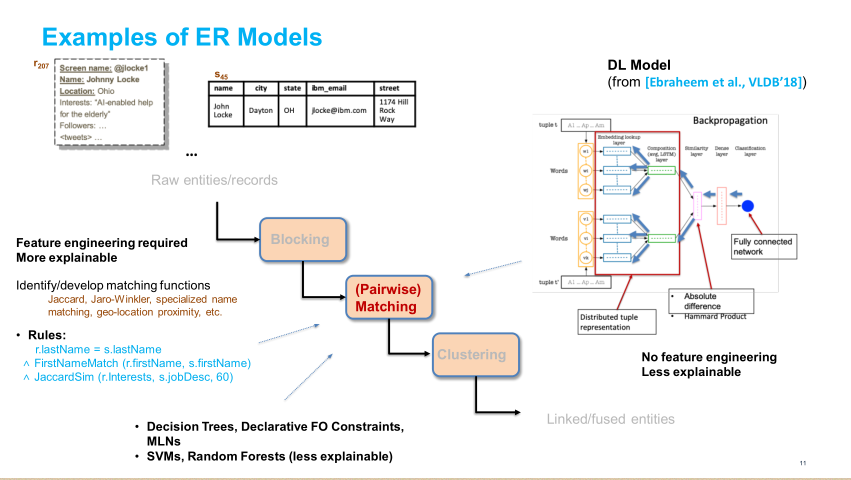
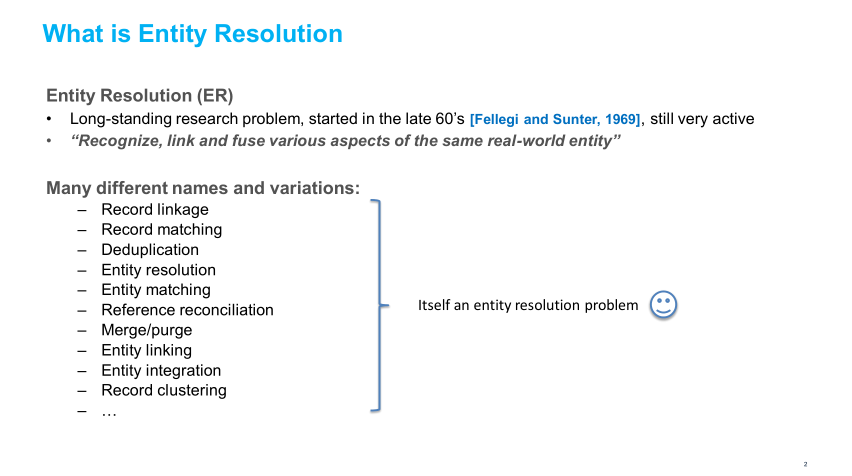
本教程的目标读者是数据集成领域的研究人员和实践者,特别是实体解析(ER),它是关注跨异构数据集连接实体的子领域。我们概述了现代ER系统的理想需求:(1)通过(最少的)人类交互获取领域知识;(2)通过机器学习技术提供尽可能多的自动化;(3)实现高可解释性。我们描述了最近的研究趋势,使这种理想的ER系统更接近现实。我们首先概述了基于众包和主动学习等技术的人参与方法。然后,我们深入研究最近的趋势,这些趋势涉及到深度学习技术,如表示学习以自动化特性工程,以及转移学习和主动学习的组合以减少所需用户标签的数量。我们还讨论了可解释的人工智能如何与ER相关,并概述了可解释的ER的一些最新进展。
邀请嘉宾
Sairam Gurajada是IBM Research-Almaden的研究员。他当前的工作重点是为数据库中众所周知的但困难的实体解析问题开发不可解释的和可解释的学习模型。在此之前,他致力于开发高效且可扩展的技术,用于对大型标签图进行分布式查询以及对IR系统进行在线索引维护。他的一些作品已在SIGMOD,CIKM,IJCAI,ACL等著名会议上发表。
Lucian Popa是IBM Research-Almaden的首席研究人员兼经理。他以在数据交换和模式映射方面的工作而闻名,为此他在ICDT 2013和PODS 2014上获得了两个时间测试奖,并在声明性基础和用于实体解析的工具方面获得了最佳论文。他获得了ICDT 2015奖项。他在信息集成和实体解析领域为IBM产品做出了贡献,并且是ACM杰出会员。
Kun Qian是IBM Research-Almaden的研究员,致力于人在环机器学习中的理解。他对构建具有直观用户界面,用于实体理解和知识创造的智能在环系统特别感兴趣。他在实体解析和相关主题方面的工作已发表在CIKM,PODS,COLING,AAAI和ACL中。他还为实体名称标准化和实体解析开发了几种基于主动学习的系统,这些系统已包含在ICDE 2018,VLDB 2019和AAAI 2020的演示轨道中。
Prithviraj Sen是IBM Research-Almaden的研究员。他的核心兴趣在于开发用于学习可解释模型的算法。过去,他从事过多个领域的工作,包括但不限于使用主动学习和使用神经网络学习可解释的规则来学习ER规则,该神经网络已在ICML,UAI,KDD,VLDB,ICDE,ACL,CIKM中发表。他是Apache SystemML的贡献者,Apache SystemML是用于大规模机器学习的开源引擎( KDD教程的主题 ),此外还贡献了多种IBM产品。