
17种大模型因果推断专门评估论文

因果推断是人类智能的标志之一。尽管近年来CausalNLP领域引起了广泛的关注,但是现有的NLP领域的因果推断数据集主要依赖于从经验知识(例如常识知识)中发现因果关系。在这项工作中,我们提出了第一个用于测试大型语言模型(LLMs)纯因果推断能力的基准数据集。具体来说,我们设计了一个新的任务CORR2CAUSE,它接收一组相关性声明,并确定变量之间的因果关系。我们整理了一个超过400K样本的大规模数据集,我们在此数据集上评估了十七种现有的LLMs。通过我们的实验,我们发现了LLMs在因果推断能力方面的一个关键短板,并且表明这些模型在任务上的表现几乎接近随机性。当我们试图通过微调重新定位LLMs来增强这项技能时,这种短板有所缓解,但我们发现这些模型仍然无法泛化——它们只能在变量名称和用于查询的文本表达与训练集相似的分布内设置中进行因果推断,但在通过扰动这些查询生成的分布外设置中失败。CORR2CAUSE对于LLMs来说是一个具有挑战性的任务,并将有助于指导未来关于提高LLMs的纯推理能力和泛化性的研究。
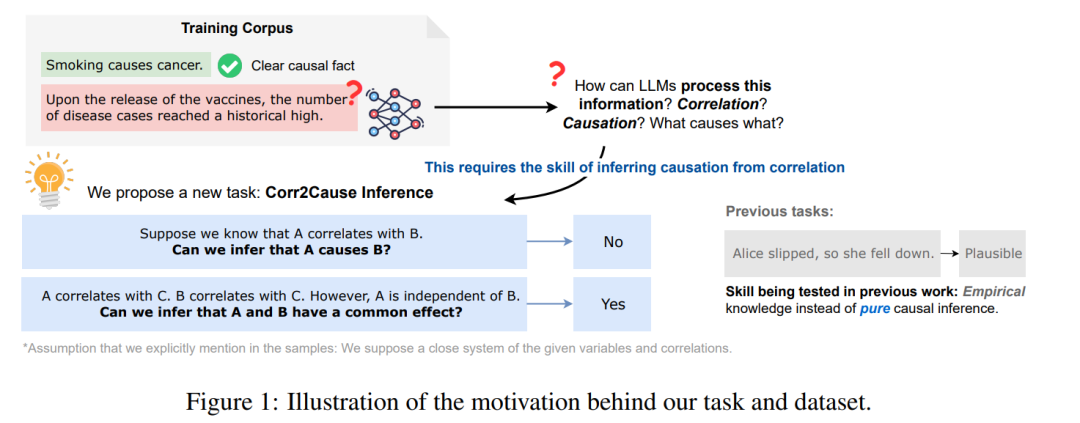
因果推断是人类智能中至关重要的推理能力。它是推理的一个基本方面,涉及建立变量或事件之间正确的因果关系。大致上,有两种不同的方式可以获得因果性:一种是通过经验知识,例如,我们从常识中知道为朋友准备生日聚会会让他们开心;另一种是通过纯因果推理,因为可以使用来自因果推断的已知程序和规则(Spirtes等人,2000;Pearl,2009;Peters等人,2017)正式论证和推理出因果关系。例如,我们知道仅知道A与B相关并不意味着A导致B。我们也知道从纯因果推断中,特别是从因果发现的研究(Spirtes等人,2000;Spirtes和Zhang,2016;Glymour等人,2019)中得到的另一个属性,即如果A和B原本是相互独立的,但在给定C的条件下变得相关,那么我们可以推断,在这个封闭系统中,C是A和B的共同效应,如图1所示。这种碰撞现象可以用来否认A和B之间的因果关系,无论变量A、B和C采取何种实现方式。
我们将这个任务形式化为NLP的一个新任务,即相关性到因果性推断(CORR2CAUSE),并认为这是大型语言模型(LLMs)必备的技能。想象图1中的场景,在训练语料库中有大量的相关性,比如疫苗这个词与疾病病例增加数量的相关性。如果我们认为LLMs(Radford等人,2019;Devlin等人,2019;Ouyang等人,2022;Zhang等人,2022;OpenAI,2023等)的成功在于捕获了术语之间的大量统计相关性(Bender等人,2021),那么至关重要但缺失的一步就是如何处理这种相关性并推断出因果关系,其中一个基本构件就是这个CORR2CAUSE推断技能。
为此,我们收集了第一个数据集CORR2CAUSE,用于测试大型语言模型的纯因果推理能力。这个数据集中的所有问题都围绕着何时可以从相关性推断因果性,何时不可以进行测试。为了系统地编制这个数据集,我们将我们的泛化过程基于因果发现的正式框架(Spirtes等人,1993,2000;Glymour等人,2016;Spirtes和Zhang,2016;Glymour等人,2019),该框架提供了如何根据观察数据中的统计相关性推断变量之间的因果关系的规则。我们生成了超过400K的数据点,并且只有当统计相关性与潜在的因果关系之间存在一一映射时,我们才将相关性-因果性声明对标记为有效。基于我们拥有400K样本的CORR2CAUSE数据集,我们调查了两个主要的研究问题:(1)现有的LLMs在这个任务上的表现如何?(2)现有的LLMs是否可以在这个任务上进行重新训练或者重新定位,并获得强大的因果推理技能?通过大量的实验,我们从经验上显示,我们调查的十七种现有的LLMs没有一种在这个纯因果推理任务上表现良好。我们还显示,尽管LLMs在数据上微调后可以表现出更好的性能,但是它们获得的因果推理技能并不强大。总的来说,我们的贡献如下:
我们提出了新的任务CORR2CAUSE,用来探测LLMs推理能力的一个方面,即纯因果推理;
我们根据因果发现的洞察,编制了一个包含超过400K样本的数据集;
我们评估了十七种LLMs在我们的数据集上的性能,发现它们都表现不佳,接近随机基线;
我们进一步探索了LLMs是否可以通过微调来学习这项技能,并发现LLMs在处理分布外扰动时无法稳定地掌握这项技能,我们建议未来的工作探索更多方法来增强LLMs的纯因果推理技能。
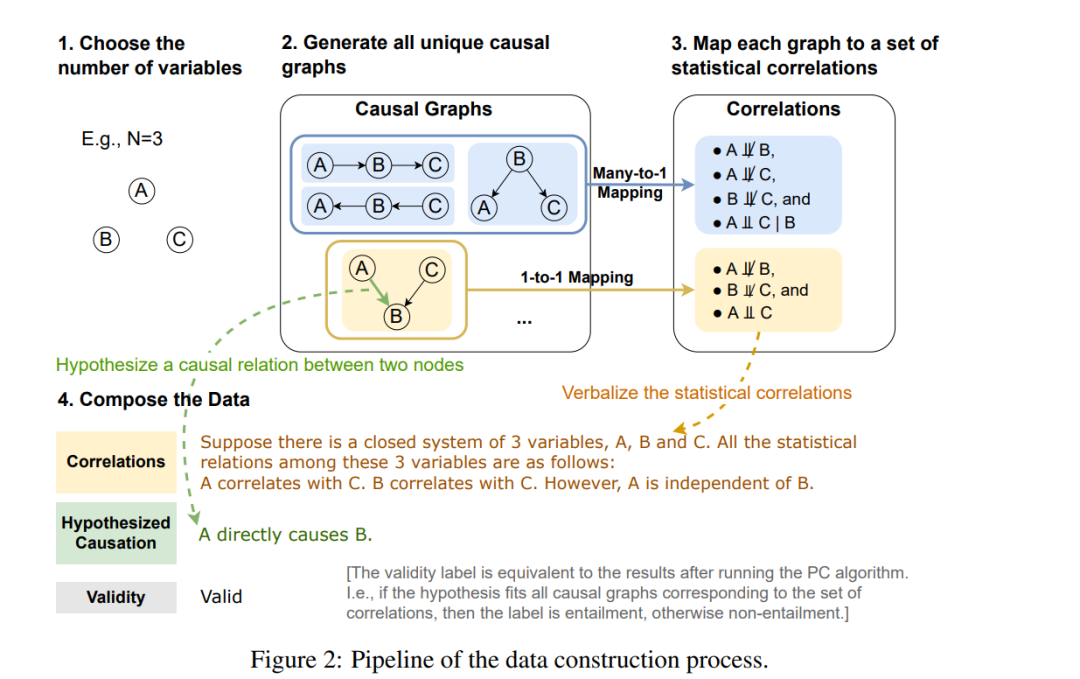
数据构建
我们在这一部分介绍我们的数据集的构建过程。我们从CORR2CAUSE的任务定义开始,然后简要概述数据生成过程,接着详细描述每个步骤。我们在本节的结尾给出了数据集的总体统计信息。
实验结果
我们为我们的CORR2CAUSE数据集的实验准备了一份多样化的LLMs列表。为了测试现有的LLMs,我们首先包括了在transformers库(Wolf et al., 2020)中下载次数最多的六种常用BERT-based NLI模型:BERT(Devlin et al., 2019)、RoBERTa(Liu et al., 2019)、BART(Lewis et al., 2020)、DeBERTa(He et al., 2021)、DistilBERT(Sanh et al., 2019)和DistilBART(Shleifer和Rush,2020)。除了这些基于BERT的NLI模型,我们还评估了基于GPT(Radford et al., 2019)的通用自回归LLMs:GPT-3 Ada、Babbage、Curie、Davinci(Brown et al., 2020);它的指令调整版本(Ouyang et al., 2022),text-davinci-001、text-davinci-002和text-davinci-003;以及GPT-3.5(即,ChatGPT)和最新的GPT-4(OpenAI,2023),使用OpenAI API2,温度为0。我们还评估了最近的,更高效的模型LLaMa(Touvron et al., 2023)和Alpaca(Taori et al., 2023)。 当我们观察微调模型的表现时,我们选用了一大批模型,包括使用OpenAI微调API进行分类的GPT模型(GPT-3 Ada、Babbage、Curie和Davinci),从头开始的BERT模型(BERT-Base、BERT-Large、RoBERTa-Base和RoBERTa-Large),以及使用transformers库(Wolf et al., 2020)的基于BERT的NLI模型(BERT-Base MNLI、BERT-Large MNLI、RoBERTaBase MNLI和RoBERTa-Large MNLI)。我们的训练细节在附录A中提供。
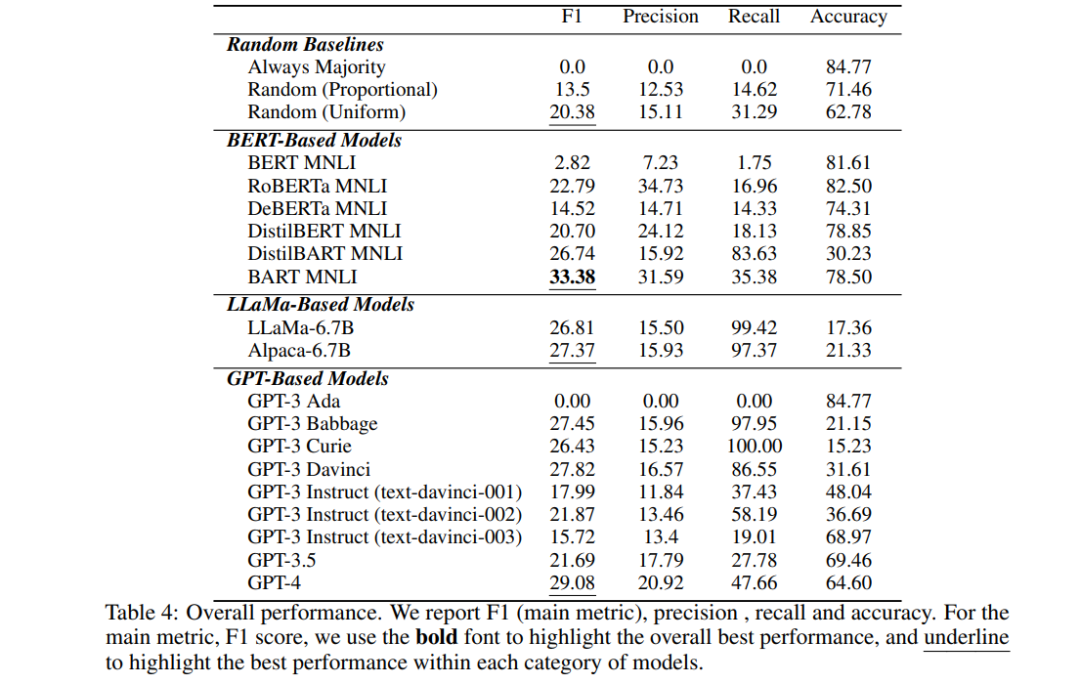
我们在表4中展示了LLMs的性能。我们可以看到,纯粹的因果推理对所有现有的LLMs来说都是一个非常具有挑战性的任务。在所有的LLMs中,性能最好的是BART MNLI的33.38% F1,这甚至超过了最新的基于GPT的模型,GPT-4。值得注意的是,许多模型比随机猜测还要差,这意味着他们在这个纯粹的因果推理任务上完全失败了。
我们识别出了这项工作的几个局限性,并提出了未来的研究方向:首先,在这项工作的背景下,我们将因果图的节点限制在二至六个,但未来的工作可以自由地探索更大的图。另一个方面是,我们在这个推断问题中并没有假设存在隐藏的混淆因素,因此我们欢迎未来的工作生成一个更具挑战性的数据集,来推断隐藏混淆因素的存在,类似于快速因果推断(Fast Causal Inference,FCI)(Spirtes 等人,2000)的因果发现算法。最后,提出这项任务的很大一部分动机是由我们日常推理中无效推理模式的问题启发的(Jin等人,2022),这可能为更广泛的假新闻传播提供了肥沃的土壤。我们认为错误的因果推断是一种普遍的谬误信念,并欢迎未来的工作将这个基准的想法与更多基于混淆相关性和因果性的真实世界错误信念联系起来。
实验结论
在这项工作中,我们引入了一项新的任务,即从相关性推断因果关系的CORR2CAUSE,并收集了超过40万个样本的大规模数据集。我们在这个新任务上对一长串的LLMs进行了评估,并显示出现成的LLMs在这个任务上表现不佳。我们还证明,通过微调可以将LLMs重新定向到这个任务,但未来的工作需要注意超出分布的泛化问题。为避免好哈特定律(Goodhart’s law),我们建议使用这个数据集来对那些尚未见过这个数据集的LLMs进行纯因果推断技能的基准测试。鉴于当前LLMs的推理能力有限,且难以从训练语料库派生的知识中分离出实际的推理,我们社区必须专注于旨在准确解开并测量这两种能力的工作。我们相信,目前的工作是这样的第一步。

