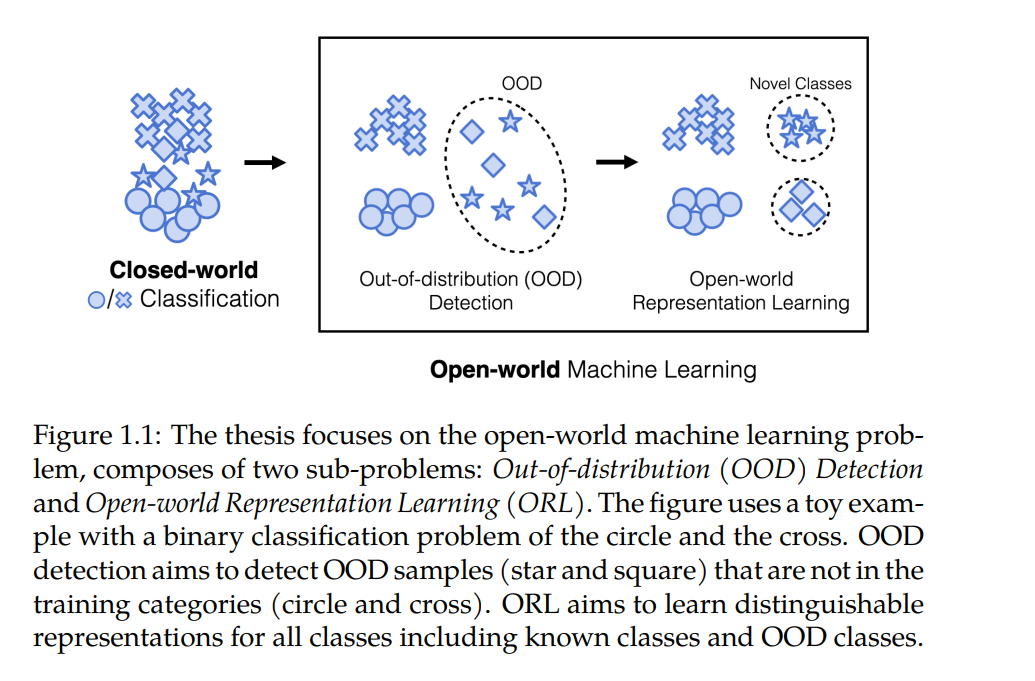
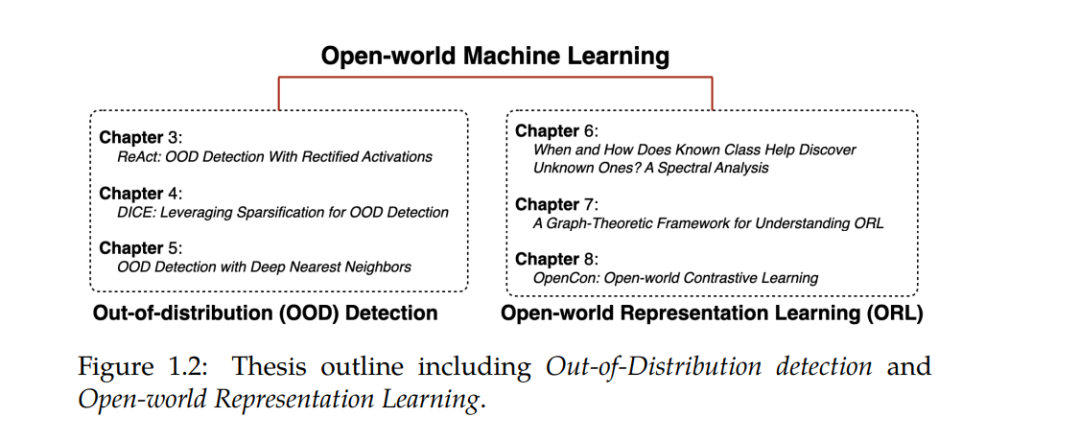
这篇论文在机器学习领域做出了重大贡献,特别是在开放世界场景的背景下,系统面对以前未见过的数据和情境。传统的机器学习模型通常在一个固定且已知的类别集内进行训练和测试,这种情况被称为封闭世界设定。虽然这种假设在受控环境中有效,但在现实世界应用中却不足够,因为新的类别或数据分类可能会动态且意外地出现。为了解决这个问题,我们的研究了开放世界机器学习的两个相互关联的步骤:超出分布(OOD)检测和开放世界表示学习(ORL)。OOD检测专注于识别那些落在模型训练分布之外的未知类别的实例。这个过程减少了对不熟悉输入做出过度自信、错误预测的风险。超越OOD检测,ORL扩展了模型的能力,不仅能检测未知实例,还能从中学习并纳入这些新类别的知识。 在OOD检测领域,我们的工作首先引入了先进的方法论,即ReACT和DICE,它们可以有效地区分已知和未知类别的样本。ReACT在测试时截断异常高的单元激活,以减少模型对输出的过度自信,而DICE通过稀疏化利用模型最有贡献的权重来进行OOD检测。此外,我们提出了一种基于距离的OOD检测方法,通过引入一种非参数方法,使用K-最近邻(KNN)距离,从而改变了对底层特征空间的刚性分布假设。 超越OOD检测,ORL涉及更深入地探索未知的学习,回答关于已知和未知类别之间的相互作用,以及标签信息在塑造表示中的作用的关键研究问题。通过严格的调查,我们旨在阐明关于已知类别的知识如何有助于揭示以前未见过的类别,以及标签信息如何影响已知和新颖类别的学习和表示。这种探索激发了一种综合的算法框架(OpenCon)的开发,用于ORL,由期望-最大化(EM)视角的理论解释所支撑。 通过深入研究这些开放世界学习的研究问题,本论文为构建不仅表现良好,而且在面对真实世界不断演变的复杂性时可靠的机器学习模型铺平了道路。