

长期以来,生成类似于人类书写的自然文本一直是一个研究挑战。当前的文本生成系统在给定一些初始文本作为上下文来生成接下来的文本时,往往会生成一个与前文相比较松散的延续文本,导致相邻句子之间缺乏局部连贯性,更不用说整体的连贯性。很少有人从连贯性和衔接性的角度明确改进文本生成系统。因此,需要一种机制来增强组合文本的准确性和无缝连接性,即人类编写的初始上下文和系统生成的文本的组合。
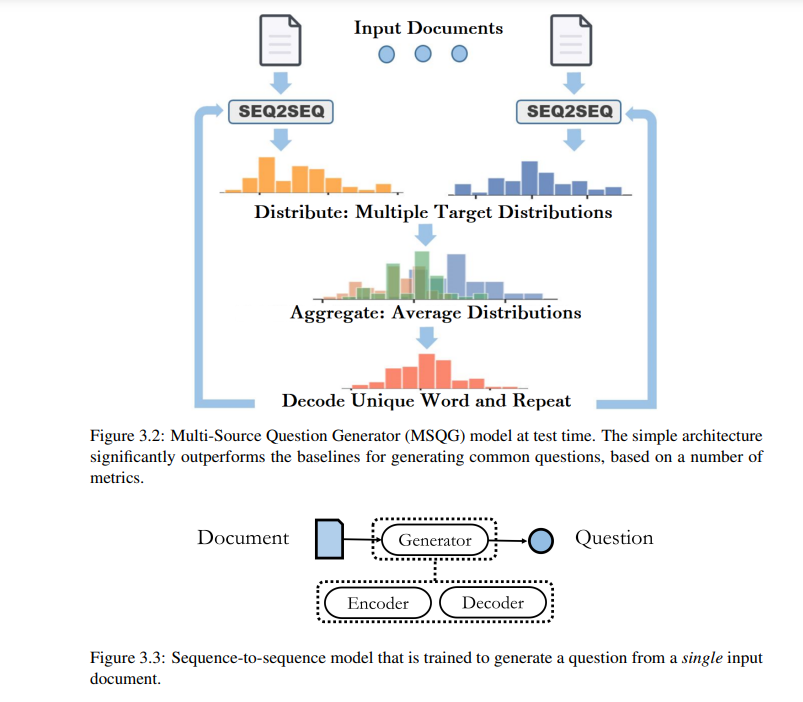
在本论文中,我们提出了两个神经鉴别器,为神经语言模型提供连贯性和衔接性的奖励信号。接下来,我们从以下观察的动机出发,解决了另一个有趣的挑战:搜索引擎中的模棱两可的用户查询往往会检索到涉及多个主题的文档。一个潜在的解决方案是让搜索引擎为最初输入模棱两可查询的用户生成多个经过精炼或澄清的查询,以便每个经过精炼的查询与涉及相同主题的文档子集相关联。实现这一目标的初步步骤是生成一个捕捉多个文档的共同概念的问题。为此,我们提出了一个新的任务,即从多个文档中生成一个共同问题,并呈现了一个现有多源编码器-解码器框架(多源问题生成器,MSQG)的简单变种。然而,这个简单的模型类仅使用目标(“正面”)多文档集,并且可能会生成涵盖比文档集所划定范围更大范围的通用问题。为了解决这个挑战,我们引入了对比学习策略,在给定“正面”和“负面”文档集的情况下,生成一个与“正面”集密切相关但与“负面”集相距较远的问题。我们还提出了一种有效的辅助目标,即基于集合的对比正则化(SCR),用于开发多源协同问题生成器(MSCQG)。




成为VIP会员查看完整内容
相关内容

普林斯顿大学,又译
普林斯敦大学,常被直接称为
普林斯顿,是美国一所私立研究型大学,现为八所常青藤学校之一,绰号为老虎。
Arxiv
0+阅读 · 2023年6月27日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
16+阅读 · 2019年5月24日



相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年6月27日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
16+阅读 · 2019年12月16日
Arxiv
16+阅读 · 2019年5月24日