

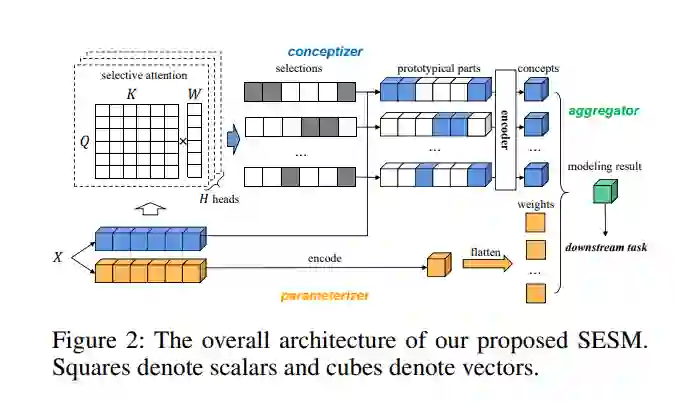
基于原型的可解释性方法通过将样本与记忆的样本或典型代表的参考集进行相似性比较,为模型预测提供直观的解释。在序列数据建模领域,原型的相似度计算通常基于编码表示向量。然而,由于高度递归的函数,基于原型的解释和原始输入之间通常存在不可忽略的差异。本文提出一种自解释选择性模型(SESM),用原型概念的线性组合来解释自己的预测。该模型采用基于案例推理的思想,选择最能激活不同概念的输入子序列作为原型部件,用户可以将其与从不同示例输入中选择的子序列进行比较,以理解模型决策。为了更好的可解释性,设计了多种约束,包括多样性、稳定性和局部性作为训练目标。在不同领域的广泛实验表明,所提出方法表现出良好的可解释性和有竞争力的准确性。
https://www.zhuanzhi.ai/paper/db26f2247e2b7a1b39ddc69b3e9e4ab8
成为VIP会员查看完整内容
相关内容

相关VIP内容
相关资讯