

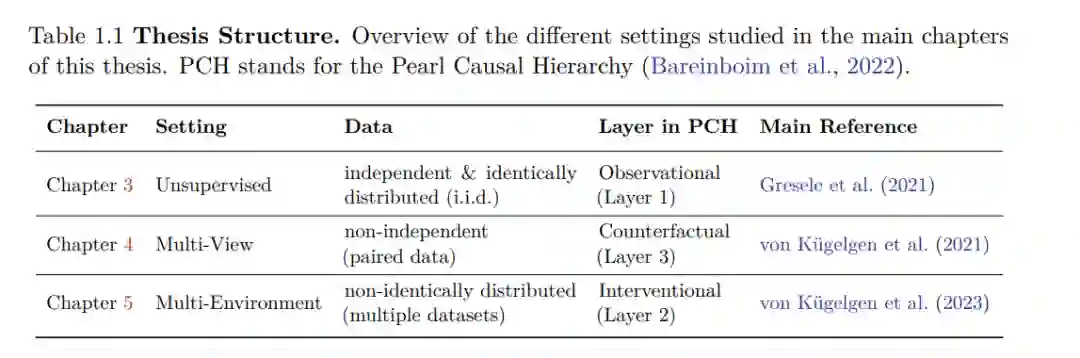
本论文将因果关系和表示学习的思想结合起来。因果模型以一组机制的形式提供复杂系统的丰富描述,每个变量都受其直接原因的影响。它们支持对系统部分进行操纵的推理,捕获一整套干预分布,因此有望解决人工智能(AI)的一些开放性挑战,如规划、在变化环境中转移知识或对分布变化的鲁棒性。然而,因果模型在AI中更广泛使用的一个主要障碍是需要预先指定相关变量,这通常不适用于现代AI系统处理的高维、非结构化数据。与此同时,机器学习(ML)在自动提取此类复杂数据的有用且紧凑的表示方面已经证明相当成功。因果表示学习(CRL)旨在通过学习以因果模型语义赋予的潜变量形式的表示来结合ML和因果关系的核心优势。在这篇论文中,我们研究并呈现了不同CRL设置的新结果。一个核心主题是可识别性的问题:给定无限数据,何时满足相同学习目标的表示保证是等价的?这可以说是CRL的一个重要先决条件,因为它正式表明学习任务在原则上至少是可行的。由于学习因果模型——即使没有表示学习组件——是出了名的困难,我们需要对模型类或超出经典i.i.d.设置的丰富数据进行额外假设。对于从i.i.d.数据进行的无监督表示学习,我们开发了独立机制分析,这是对将潜变量映射到观察变量的混合函数的约束,它被证明促进了独立潜变量的可识别性。对于从非独立观察对学习的多视角设置,我们证明了在视图中始终共享的潜在块是可识别的。最后,对于从完美单节点干预产生的非同分布数据集学习的多环境设置,我们显示了潜变量及其因果图是可识别的。 通过研究和部分描述不同设置的可识别性,这篇论文调查了在没有直接监督的情况下CRL的可能性和不可能性,因此为其理论基础做出了贡献。理想情况下,开发的见解可以帮助指导数据收集实践或激发新的实用估计方法和算法的设计。



成为VIP会员查看完整内容
相关内容

Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日