

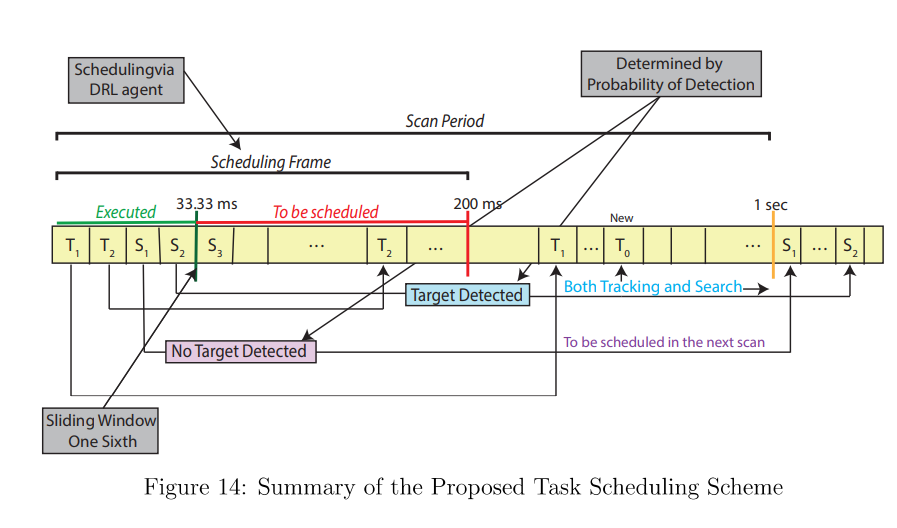
报告 1: 认知雷达中未知和动态环境下任务调度的深度强化学习
近年来,基于机器学习的认知任务调度方法在多功能雷达(MFR)中得到了广泛应用。然而,现有的多功能雷达任务调度方法依赖于对运行环境的了解;但在实践中,动态雷达环境固有的不确定性带来了巨大挑战,尤其是对认知多功能雷达而言。在此,我们探讨了在不预先了解环境的情况下在认知 MFR 中进行在线任务调度的需求。具体来说,我们从基于模型的深度强化学习(DRL)的最新进展中汲取灵感,开发了 MuZero,以在未知和持续变化的环境中实现认知 MFR。在这种方法中,调度器学习环境的抽象马尔可夫决策过程(MDP)模型,从而使抽象 MDP 中的近优规划有效地转化为真实环境。然而,已发布的 MuZero 方法具有指数级的复杂性,需要较长的训练时间,而且只适用于少量任务。在这里,我们通过结合任务调度问题的先验知识,修改了原始的 MuZero 算法,以适应较大的行动空间。我们的数值结果表明,修改后的 MuZero 方法在复杂的雷达场景中是有效的,而且计算量也不大。


报告 2:多功能多通道雷达的自适应雷达资源管理
以前的工作考虑的是一个抽象模型,其中任务参数由一个未指定的系统确定,现在我们考虑如何将具体的雷达参数和目标参数估计精度约束纳入调度模型。具体来说,建立了一个 S 波段雷达模型,目的是将分析扩展到 S 波段和 X 波段双雷达。新的表述方法要求将以往基于块的方法改为基于滑动窗口的方法。在公式中,选择了特定的参数(如下所述)。不过,如果需要,这些参数也可以改变。
报告 3:通过信念-奖励学习雷达调度策略
波束灵活雷达具有学习调度策略的潜力,只需要根据过去的观测结果构建一个整体信念。对信念的改进进行奖励可直接使智能体学习跟踪已知目标和搜索未知目标的策略,而无需明确奖励这种行为。在本文中,我们将雷达控制器建模为 “信念马尔可夫决策过程 ”中的一个信息收集智能体。利用强化学习求解器制定蒙特卡洛树搜索策略,选择行动时只考虑信念和估计信念-现实距离改进的模型。重要的是,方法与目标数量无关,并能适应动态环境。将展示初步结果,以证明我们的基本概念。
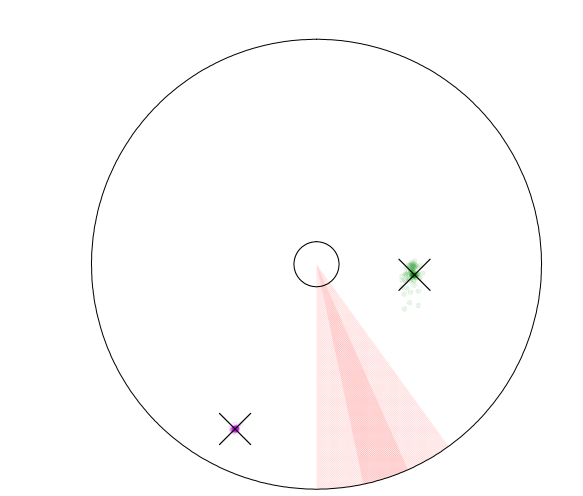
图 15:观测到的可观测范围、两个蓝色的可探测目标、一个已初始化粒子过滤器的目标和一个尚未探测到的灰色目标。
