本综述提供了在强化学习(RL)和机器人技术背景下,从视频中学习(LfV)方法的概览。我们关注那些能够扩展到大规模互联网视频数据集的方法,并在此过程中提取关于世界动态和物理人类行为的基础知识。这些方法对于开发通用机器人具有巨大的潜力。
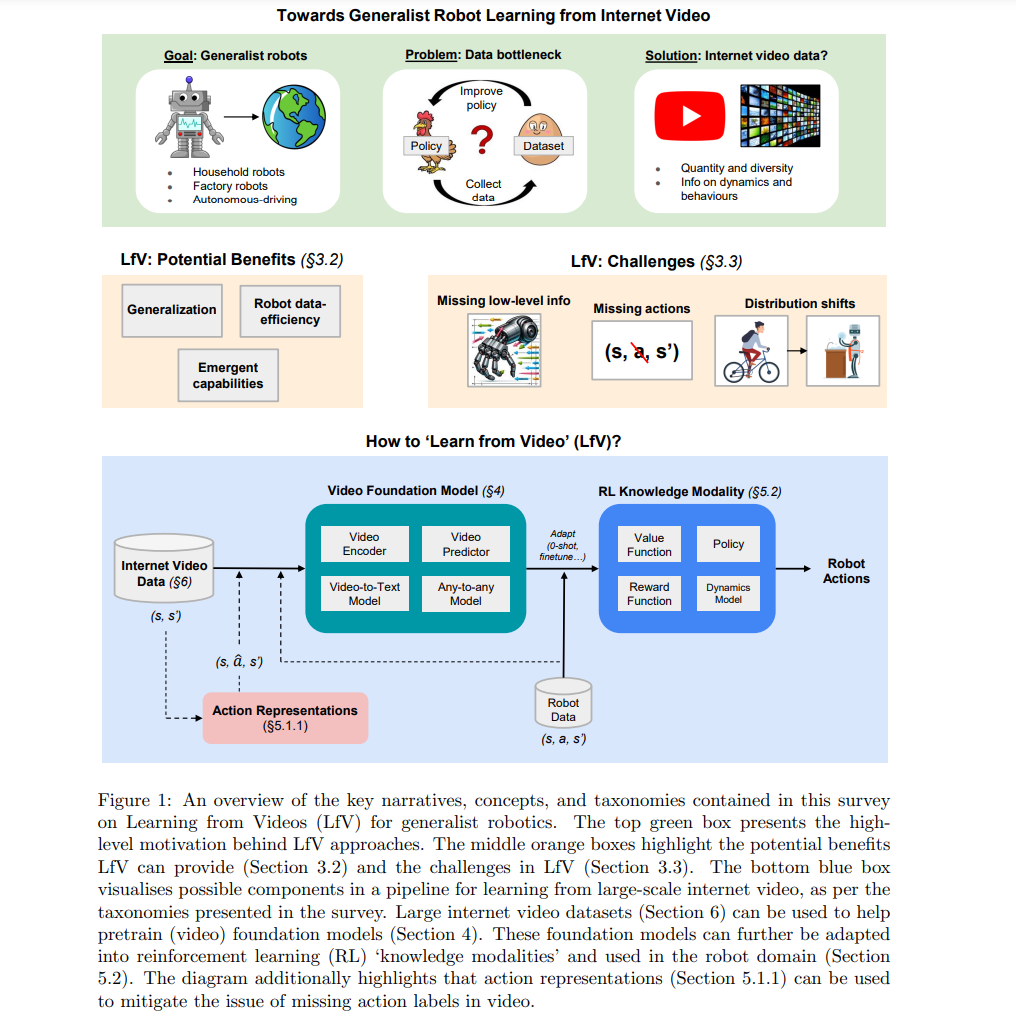
我们从相关的基础概念概述开始,这些概念与机器人学习的LfV设置相关。包括讨论LfV方法可以提供的激动人心的好处(例如,超出可用机器人数据的泛化改进)和对LfV关键挑战的评论(例如,视频中缺失信息和LfV分布偏移的挑战)。我们的文献综述从分析可以从大型、异质视频数据集中提取知识的视频基础模型技术开始。接下来,我们回顾了专门利用视频数据进行机器人学习的方法。在这里,我们根据哪种RL知识模式受益于视频数据的使用来分类工作。我们还强调了缓解LfV挑战的技术,包括回顾解决视频中缺失动作标签问题的动作表示法。
最后,我们审查LfV数据集和基准,然后通过讨论LfV中的挑战和机会来结束这篇综述。在这里,我们倡导可扩展的方法,这些方法可以利用可用数据的全部范围,并针对LfV的关键好处。总的来说,我们希望这篇综述能够成为LfV新兴领域的全面参考资料,催化该领域的进一步研究,并最终有助于通用机器人的进展。

这项调查关注的目标是获得通用型机器人。这些机器人能够在非结构化的真实世界环境中执行多种物理任务。这样的机器人将非常有用,并具有广泛的商业应用(例如,家庭机器人、工厂机器人或自动驾驶)。然而,通用机器人设置面临几个挑战。首先,通用机器人必须具备高水平的能力,这包括从高级能力(例如,推理和计划)到基础技能(例如,灵巧和技能)的维持。其次,为了在非结构化环境中操作,通用机器人必须依赖不完整的部分观察(例如,视觉和触觉感知)来感知世界。
我们如何获得这样的机器人?传统的机器人技术不足以应对,因为它们通常依赖于手工制作的物理模型理想化,并且通常无法处理非结构化和未见过的场景[Krotkov et al., 2018]。相比之下,机器学习(ML)技术更具前景,并且在机器人学中的使用日益增多,从而引入了机器人学习这一术语[Argall et al., 2009; Peters et al., 2016; Kroemer et al., 2021; Ibarz et al., 2021]。现在,普遍认为机器学习的进步是由数据、算法和计算能力的提升驱动的。幸运的是,计算成本正在持续降低[Moore, 1998; Mack, 2011],且最近开发出了高效的算法——包括表现力强的深度学习架构,如变压器[Vaswani et al., 2017]和扩散模型[Ho et al., 2020]——其性能随着计算和数据的增加而持续和可预见地提高[Kaplan et al., 2020]。将这些算法与从互联网抓取的大规模、多样化数据集结合,已经在语言理解和生成[OpenAI, 2023]、图像生成[Betker et al., 2023],以及最近的视频生成[Brooks et al., 2024]方面取得了显著的进步。
有希望的是,这些深度学习方法可以转移到机器人学[Brohan et al., 2022; Team et al., 2023b]。然而,与其他领域不同的是,机器人学缺失了成功所需的关键成分:适当的大型多样化数据集。实际上,机器人学面临一个先有鸡还是先有蛋的问题。首先,由于我们的机器人能力有限,我们无法轻易收集现实世界的机器人数据。这些有限的能力意味着部署机器人来收集数据可能是低效和危险的。随后,由于缺乏数据,我们无法轻易改进我们的机器人。因此,可以说,数据目前是机器人学进步的关键瓶颈。 我们如何克服这个数据瓶颈?为了提供潜在解决方案的见解,我们现在简要讨论机器人学的主要数据来源。1)真实机器人数据:这是我们想要的确切数据。通过高质量的真实机器人数据,可以使用监督学习或离线强化学习(RL)来训练我们的机器人控制策略。然而,无论是通过人类远程操作还是自动策略,收集现实世界的机器人数据都是昂贵且困难的。2)模拟机器人数据:与现实世界数据收集相比,模拟收集的速度明显更快、成本更低[Kaufmann et al., 2023a]。然而,模拟带来了一些问题。模拟物理可能不准确。此外,创建适合训练通用政策的多样化模拟环境和任务并非易事。此外,我们仍然通常缺乏能够收集模拟数据的自动策略。3)互联网数据:互联网是一个庞大而多样化的数据来源。它为近期深度学习的进展奠定了基础[OpenAI, 2023; Betker et al., 2023]。互联网文本、图像和视频数据包含了大量与通用型机器人相关的信息。然而,互联网数据并非直接或轻易适用于机器人学。这是由于互联网数据与机器人领域之间的分布偏移,以及互联网数据中关键信息的缺失(例如,文本不包含视觉信息,而视频不包含动作标签)。 鉴于其丰富的数量和相关内容,互联网视频数据有助于缓解机器人技术中的数据瓶颈问题,并推动创建通用型机器人的进程。更具体地说,我们希望从互联网视频中获得以下好处:(1)提高超出可用机器人数据的泛化能力;(2)提高机器人数据的数据效率和分布内性能;(3)推测性地获得仅凭机器人数据无法实现的新兴能力。事实上,从视频中学习(LfV)这一新兴领域的最近进展令人鼓舞,证明了这些好处。这包括利用大规模视频预测模型作为机器人动态模型的工作[Yang等人,2023c; Bruce等人,2024],或利用机器人数据和互联网视频训练基础机器人政策的工作[Sohn等人,2024]。 然而,将互联网视频用于机器人技术带来了一些基本和实际挑战。首先,一般来说,视频是一个具有挑战性的数据模式。视频数据是高维的、噪音大的、随机的,并且标记不佳。这些问题使得视频基础模型的进展落后于语言和图像模型。其次,特别是为机器人技术使用视频数据引入了自己的一套问题。视频缺乏对机器人至关重要的信息,包括明确的动作信息和低级信息,如力和本体感知。此外,互联网视频与下游机器人设置之间可能存在各种分布偏移,包括环境、实体和视角的差异。鉴于这些挑战,我们提出了两个关键的LfV研究问题:
如何从互联网视频中提取相关知识?
如何将视频提取的知识应用于机器人技术?在本综述中(见图1),我们回顾了试图回答这些问题的现有文献。对于第一个问题,我们调查了从大规模互联网视频中提取知识的视频基础建模技术,这些技术有望成为未来LfV进展的关键驱动力。对于第二个问题,我们进行了彻底的文献分析,这些文献利用视频数据帮助机器人学习。我们根据强化学习知识模式(KM)(即哪些表示、政策、动态模型、奖励函数或价值函数)直接受益于视频数据的使用来分类这些文献。此外,我们还回顾了用于缓解LfV挑战的常见技术,如使用动作表示来解决视频中缺失动作标签的问题。
我们通过讨论未来LfV研究的问题和机会来结束。这包括倡导可扩展的方法,这些方法可以最好地提供LfV的承诺好处。在此,我们建议针对政策和动态模型KM。此外,我们还讨论了利用视频基础模型技术进行LfV的方向,然后触及克服关键LfV挑战的方向。
这些有前景的机会,加上近期在LfV方面的鼓舞人心的进展[Yang等人,2023c; Bruce等人,2024],强烈表明LfV的承诺好处是完全可以实现的。我们希望这份全面的综述能鼓励和通知未来的LfV研究,最终有助于加速我们创建通用型机器人的进程。