

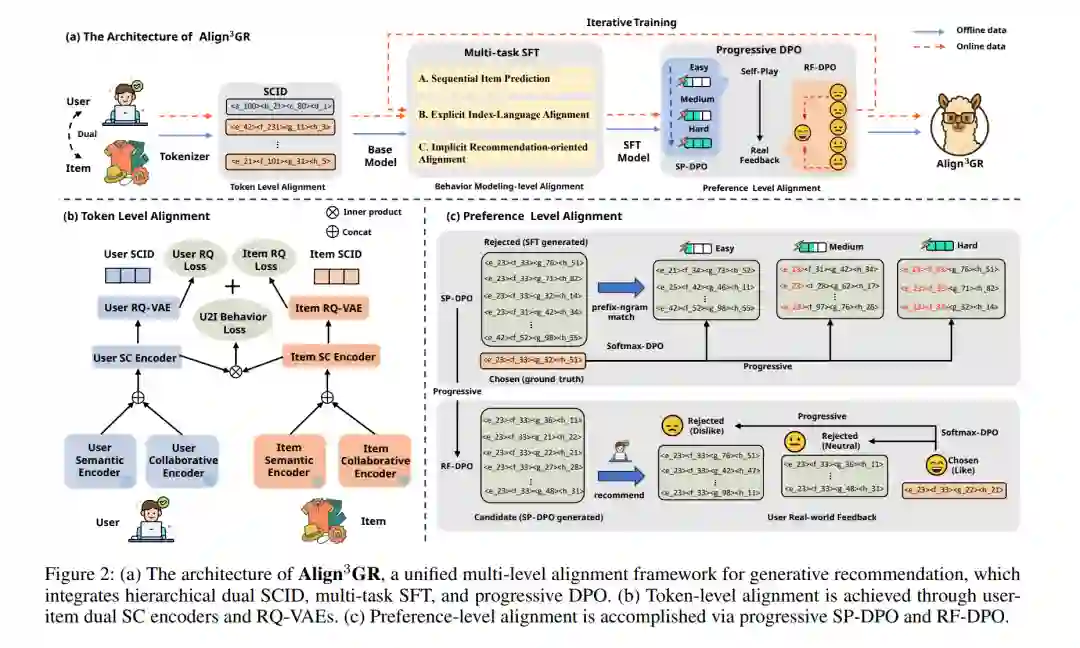
大型语言模型(LLMs)在利用结构化世界知识以及执行多步推理方面展现出显著优势。然而,当将 LLM 转化为真实世界的推荐系统时,会面临语义与行为层面的核心错配问题。为弥合这一鸿沟,我们提出 Align3GR,一个统一了 词元级、行为建模级、偏好级 的多层次对齐框架。该方法引入了以下关键设计: * 双重分词机制:融合用户—物品的语义信息与协同信号; * 增强的行为建模:实现双向语义对齐; * 渐进式 DPO 策略:结合自博弈(SP-DPO)与真实用户反馈(RF-DPO),实现动态偏好自适应。
实验结果表明,在公开数据集上,Align3GR 在 Recall@10 上超越当前最优基线模型 17.8%,在 NDCG@10 上提升 20.2%;同时在真实线上 A/B 测试及工业级大规模推荐平台的部署中也取得了显著收益。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日

相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日