
转载机器之心在大型语言模型的训练过程中,数据的处理方式至关重要。 传统的方法通常通过将大量文档拼接并切分成等同于模型的上下文长度的训练序列。这虽然提高了训练效率,但也常导致文档的不必要截断,损害数据完整性,导致关键的上下文信息丢失,进而影响模型学习到的内容的逻辑连贯性和事实一致性,并使模型更容易产生幻觉。 AWS AI Labs 的研究人员针对这一常见的拼接-分块文本处理方式进行了深入研究, 发现其严重影响了模型理解上下文连贯性和事实一致性的能力。这不仅影响了模型在下游任务的表现,还增加了产生幻觉的风险。 针对这一问题,他们提出了一种创新的文档处理策略——最佳适配打包 (Best-fit Packing),通过优化文档组合来消除不必要的文本截断,并显著地提升了模型的性能且减少模型幻觉。这一研究已被ICML 2024接收。

文章标题:Fewer Truncations Improve Language Modeling论文链接: https://arxiv.org/pdf/2404.10830
研究背景**
**在传统的大型语言模型训练方法中,为了提高效率,研究人员通常会将多个输入文档拼接在一起,然后将这些拼接的文档分割成固定长度的序列。 这种方法虽然简单高效,但它会造成一个重大问题——文档截断(document truncation),损害了数据完整性(data integrity)。文档截断会导致文档包含的信息丢失 (loss of information)。 此外,文档截断减少了每个序列中的上下文量,可能导致下一个词的预测与上文不相关,从而使模型更容易产生幻觉 (hallucination)。 以下的例子展示了文档截断带来的问题:
- 图2(a):在Python编程中,原始代码虽然正确,但将变量定义与使用分割到不同的训练序列中会引入语法错误,导致某些变量在后续训练序列中未定义,从而使得模型学习到错误的模式,并可能在下游任务中产生幻觉。例如,在程序合成任务中,模型可能会在没有定义的情况下直接使用变量。
- 图2(b):截断同样损害了信息的完整性。例如,摘要中的“Monday morning”无法与训练序列中的任何上下文匹配,导致内容失实。这种信息不完整性会显著降低模型对上下文信息的敏感度,导致生成的内容与实际情况不符,即所谓的不忠实生成 (unfaithful generation)。
- 图2(c):截断还会阻碍训练期间的知识获取,因为知识在文本中的表现形式通常依赖完整的句子或段落。例如,模型无法学习到ICML会议的地点,因为会议名称和地点分布在不同的训练序列中。
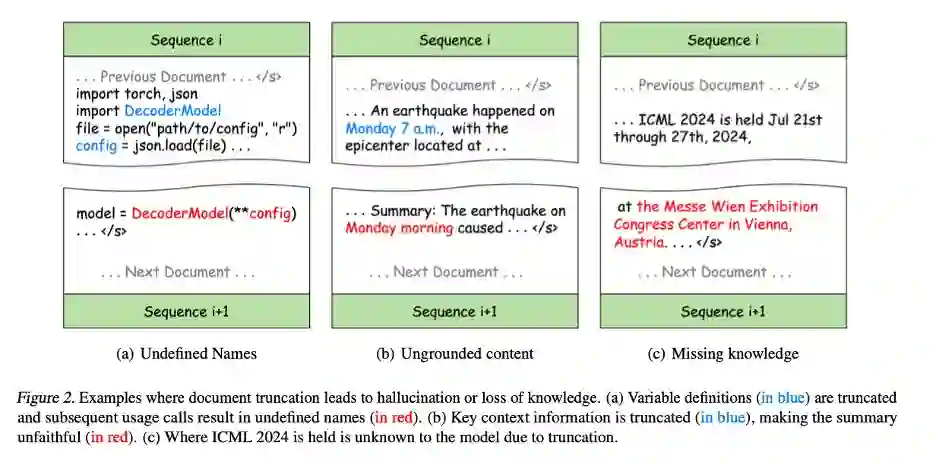
图2. 文档截断导致幻觉或知识丧失的例子。(a) 变量定义(蓝色部分)被截断,随后的使用调用导致未定义名称(红色部分)。(b) 关键上下文信息被截断(蓝色部分),使得摘要不忠实于原文(红色部分),(c) 由于截断,模型不知道ICML 2024的举办地点。
最佳适配打包
针对这一问题,研究者提出了最佳适配打包 (Best-fit Packing)。 该方法使用长度感知的组合优化技术,有效地将文档打包到训练序列中,从而完全消除不必要的截断。这不仅保持了传统方法的训练效率,而且通过减少数据的片段化,实质性地提高了模型训练的质量。 作者首先先将每个文本分割成一或多个至多长为模型上下文长度L的序列。这一步限制来自于模型,所以是必须进行的。 现在,基于大量的至多长为L的文件块,研究者希望将它们合理地组合,并获得尽量少的训练序列。这个问题可以被看作一个集装优化(Bin Packing)问题。集装优化问题是NP-hard的。如下图算法所示,这里他们采用了最佳适配递减算法(Best-Fit-Decreasing, BFD) 的启发式策略。 接下来从时间复杂度 (Time Complexity) 和紧凑性 (Compactness) 的角度来讨论BFD的可行性。

时间复杂度:**
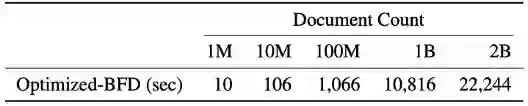
**BFD的排序和打包的时间复杂度均为O(N log N),其中N是文档块的数量。在预训练数据处理中,由于文档块的长度是整数并且是有限的 ([1, L]),可以使用计数排序 (count sort) 来实现将排序的时间复杂度降低到O(N)。 在打包阶段,通过使用段树(Segment Tree)的数据结构,使得每次寻找最佳适配容器的操作只需对数时间,即O(log L)。又因为L<<N, 使得总时长约为 O(N),进而整体算法与数据大小呈线性关系,确保对大规模数据集的适用性:处理大型预训练语料库如Falcon RefinedWeb (约十亿文档) 只需要3小时。
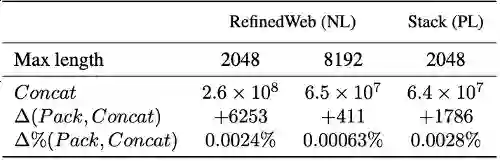
紧凑性是衡量打包算法效果的另一个重要指标,在不破坏原文档完整性的同时需要尽可能减少训练序列的数量以提高模型训练的效率。 在实际应用中,通过精确控制序列的填充和排布,最佳适配打包能够生成几乎与传统方法相当数量的训练序列,同时显著减少了因截断而造成的数据损失。
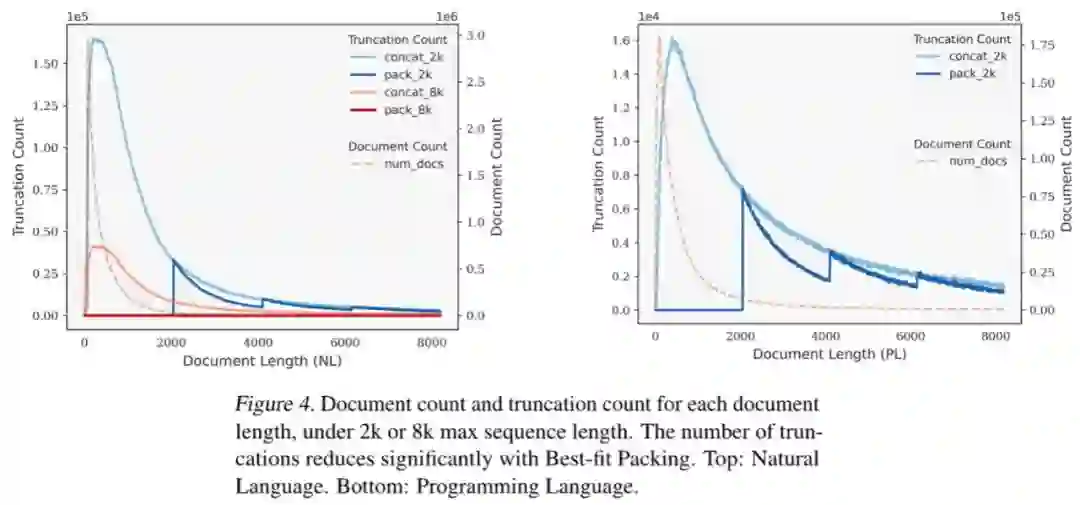
基于在自然语言(RefinedWeb) 和编程语言(The Stack) 数据集上的实验,我们发现最佳适配打包显著降低了文本截断。 值得注意的是,大多数文档包含的token数少于2048个;由于传统拼接-分块时造成的截断主要发生在这一范围内,而最佳适配打包不会截断任何长度低于L的文档,由此有效地保持了绝大多数文档的完整性。
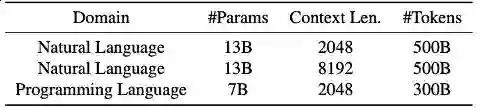
研究人员详细报告了使用最佳适配打包与传统方法(即拼接方法)训练的语言模型在不同任务上的表现对比,包括:自然语言处理和编程语言任务,如阅读理解 (Reading Comprehension)、自然语言推理 (Natural Language Inference)、上下文跟随 (Context Following)、文本摘要 (Summarization)、世界知识 (Commonsense and Closed-book QA) 和程序合成 (Program Synthesis),总计22个子任务。 实验涉及的模型大小从70亿到130亿参数不等,序列长度从2千到8千令牌,数据集涵盖自然语言和编程语言。这些模型被训练在大规模的数据集上,如Falcon RefinedWeb和The Stack,并使用LLaMA架构进行实验。
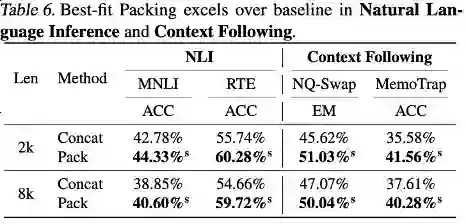
实验结果表明,使用最佳适配打包在在一系列任务中提升了模型性能,尤其是在阅读理解 (+4.7%)、自然语言推理 (+9.3%)、上下文跟随 (+16.8%) 和程序合成 (+15.0%) 等任务中表现显著(由于不同任务的度量标准的规模各异,作者默认使用相对改进来描述结果。) 经过统计检验,研究者发现所有结果要么统计显著地优于基线(标记为s),要么与基线持平(标记为n),且在所有评测的任务中,使用最佳适配打包均未观察到性能显著下降。 这一一致性和单调性的提升突显了最佳适配打包不仅能提升模型的整体表现,还能保证在不同任务和条件下的稳定性。详细的结果和讨论请参考正文。


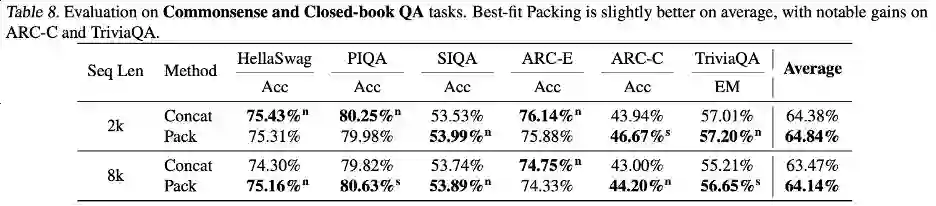
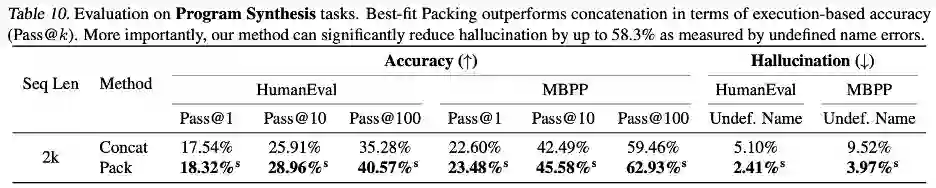
**本文提出了大型语言模型训练中普遍存在的文档截断问题。 这种截断效应影响了模型学习到逻辑连贯性和事实一致性,并增加了生成过程中的幻觉现象。作者们提出了最佳适配打包(Best-fit Packing),通过优化数据整理过程,最大限度地保留了每个文档的完整性。这一方法不仅适用于处理数十亿文档的大规模数据集,而且在数据紧凑性方面与传统方法持平。 实验结果显示,该方法在减少不必要的截断方面极为有效,能够显著提升模型在各种文本和代码任务中的表现,同时有效减少封闭域的语言生成幻觉。尽管本文的实验主要集中在预训练阶段,最佳适配打包也可广泛应用于其他如微调阶段。这项工作为开发更高效、更可靠的语言模型做出了贡献,推动了语言模型训练技术的发展。
