近年来,随着交互媒体、扩展现实(XR)以及元宇宙等产业的智能化升级,对三维内容的需求呈指数级增长。为克服传统手工建模方法中存在的流程繁琐、生产周期长等问题,三维表示范式的创新与人工智能生成技术的融合带来了革命性的进展。本文对静态三维物体与场景生成领域中的前沿研究成果进行了系统综述,并通过体系化的分类建立起一套完整的技术框架。具体而言,我们首先介绍主流的三维物体表示方式,随后深入探讨两类核心的物体生成技术路径:基于数据驱动的监督学习方法与基于深度生成模型的方法。在场景生成方面,我们聚焦于三种主流范式:基于布局引导的组合式合成、基于二维先验的场景生成以及基于规则驱动的建模方式。最后,本文还深入剖析了当前三维生成面临的挑战,并提出了未来可能的研究方向。我们希望本综述能够为读者提供对三维生成技术的结构化理解,并激发研究者在该领域开展更深入的探索。
1 引言
几十年来,自动内容生成技术经历了显著的发展。早期,基于规则的建模方法(如L系统 [1] 和过程形状文法 [2, 3])在创建具有规则性和重复性结构的物体与场景方面表现出较高的效率。尽管这些方法能够快速生成具有复杂几何结构和纹理细节的三维内容,但其规则和文法的设计过程十分繁琐,直到2010年代,神经网络和深度学习在计算机视觉领域引发革命性变革后,情况才发生了改变。Guo 等人 [4] 首次将深度学习用于发现原子结构,从输入图像中提取规则并将其转换为L系统,从而实现了逆向程序化建模。CropCraft [5] 则通过逆向程序化建模优化植物形态参数,从图像中生成作物的网格表示。随着深度学习技术的不断突破,生成式人工智能在二维内容生成领域取得了革命性进展:以 DeepSeek [6] 为代表的文本解析与生成模型,以 Imagen [7] 和 GPT-4o [8] 为代表的文本生成图像技术,均展现出卓越性能。
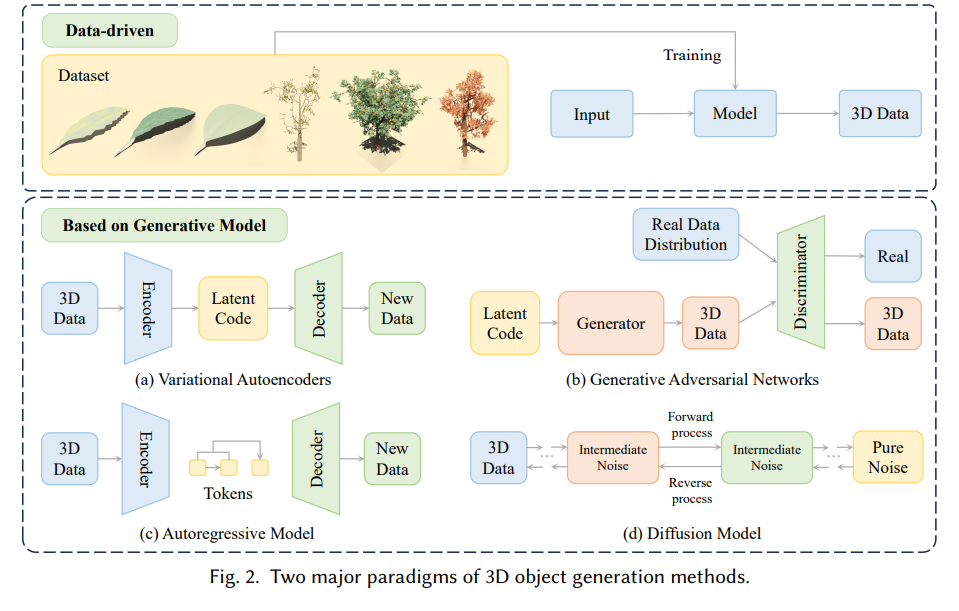
在元数据技术迅猛发展的背景下,三维内容生成作为二维技术的自然延伸,正受到广泛关注。然而,其发展仍面临诸多挑战。维度的提升使得将显式三维表示有效融合到神经网络结构中变得更加复杂。同时,基于隐式神经辐射场(Neural Radiance Fields, NeRF)[9] 的新型渲染技术,在将生成内容直接应用于传统光栅化图形流水线时也面临适配困难。此外,缺乏高质量三维资产数据集,也显著增加了模型训练的难度。 尽管如此,三维内容生成领域仍取得了一系列突破性成果。例如,Point-E [10] 构建了百万级三维模型与文本配对数据集,用于训练点云扩散模型,从而实现文本到三维点云的生成。诸多方法 [11–18] 将三维隐式表示集成进深度生成模型,并通过算法 [19, 20] 提取显式网格。DreamFusion [21] 首次提出利用二维生成先验监督三维表示优化的新范式,为后续研究奠定了新方向。同时,研究方法 [22–28] 充分利用大语言模型(LLMs)强大的文本解析能力,从自然语言描述中提取场景特征用于布局构建。RGBD2 [29] 则通过二维图像先验构建场景的网格表示。Raistrick 等人 [30] 提出的参数化生成框架,基于数学规则实现了自然资源的无限组合生成。
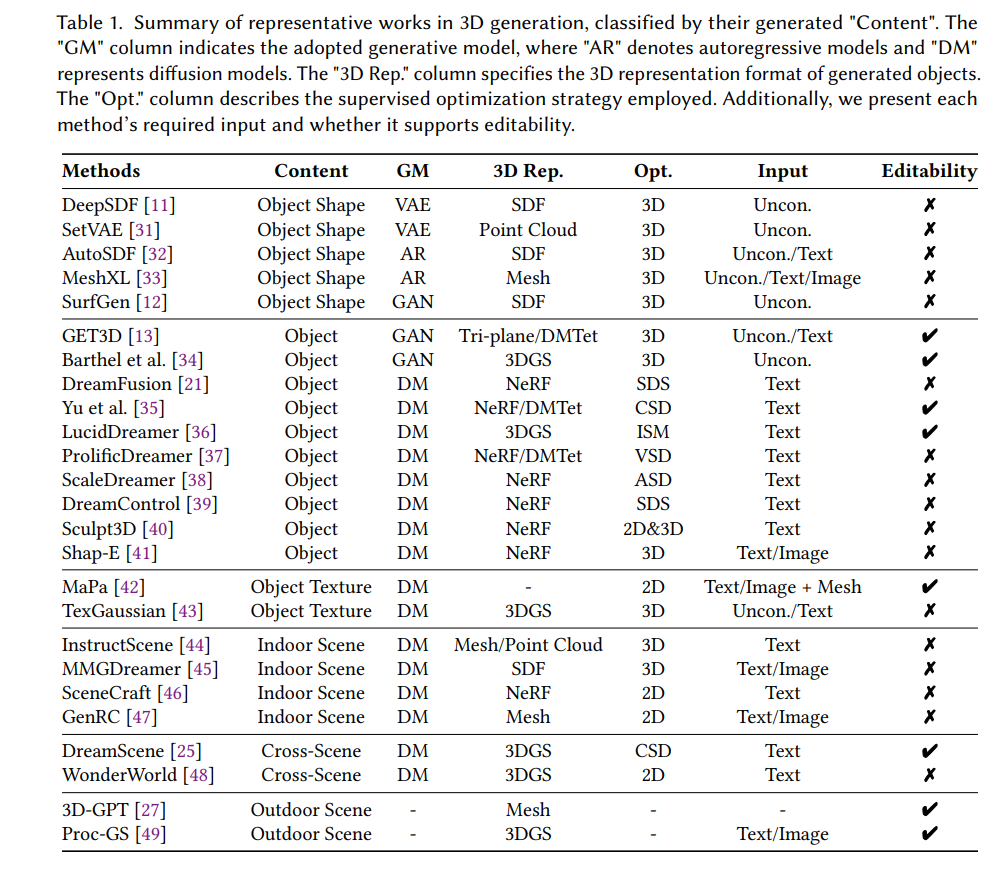
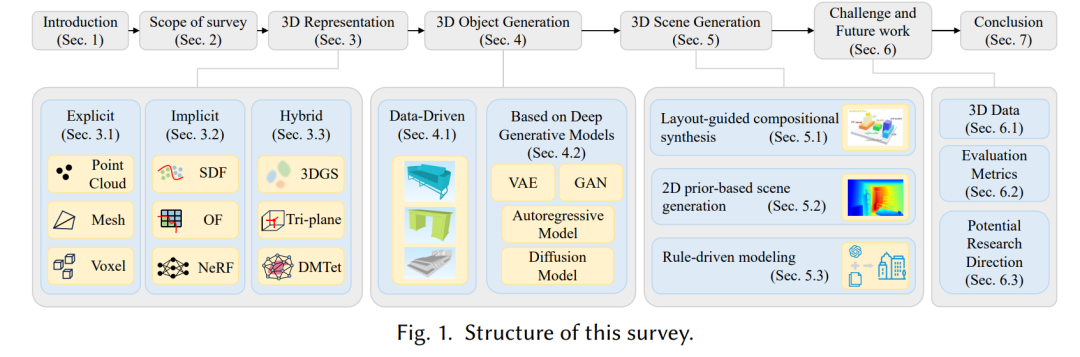
因此,本文旨在系统梳理三维内容生成领域的相关研究,归纳其技术路线并进行分类总结。如表1所示,我们对近年来代表性工作进行了结构化整理,聚焦于三维表示、三维物体与场景的生成方法。 如图1所示,本文在第二节界定研究范围并介绍相关工作;第三节介绍三维表示的基本理论,分析其优势、局限性及与生成框架的融合方式。随后,我们将三维内容生成任务划分为物体级与场景级两个层面。第四节从公开数据集出发,介绍基于数据驱动的生成方法,随后探讨其如何随着深度生成模型的发展,扩展到三维生成领域并形成独特的技术范式。第五节聚焦于场景生成,我们从理论角度将相关方法分为三类:基于布局或场景图的多物体组合生成、基于二维图像空间信息直接提取场景表示的方法,以及具有可控细节的规则驱动建模方法。代表性工作的时间线图分别展示于附录图5与图6中。最后,第六节指出当前领域所面临的关键挑战,并提出未来可能的研究方向。本文希望通过本综述为研究人员提供技术参考,并激发后续的深入探索。 我们的主要贡献可总结如下:
提出了一种新颖的分类方法,将三维内容生成划分为物体生成与场景生成两个子任务,并分别对其技术路径进行了系统性总结与归纳; 全面回顾了近五年内的大量研究文献,着重融合了最新研究成果,全面呈现技术演进轨迹与前沿发展动态。