

摘要: 目标检测是计算机视觉方向的热点领域,其通常需要大量的标注图像用于模型训练,这将花费大量的人力和物力来实现。同时,由于真实世界中的数据存在固有的长尾分布,大部分对象的样本数量都比较稀少,比如众多非常见疾病等,很难获得大量的标注图像。小样本目标检测只需要提供少量的标注信息,就能够检测出感兴趣的对象,对小样本目标检测方法做了详细综述。首先回顾了通用目标检测的发展及其存在的问题,从而引出小样本目标检测的概念,对同小样本目标检测相关的其他任务做了区分阐述。之后介绍了现有小样本目标检测基于迁移学习和基于元学习的两种经典范式。根据不同方法的改进策略,将小样本目标检测分为基于注意力机制、图卷积神经网络、度量学习和数据增强四种类型,对这些方法中使用到的公开数据集和评估指标进行了说明,对比分析了不同方法的优缺点、适用场景以及在不同数据集上的性能表现。最后讨论了小样本目标检测的实际应用领域和未来的研究趋势。
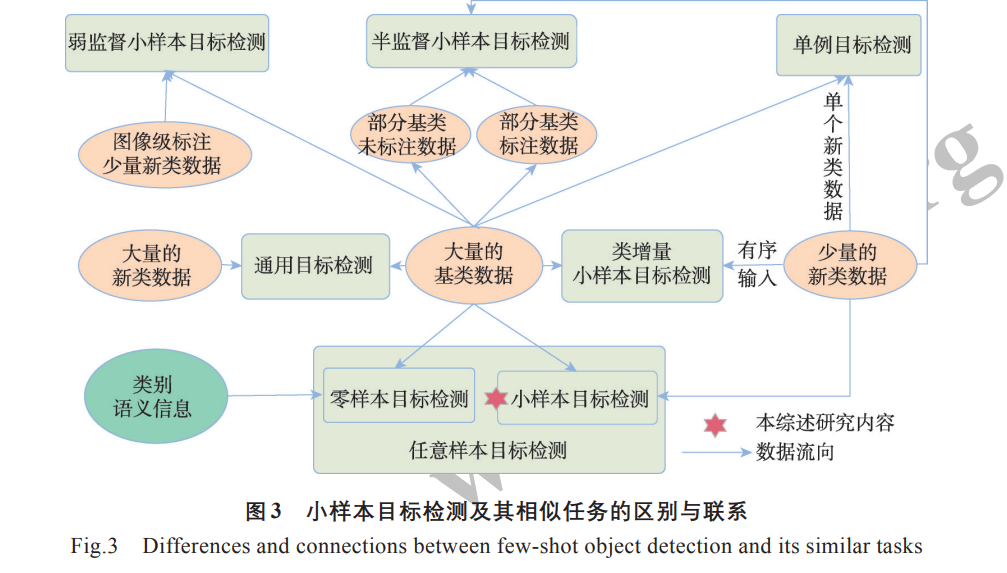
目标检测是计算机视觉方向的热点领域,其任务 是将图像中任意数目的感兴趣对象用外接矩形框选出 来并识别出对象类别。作为计算机视觉的基本任务之 一,目标检测应用广泛,其已经在缺陷检测[1-3] 、农业病 虫害识别[4] 和自动驾驶[5] 等领域发挥着重要的作用。 2014 年,Girshick 等[6] 提出了用于解决目标检测 任务的 R-CNN(region-based convolutional neural networks)算法并取得了极大的性能提升,目标检测研究 从此进入深度学习时代。Girshick等[7] 又在 2016年提 出了经典的 Faster R-CNN 两阶段算法,首先在图像 上生成大量可能是对象的候选区,然后对这些候选 区进行筛选,对筛选得到的候选区进行分类和回归 得到想要的结果。由于两阶段算法会基于生成的大 量候选区做进一步处理,虽然检测精度较高,但检测 速度相对不是很理想。一阶段算法不需要事先通过 专门的算法模块生成大量候选区,而只是在图像上 预先定义了不同大小和比例的锚框,用这些锚框代 替了两阶段算法的候选区,不再需要复杂的候选区 操作,只需对图像进行一次卷积处理就可以完成对 象的定位和分类,经典的一阶段网络有 YOLO(you only look once)系列[8-10] 、SSD(single shot multibox detector)[11] 、RetinaNet[12] 等。近些年,在自然语言处理领 域大放异彩的 Transformer[13] 技术也被成功应用到目 标检测中,DETR(detection transformer)[14] 是其中的 代表之作,其不再需要锚框、候选区和非极大值抑制 等人为设计的知识,而是将目标检测看作直接的集 合预测问题,真正地实现了端到端检测。 上述的目标检测方法都需要使用大量实例级别 的标注信息来实现,这可能会出现以下一些问题: (1)由于现实世界中固有的长尾分布,有些类别本身 就很难获得大量的标注信息,比如珍稀动植物、罕见 病症等;(2)图像的标注通常需要消耗大量的人力去 完成,而且,标注的准确率也不稳定,漏标和误标的 情况常有发生,尤其是某些难以标注的对象,比如病 虫害、肿瘤等;(3)模型的训练需要消耗大量的资源, 如昂贵的 GPU 设备和专业的领域知识等。当只有很 少的标注信息时,现有主流的目标检测方法很难达 到令人满意的效果。然而,现实生活中,即便一个孩 童,也能够通过仅仅观察几张图像就完成对新类别 的学习。因此,通过很少的样本数量进行目标检测是 一个极具现实意义的问题,受到了越来越多的关注。 小样本学习只使用很少的训练样本就能够得到 想要的结果。现在,小样本学习在图像分类、语义分 割和目标检测这三大计算机视觉任务上都有应用, 但迄今为止研究的重点主要集中在图像分类。相比 分类,小样本目标检测问题更加复杂,其不仅仅需要 分类目标的类别,还需要定位出目标的具体位置。 小样本目标检测问题的提出是为了解决实际生产生 活中样本数据标注量少的问题,是非常有现实意义 的研究方向。目前,已有一些关于小样本目标检测 的综述,潘兴甲等[15] 将小样本目标检测方法分为基于 微调、基于模型结构和基于度量学习三种,并对这些 分类方法进行了分析。刘浩宇等[16] 将其分成基于数 据、模型和算法三个类别,并对每个类别进行了归纳 总结,探讨了小样本目标检测的现状和未来趋势。 张振伟等[17] 也从六方面对小样本目标检测方法进行 了分析,比较了不同方法的优缺点。与这些综述[15-17] 不同,本文首先将这些方法归纳为两种范式,再按照 改进策略的不同,从基于注意力机制、图卷积神经网 络、度量学习和数据增强的角度进行归纳总结,对比 分析了不同分类的优缺点和适用场景。同时,收录 了近两年提出的许多新的小样本目标检测方法,对 比分析了这些方法的性能表现。