
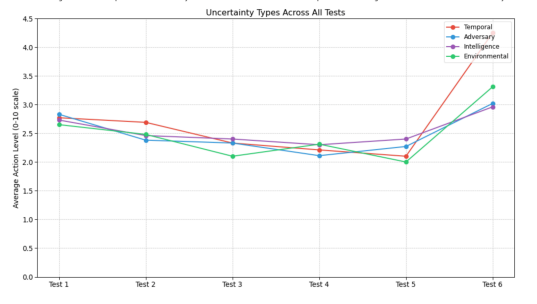
人工智能在军事领域的应用已有数十年历史,但随着大型语言模型(LLM)能力激增,这些系统极有可能在现代战争中发挥更大作用。既往研究表明,LLM在兵棋推演模拟中倾向于支持冲突升级,暴露出军事化人工智能潜在的危险逻辑缺陷。基于这些研究,我们测试了不确定性、思维链提示与温度参数如何影响LLM建议采取激进行动的倾向。与先前结论不同,我们发现测试模型普遍优先选择外交手段而非冲突升级。然而,研究同时揭示:时间与情报的不确定性、以及思维链提示机制,往往会导致更具攻击性的行动建议。这些发现表明,特定威胁条件下采用基于LLM的决策支持系统可能更具安全性。
成为VIP会员查看完整内容
相关内容

Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
140+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
205+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
140+阅读 · 2023年3月29日