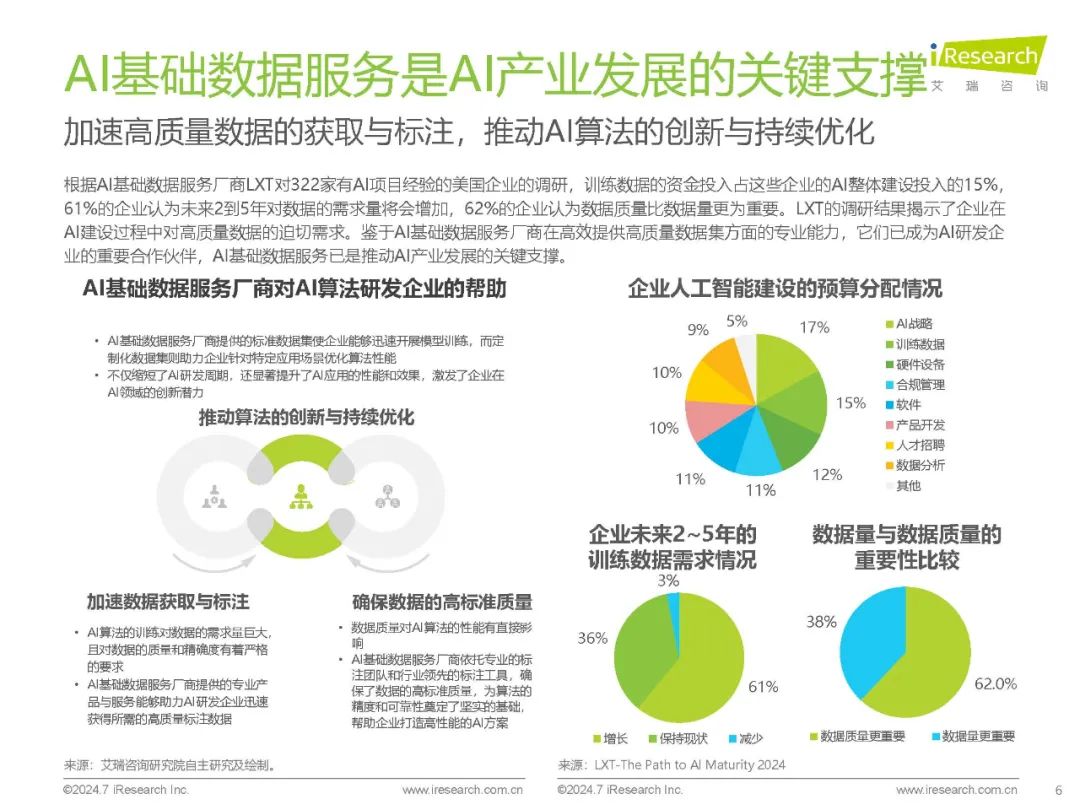
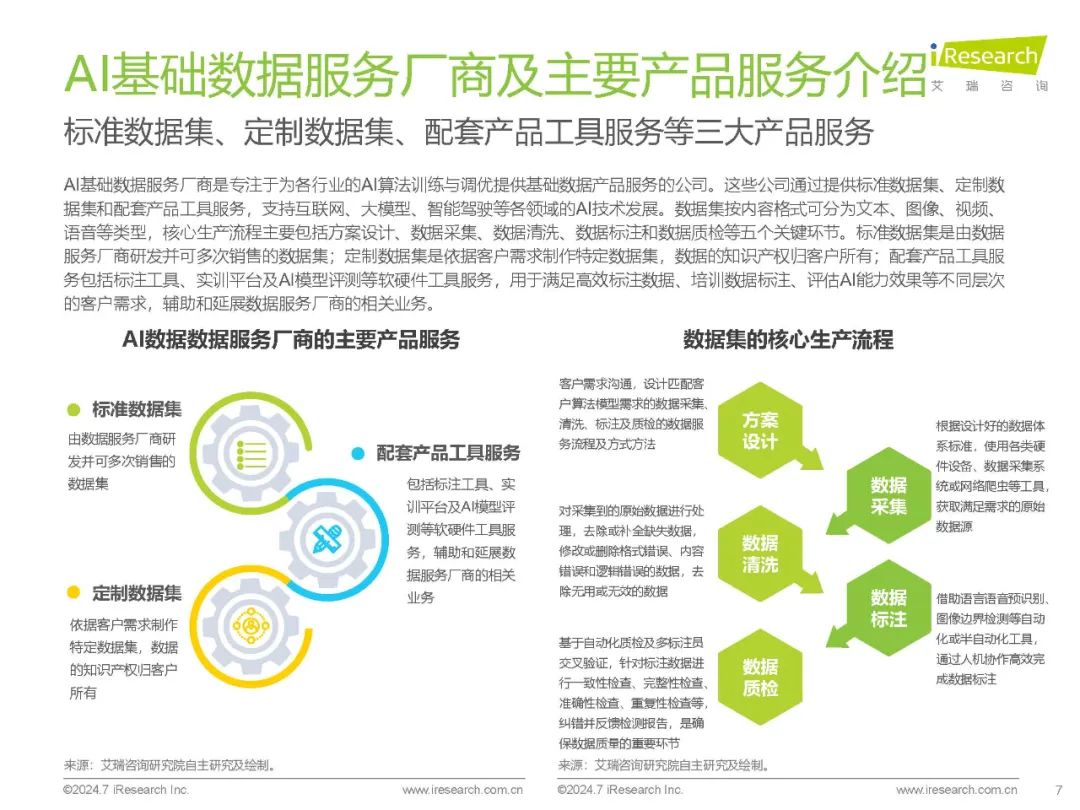
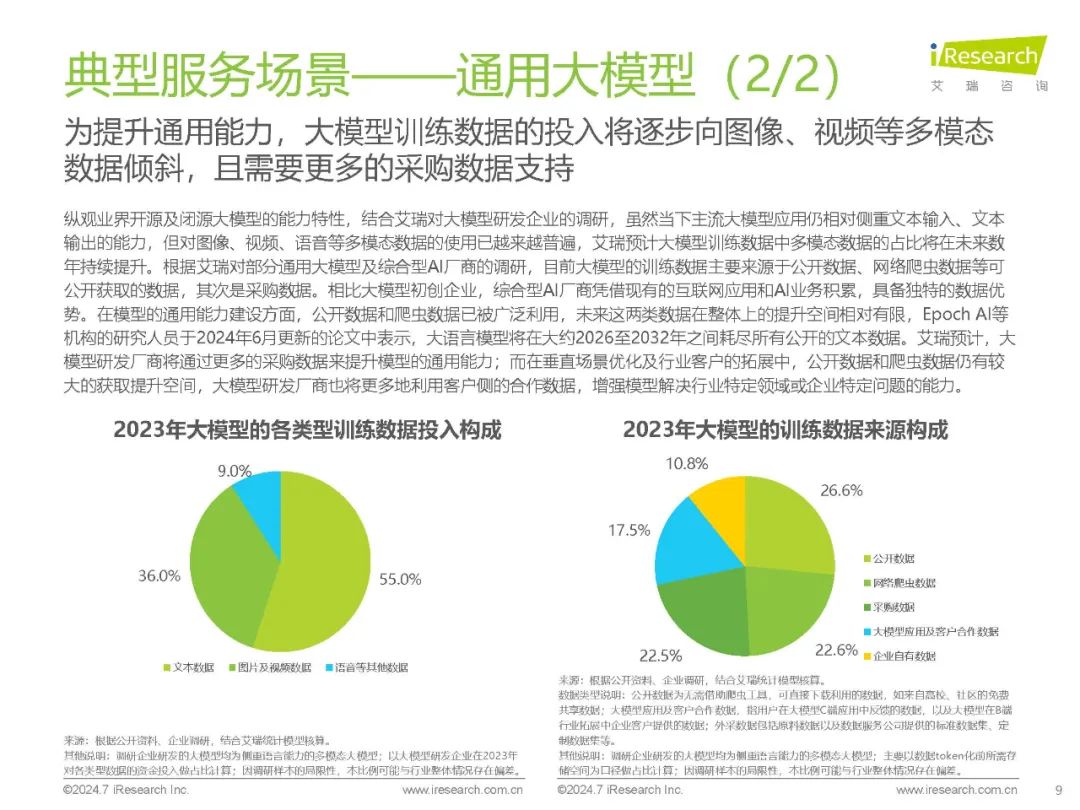
多模态、长文本、大模型小型化成为热点研究方向 在过去几年里,大众已见识到GPT、BERT等大语言模型在自然语言理解和生成方面的卓越能力。相比单一模态的大模型,多模态大模型能够提供更自然的人机交互方式,具备更全面和准确的认知能力,并在不同情境下表现出更高的鲁棒性,从而赋能更丰富和全面的AI应用。因此,多模态技术已成为诸多大模型厂商的研发重点。此外,长文本处理能力的提升,使大模型在理解和生成复杂文档方面表现更佳,能够更好地支持多主题和多步骤的推理任务;通过知识蒸馏、模型剪枝和混合精度训练等技术,大模型得以小型化,减少了计算资源需求,提高了推理效率,使大模型在资源受限设备上高效运行,提升了响应速度和用户体验,保护了用户的数据隐私。聚焦国内AI商业化市场,大模型商业化进程加速,API市场竞争激烈,价格战频现,但同时也反映出供应商间能力同质化的问题,亟需破局;另一方面,央国企凭借较好的数字化基础、丰富的数据资源及业务场景、相对充足的科技投入预算,成为现阶段国内大模型项目建设的主力军,推动了大模型在中国AI产业的商业化落地。 数据、算法、算力是构建AI的三大要素 数据、算法、算力的协同促使现代AI技术实现了从理论到应用的飞跃 在人工智能领域,数据、算法和算力是构建AI系统的三大核心要素,三者的协同使现代AI技术实现了从理论到应用的飞跃。数据是AI的基础,大量高质量的数据不仅能够提高现有模型的准确率,还能促进模型的优化和创新。以ImageNet数据集为例,该数据集及相关挑战赛推动了计算机视觉算法的快速发展,2017年是挑战赛的最后一年,物体分类冠军的准确率在7年时间里从71.8%上升到97.3%。近年来,Transformer等预训练大模型在语言理解及生成等领域表现出色,大模型背后的ScalingLaw(规模定律)进一步揭示了模型性能与数据量、算力之间的关系,强化了数据在提升AI表现中的关键作用。