并且不基于向量的RepE方法。我们重点讨论那些在不完全替换中间表示的情况下对模型的表示进行控制的方法,排除了软提示、解码方法和激活修补(Activation Patching)。有关纳入标准和文献检索过程的详细描述,请参见附录B。 我们得出结论,未来的工作需要建立对RepE方法的全面基准测试,以便进行深入的比较。此外,我们识别了在考虑非线性、多概念、层间或时间轨迹交互的表示方面的研究机会。进一步来说,针对新应用的改进、概念识别和控制方法的提升也存在许多有前景的方向。为了使RepE在实践中可用,我们需要在多概念引导、长文本生成、可靠性、领域外(OOD)鲁棒性和保持通用能力方面看到进一步的改进。