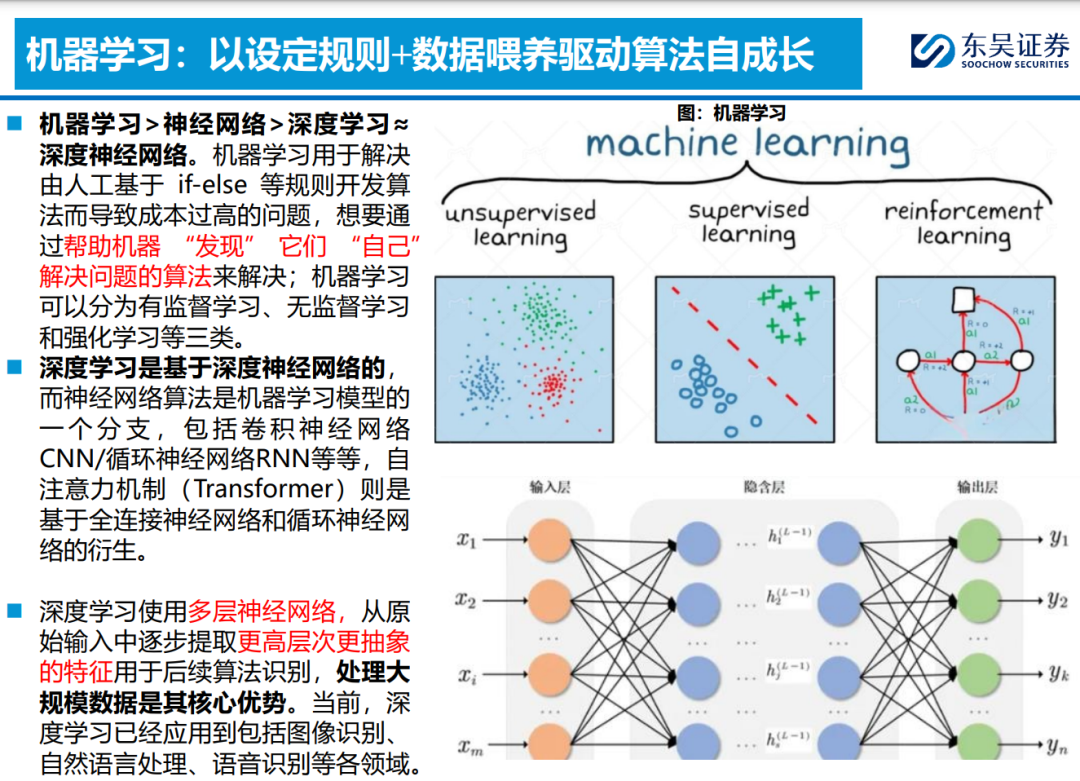
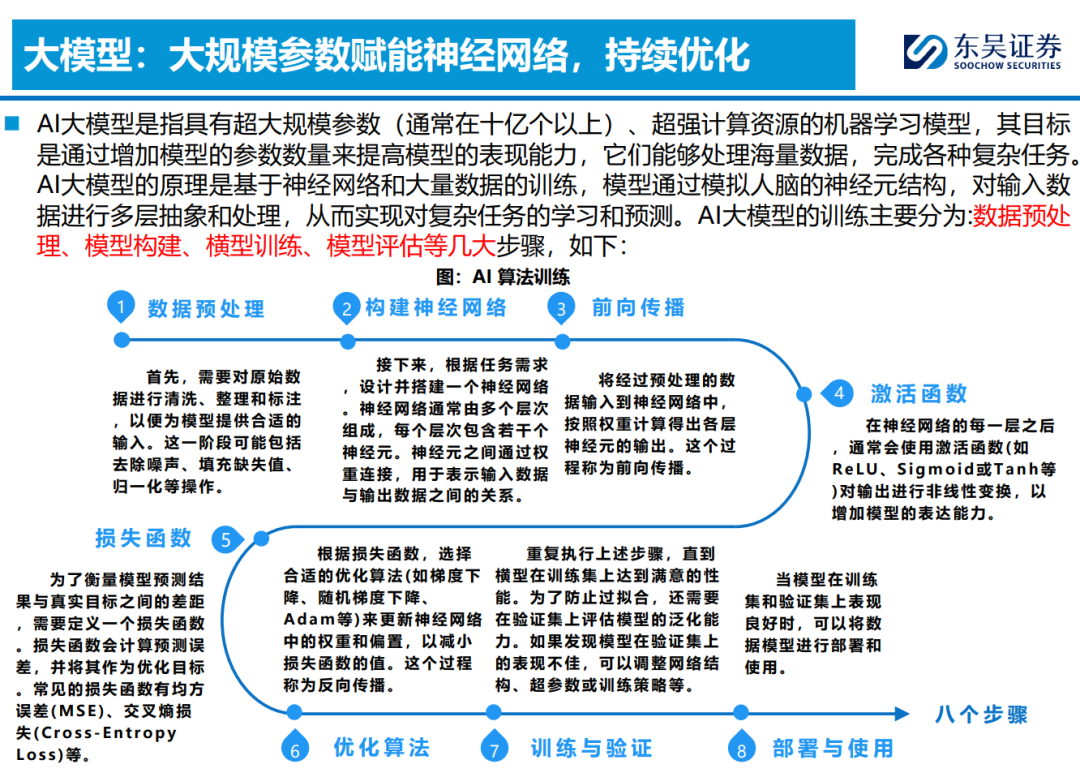
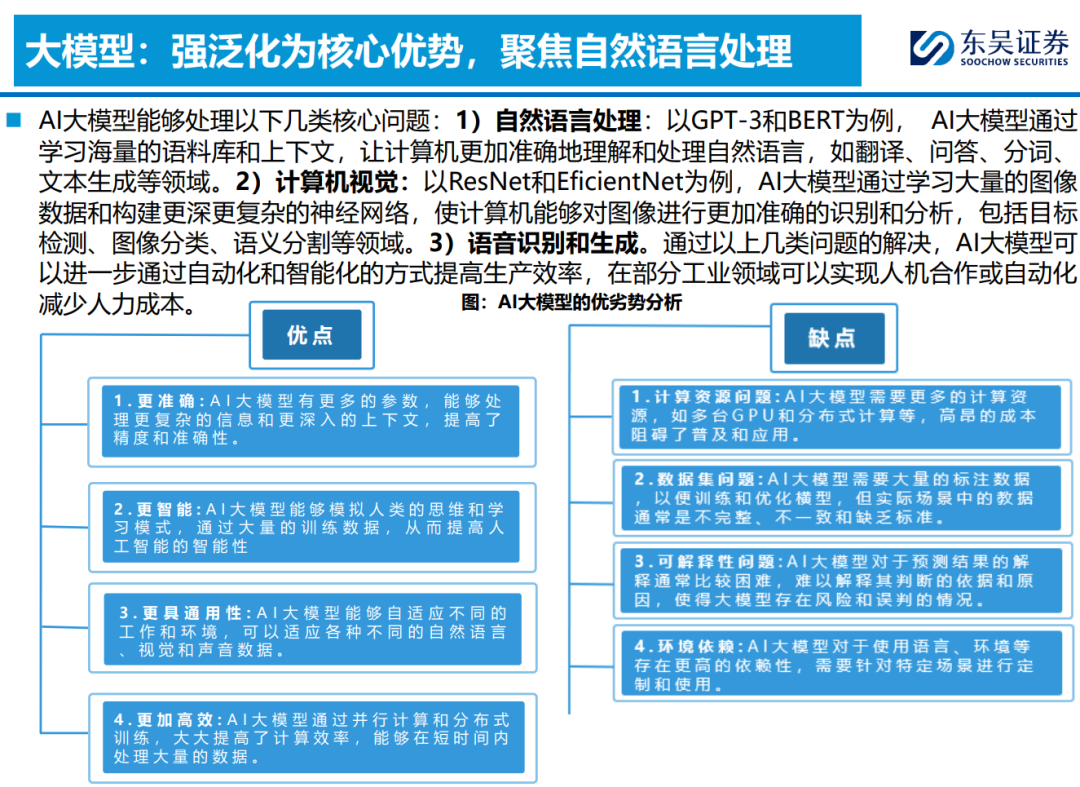
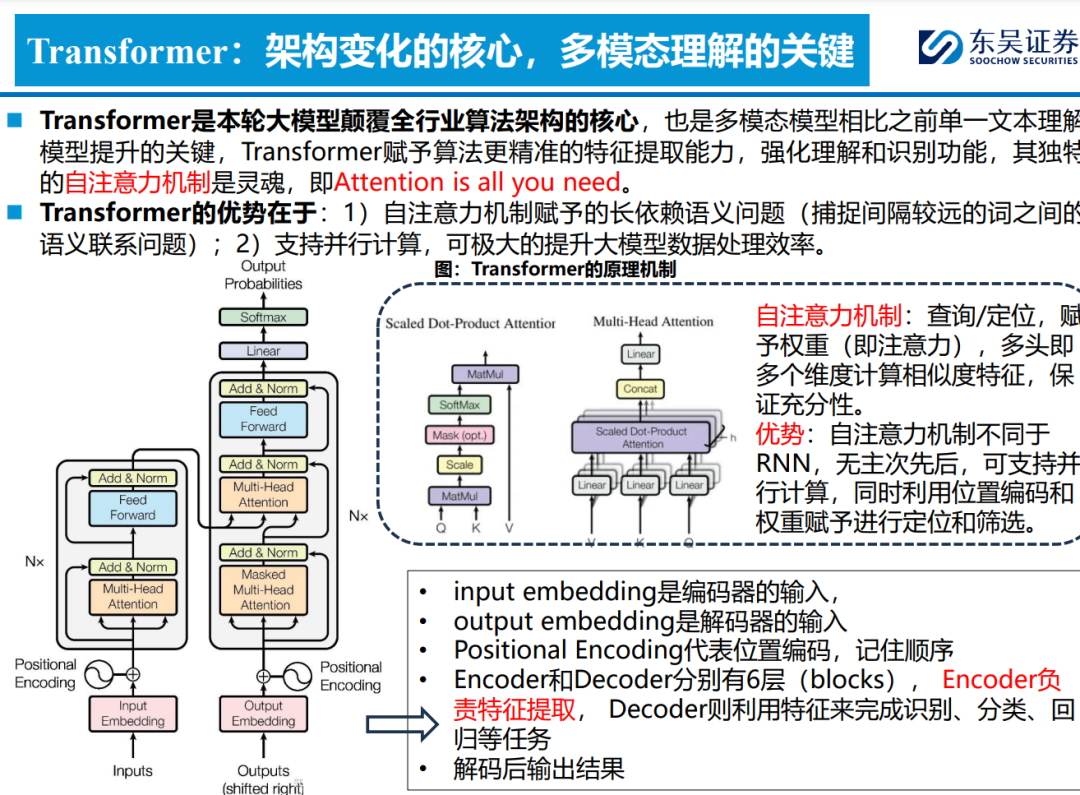
何谓“大模型”?大数据喂养神经网络算法,设定规则机制使其自成长。1)多模态数据是基础, 包括文本/图像/音频/视频等在内的多类型数据喂养,驱动算法更好完成理解/生成等任务。2) Transformer是核心,Self-Attention机制强化算法抽象特征提取能力,并支持并行计算,高能 且高效,衍生ViT/DiT支持多模态数据理解/生成。3)ChatGPT及Sora为代表应用,在大参数加 持下,开发多模态自然语言处理以及文生视频等功能。4)世界模型为未来方向,算法能力由数据 驱动演变为认知驱动,模型具备反事实推理和理解物理客观规律的能力,提升通用泛化特性。 ◼ 大模型重塑车端算法架构,加速云端算法迭代;世界模型或为完全自动驾驶最优解。智驾一阶段 (L2~L3)脱胎换骨:由场景驱动转向数据驱动,大模型带来底层架构质变;智驾二阶段 (L3~L4)厚积薄发:由数据驱动转向认知驱动,数据和算力逐步累计驱动能力提升,量变引起 质变。1)车端:上层感知/规控应用层算法随功能需求提升持续进化,“场景理解处理能力泛化”是核心诉求。L2~L3,感知端为升级核心,Transformer加持BEV+占用网络算法落地感知端到端,解决长尾场景识别难题;L3~L4以规控算法升级为核心,精准识别并快速处理,Learning-base 逐步取代Rule-base,端到端拉高场景处理能力的天花板。2)云端:数据闭环为前提,加速大数 据有效利用,采集/标注/仿真/训练/部署一体化。Transformer赋能自动标注,数据驱动场景仿真 泛化,降低对有限的实际路测数据的依赖。3)世界模型【通用具身智能】或为自动驾驶最优解。 车端场景生成泛化,将自动驾驶问题转化为预测视频的下一帧,类人模式处理,实现泛化至数据 场景以外的能力;并可快速生成标准化仿真数据,结合大算力加速云端训练。 ◼ 算法实现高壁垒+数据闭环硬要求,未来智驾算法产业格局趋于集中化。当前下游L3+高阶算法方 案以OEM自研为主,华为以“算法赋能,数据回传”的形式深度绑定OEM;L3以下算法呈现 OEM+独立算法商+硬件商三足鼎立格局。我们认为,考虑高阶智驾功能的提升对于算法能力/组 织架构/超算中心/完整数据链等的要求,未来“掌握硬件的基础上去发展软件”或为主流,即掌 握壁垒最高的硬件——芯片;提供性价比最高的硬件——传感器;掌握粘性最强的硬件——整车。