

1. Scaling In-the-Wild Training for Diffusion-based Illumination Harmonization and Editing by Imposing Consistent Light Transport - Rating: 9.0
通过引入一致的光传输约束扩展基于扩散的光照协调与编辑的自然场景训练
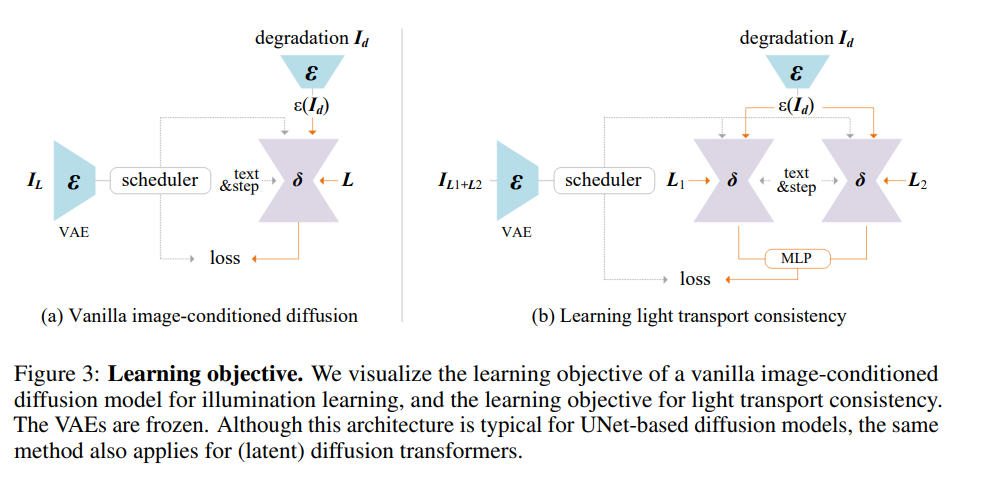
基于扩散的图像生成器正成为光照协调与编辑的独特方法。然而,在扩展基于扩散的光照编辑模型训练时,目前的瓶颈主要在于难以保留图像的底层细节和保持固有属性(如反照率)不变。如果缺乏适当的约束,直接用复杂、多样或自然场景数据训练最新的大型图像模型,可能会导致生成结构引导的随机图像,而非实现精确光照操控的目标。 我们提出了在训练过程中引入**一致光传输(Imposing Consistent Light, ICLight)**约束的方法。此方法基于物理原理:物体在不同光照条件下的外观的线性混合,与其在混合光照下的外观保持一致。这种一致性使得模型在学习光照时更加稳定和可扩展,能够统一处理各种数据源,同时促使模型行为具有物理基础,只修改图像的光照,而保持其他固有属性不变。 基于该方法,我们可以将基于扩散的光照编辑模型的训练规模扩展至大规模数据(超过 1000 万样本),涵盖所有可用的数据类型(真实光照阶段、渲染样本、自然场景的合成增强等),并使用强大的模型骨干(如 SDXL、Flux 等)。此外,我们的研究表明,该方法有效减少了不确定性并缓解了如材料不匹配或反照率变化等伪影问题。
**2. OLMoE: Open Mixture-of-Experts Language Models **
- Rating: 8.67
OLMOE:开源专家混合语言模型
我们提出了 OLMOE,一个完全开源的、基于稀疏专家混合(Mixture-of-Experts, MoE)技术的最先进语言模型。OLMOE-1B-7B 拥有 70 亿参数,但每个输入标记(token)仅使用其中的 10 亿参数。我们对其进行了预训练,使用了 5 万亿标记,并进一步调整生成了 OLMOE-1B-7B-INSTRUCT。 我们的模型在所有具有相似活跃参数量的可用模型中表现最优,甚至超越了更大规模的模型,例如 Llama2-13B-Chat 和 DeepSeekMoE-16B。我们还在 MoE 模型的训练中提出了新的发现,定义并分析了新的路由属性,显示了我们模型的高度专业化能力。 此外,我们开源了所有成果,包括:模型权重、训练数据、代码和训练日志

3. Compositional Entailment Learning for Hyperbolic Vision-Language Models - Rating: 8.0
用于双曲视觉语言模型的组合蕴涵学习
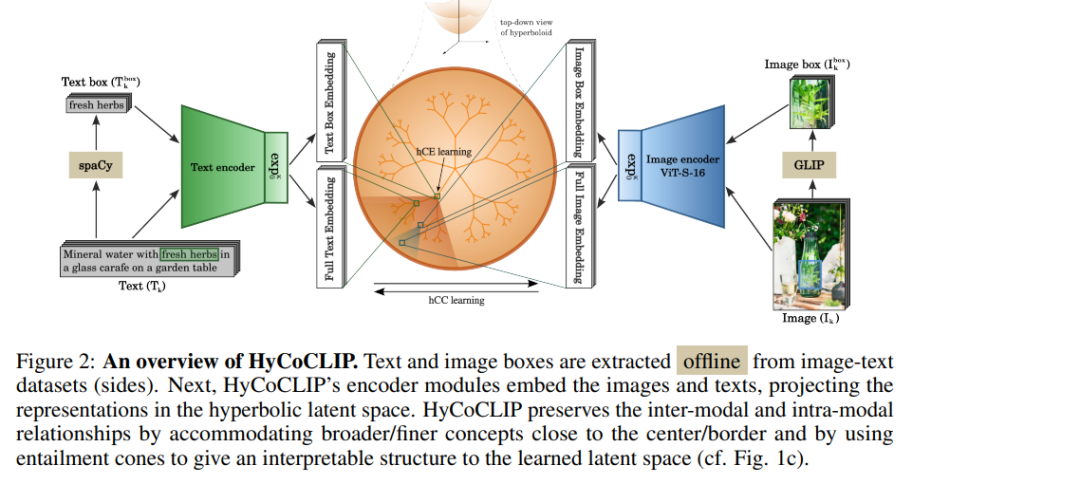
图像-文本表示学习是视觉语言模型的核心方法之一,其中图像和文本描述对在共享嵌入空间中进行对比对齐。由于视觉和文本概念本质上具有层次结构,最近的研究表明,双曲空间可以作为一种高潜力的流形,用于学习视觉语言表示,从而在下游任务中表现出色。在本研究中,我们首次展示了如何充分利用双曲嵌入固有的层次特性,超越单一的图像-文本对进行学习。 我们提出了一种用于双曲视觉语言模型的组合蕴涵学习方法。其核心思想是,一幅图像不仅可以用一句话来描述,同时本身也由多个对象框组成,每个框都有其独立的文本描述。这种信息可以通过从句子中提取名词并使用现成的定位模型自由获取。我们通过对比和基于蕴涵的目标,层次化地组织图像、图像框及其文本描述。 在使用数百万图像-文本对进行训练的双曲视觉语言模型上进行的实证评估表明,所提出的组合学习方法优于传统的欧几里得 CLIP 学习方法以及最近的双曲替代方案,在零样本任务、检索泛化能力和层次化性能方面均表现出明显优势。 代码将会公开发布。
4. The Complexity of Two-Team Polymatrix Games with Independent Adversaries
两队多矩阵博弈中具有独立对手的复杂性
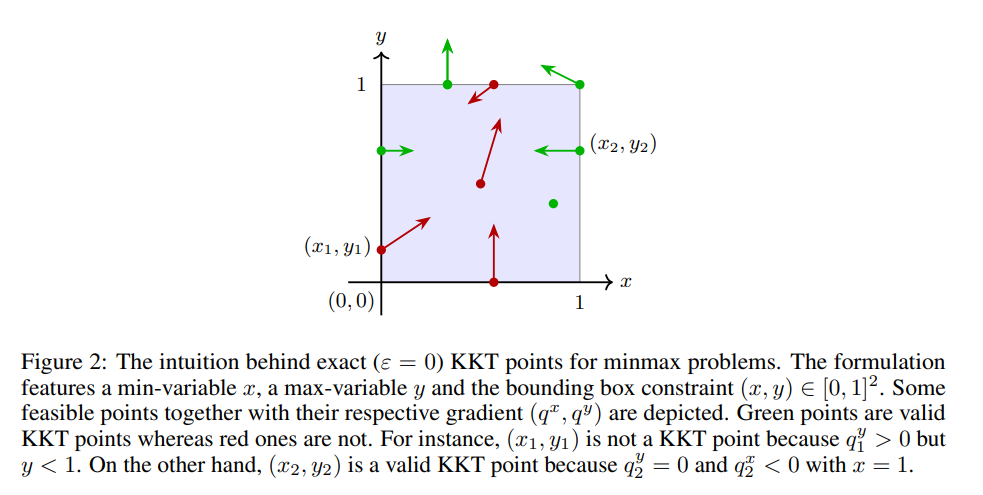
- Rating: 8.0 对抗性多人博弈是多智能体学习中一个重要的研究对象。特别地,多矩阵零和博弈是一种多人博弈设置,其中纳什均衡已知是可以高效计算的。为了理解多矩阵博弈中可计算性的界限,我们研究了这样一种博弈中纳什均衡的计算,其中每对玩家之间进行的是零和博弈或协调博弈。我们特别关注这样一种情形:玩家可以被分组为少量具有相同利益的团队。 尽管该问题的三队版本已被证明是 PPAD 完全问题,但对于两队版本的复杂性仍是一个未解问题。我们的主要贡献是证明了两队版本仍然是困难的,即它是 CLS 困难问题。此外,我们进一步证明,这一复杂性下界在某些设置中是紧的,其中一个团队由多个独立的对手组成。 在获得我们的主要结果的过程中,我们证明了在最简单的非凸-凹约束最小-最大优化问题中寻找任意平稳点的困难性,具体地,对于一类双线性多项式目标函数而言,此问题也是困难的。
5. Spread Preference Annotation: Direct Preference Judgment for Efficient LLM Alignment
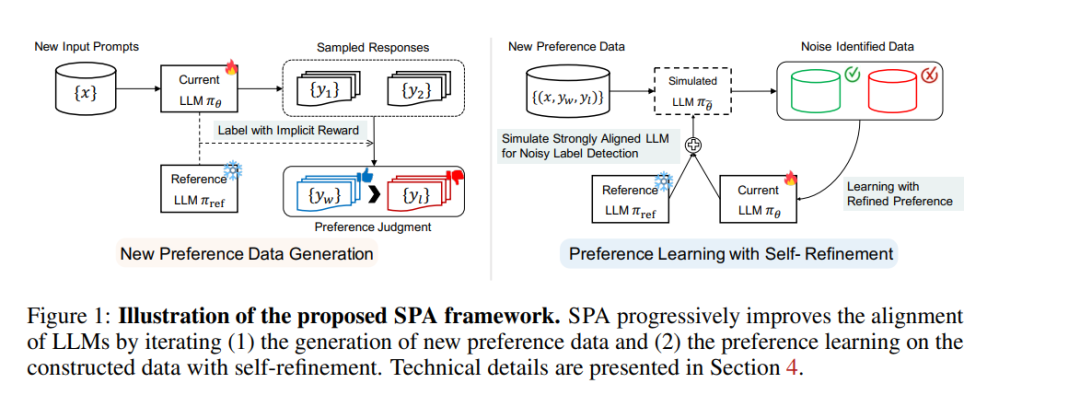
扩展偏好标注:通过直接偏好判断实现高效的大型语言模型(LLM)对齐 将大型语言模型(LLM)与人类偏好对齐是实现最先进性能的关键组成部分,但构建大规模人工标注的偏好数据集的成本非常高。为了解决这一问题,我们提出了一种新框架:扩展偏好标注(Spread Preference Annotation, SPA),通过直接偏好判断显著提高 LLM 对齐效果,同时仅需极少量人工标注的偏好数据。 我们的核心思想是利用小规模(种子)数据中的人类先验知识,通过迭代生成响应并从模型自标注的偏好数据中学习,不断改进 LLM 的对齐能力。具体来说,我们提出通过 LLM 的 logits 推导偏好标签,以显式提取模型的内在偏好。与使用外部奖励模型或隐式上下文学习的先前方法相比,我们观察到这种方法显著更有效。 此外,我们引入了一种噪声感知的偏好学习算法,以减轻生成偏好数据中低质量数据的风险。实验结果表明,该框架显著提升了 LLM 的对齐性能。例如,在 AlpacaEval 2.0 数据集上,我们仅使用 Ultrafeedback 数据中 3.3% 的真实偏好标签,就在对齐性能上超过了使用完整数据或最先进基线方法的效果。
其他高分论文: SAM 2: Segment Anything in Images and Videos - Rating: 8.0 - 92_SAM_2_Segment_Anything_in_I.pdf… Streaming Algorithms For $\ell_p$ Flows and $\ell_p$ Regression - Rating: 8.0 - https://openreview.net/pdf?id=Kpjvm2mB0K… Differential Transformer - Rating: 8.0 - https://openreview.net/pdf?id=OvoCm1gGhN… LoRA Done RITE: Robust Invariant Transformation Equilibration for LoRA Optimization - Rating: 8.0 - https://openreview.net/pdf?id=VpWki1v2P8… Spider 2.0: Can Language Models Resolve Real-World Enterprise Text-to-SQL Workflows? - Rating: 8.0 - https://openreview.net/pdf?id=XmProj9cPs… BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions - Rating: 8.0 - https://openreview.net/pdf?id=YrycTjllL0… Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risks of Language Models - Rating: 8.0 - https://openreview.net/pdf?id=tc90LV0yRL… Scaling and evaluating sparse autoencoders - Rating: 7.8 - https://openreview.net/pdf?id=tcsZt9ZNKD… Judge Decoding: Faster Speculative Sampling Requires Going Beyond Model Alignment - Rating: 7.75 - https://openreview.net/pdf?id=mtSSFiqW6y… Simplifying, Stabilizing and Scaling Continuous-time Consistency Models - Rating: 7.6 - https://openreview.net/pdf?id=LyJi5ugyJx… Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model - Rating: 7.6 - 4134_Transfusion_Predict_the_N.pdf
