
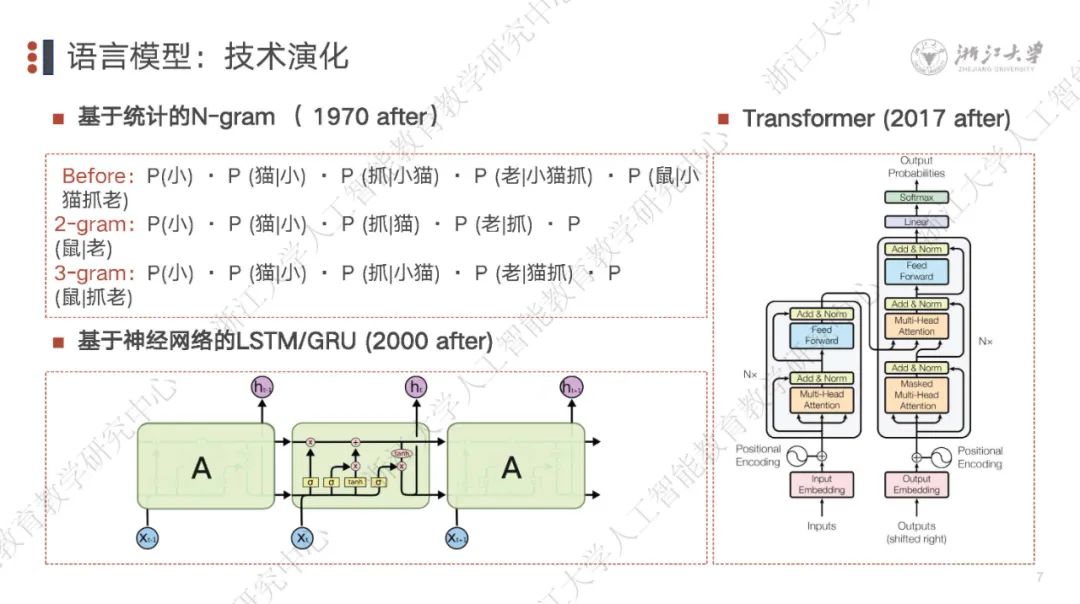
Transformer:理论架构创新 自注意力机制:支持并行计算/全局上下文的理解能力 多头注意力:从多个角度捕捉复杂的语义关系 前馈网络/位置编码/层归一化:解决了传统模型的诸多局限性 人工智能 自监督学习(语言) MaskedLangaugeModeling(MLM)模型会不断地在句子中‘挖去’一个单词,根据剩下单词的上下文来填空,即预测最合适的‘填空词’出现的概率,这一过程为‘自监督学习’ 自监督学习(图像) MaskedAutoEncoders(MAE)通过随机遮盖部分输入数据(如图像)并重建缺失内容,让模型从上下文中学到图像的深层特征,常用于计算机视觉任务。 数据:训练中使用了45TB数据、近1万亿个单词(约1351万本牛津词典所包含单词数量)以及数十亿行源代码。 模型:包含了1750亿参数,将这些参数全部打印在A4纸张上,一张一张叠加后,叠加高度将超过上海中心大厦632米高度。 算力:ChatGPT的训练门槛是1万张英伟达V100芯片、约10亿人民币。 大数据、大模型、大算力下以“共生则关联”原则实现了统计关联关系的挖掘。 





成为VIP会员查看完整内容
相关内容

Arxiv
203+阅读 · 2023年4月7日
Arxiv
23+阅读 · 2021年9月20日
相关主题



相关VIP内容
相关资讯
相关论文
Arxiv
203+阅读 · 2023年4月7日
Arxiv
23+阅读 · 2021年9月20日