
转载机器之心编辑:张倩1 月 11 日,上海交通大学教授卢策吾在机器之心 AI 科技年会上,发表了主题演讲 ——《具身智能》。在演讲中,他主要介绍了具身智能概况、他们团队提出的 PIE 方案、具身智能与通用人工智能以及具身智能的脑认知。 以下为卢策吾在机器之心 AI 科技年会上的演讲内容,机器之心进行了不改变原意的编辑、整理: 大家好,我是来自上海交通大学的卢策吾,非常荣幸能够跟大家分享一些关于具身智能 (Embodied Intelligences) 的研究。 首先,具身智能是智能科学的一个基础问题。过去 5.4 亿年来,地球上所有的生物都是通过身体逐步产生智能的,所以具身智能是具有身体体验的智能,这点会非常本质地去推进关于智能的问题。 1950 年,图灵在他的论文 ——《Computing Machinery and Intelligence》[1] 中首次提出了具身智能的概念。在之后的几十年里,大家都觉得这是一个很重要的概念,但具身智能并没有取得很大的进展,因为当时的技术还不足以支撑其发展。到了今天,多学科的技术已经改变了这一局面,可以让我们去研究具身智能的一些本质问题。 我这次主要讲四个内容:「具身智能简介」、我们自己提出的「PIE 方案」、「具身智能与通用人工智能」以及「具身智能的脑认知」。 具身智能简介
从认知的角度来看,我们人类是第一人称(而非第三人称)视角的智能。我们用一个 1963 年的实验来讲解这个问题。下图有两只猫,一直猫被绑起来,只能看这个世界;另一只猫可以主动去走。被动的猫是一种旁观的智能,而主动的猫是具身的智能。到最后,这只旁观的猫失去了行走能力。
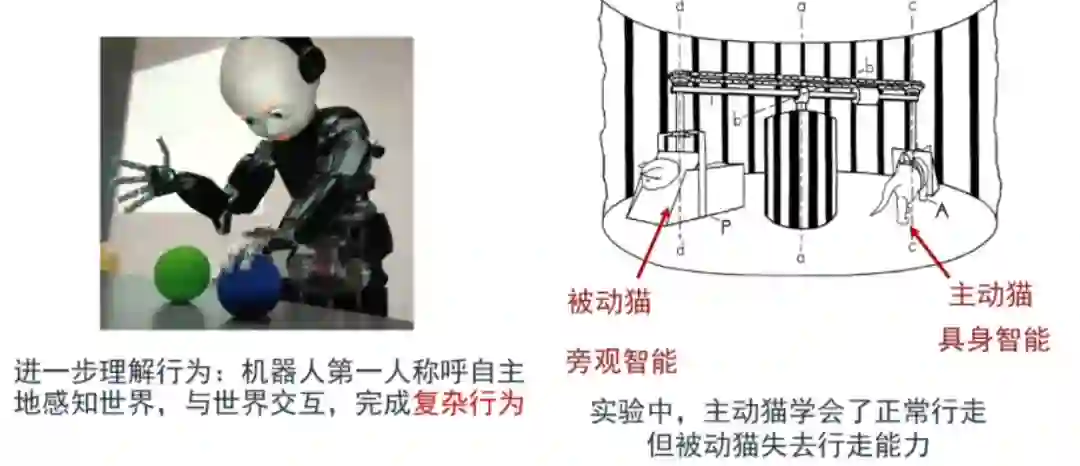
前者有点像我们现在给机器喂很多数据,属于第三人称的智能,比如我们给机器很多盒子,并且标注这就是盒子,然后机器就会觉得这种 pattern 是盒子。但其实,人类是怎么知道这是盒子的?是通过体验才知道的。

目前,具身智能已经成为国际学术前沿研究方向,包括美国国家科学基金会在内的机构都在推动具身智能的发展,各大国际学术会议也开始越来越多地关注具身智能相关工作,美国顶尖高校已经开始形成具身智能研究社区。举例来说,今年的 IROS(机器人领域顶级学术会议)将具身智能作为一个很重要的主题提了出来,谷歌公司比较有名的 Everyday Robot 已经能够将机器人和对话模型结合到一起(参见《谷歌让机器人充当大语言模型的手和眼,一个任务拆解成 16 个动作一气呵成》),形成一个更大的闭环。 我刚才提到,为什么具身智能提出了几十年了,直到最近几年才比较热门。这是因为它涉及到众多的学科,当时很多学科都不是很成熟。比如在视觉上,你看都看不清楚,要怎么去做?此外,当时的硬件、软件还有各种触觉传感器也不够成熟。而到了今天,各个学科都可以聚到一起来做这么一个宏大的系统。在这样的情况下,我们才有可能推动这个方向进一步发展。
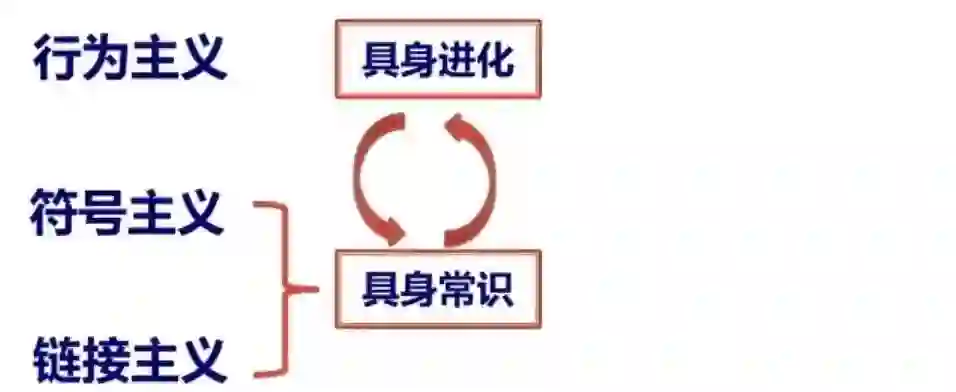
在智能领域,我们有三个主义 —— 行为主义、符号主义和连接主义。我认为这三个主义在具身智能领域应该会有一个很好的结合点。因为,在具身智能中,我们首先需要掌握具身常识。这个环节可以用大模型来做,也可以用 base 来做,或者二者结合来做。这里面就涉及两种主义 —— 符号主义和连接主义。然后,这个具身智能体肯定需要不停地进化,就涉及行为主义。所以这三者会汇聚到一点来推进具身智能的发展。
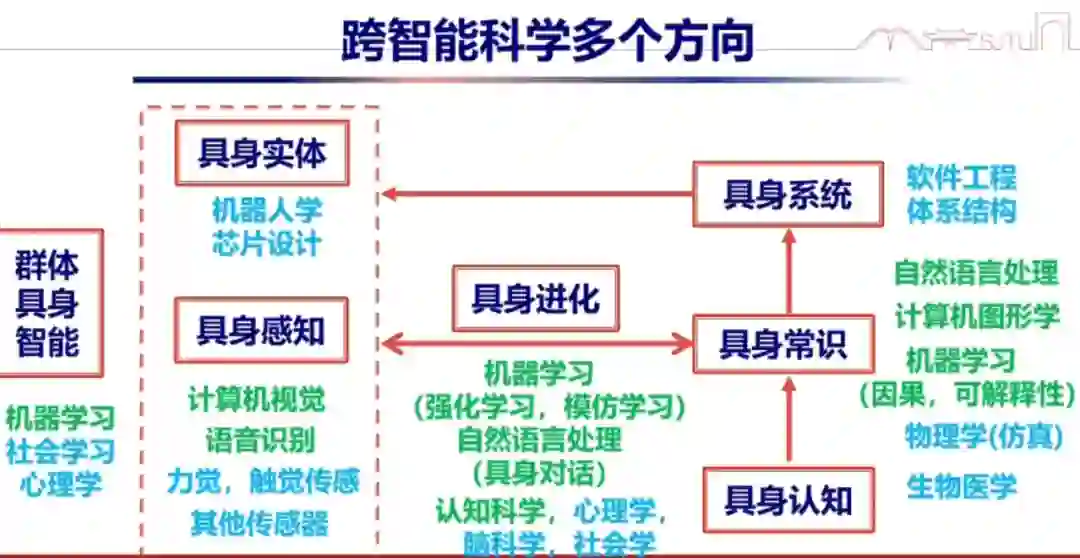
其实,具身智能是一个很好的试验场。它涉及到跟自然语言、认知科学、计算机图形学、材料学、物理学等学科的融合。我认为,这些融合可能会催生一个新的结构体系,就像冯・诺依曼体系,在整个的计算机上跑。它整个计算的流是这种概念流的计算。当然,我们希望看到它在机器人上是通用的。它背后其实是一种智能,只是通过机器人这样一个形态去体现。
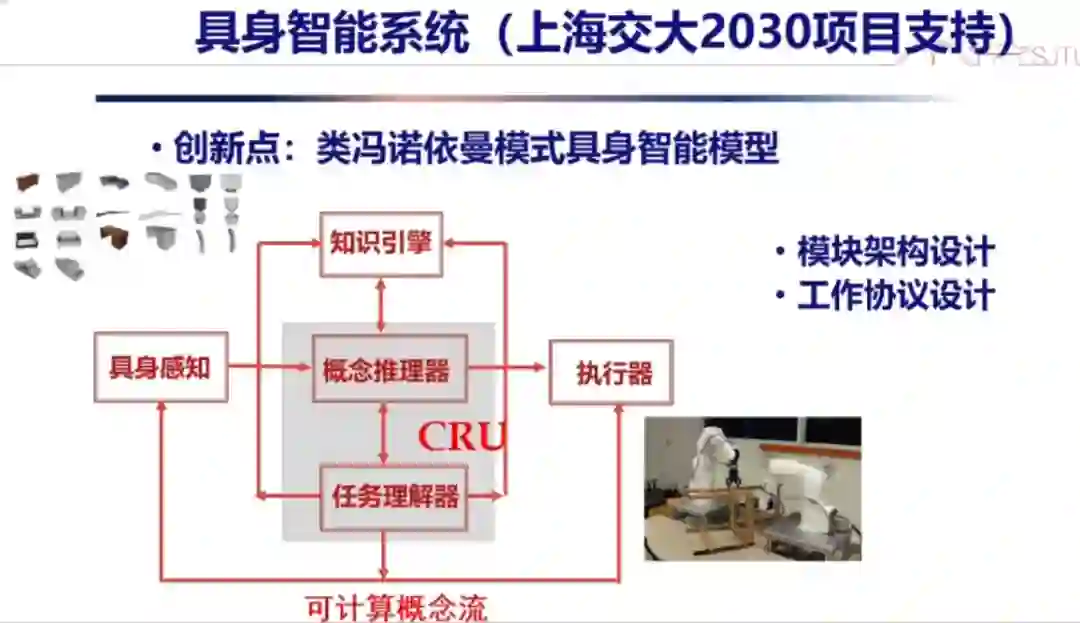
下面我介绍一下我们的工作,就是 PIE 方案,请大家批评指正。 PIE 方案
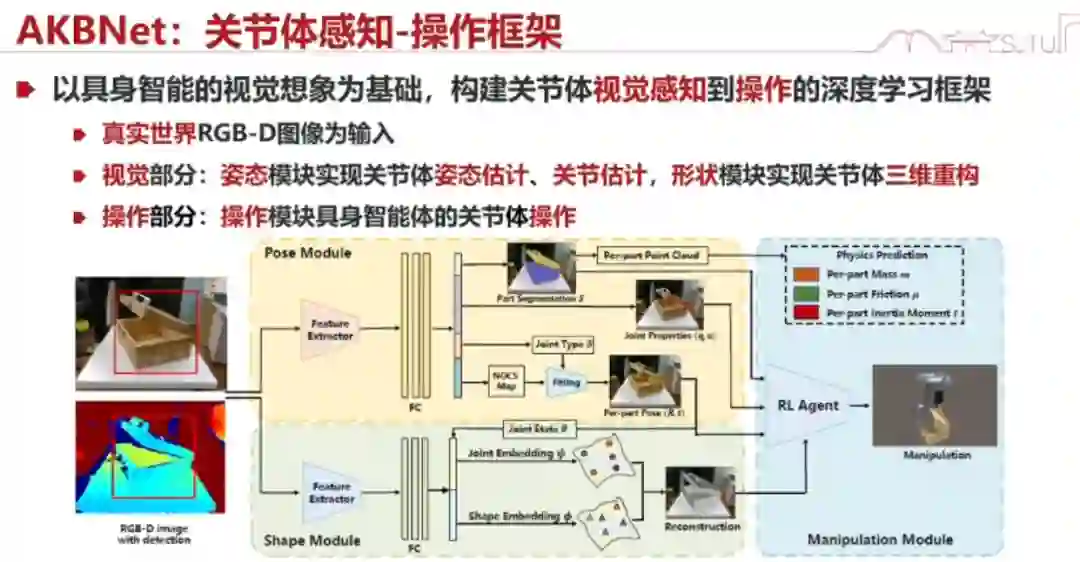
具身智能有哪些模块是一定跑不掉的?我们认为有 3 个模块 —— 具身感知(Perception)、具身想象(Imagination)和具身执行(Execution)。
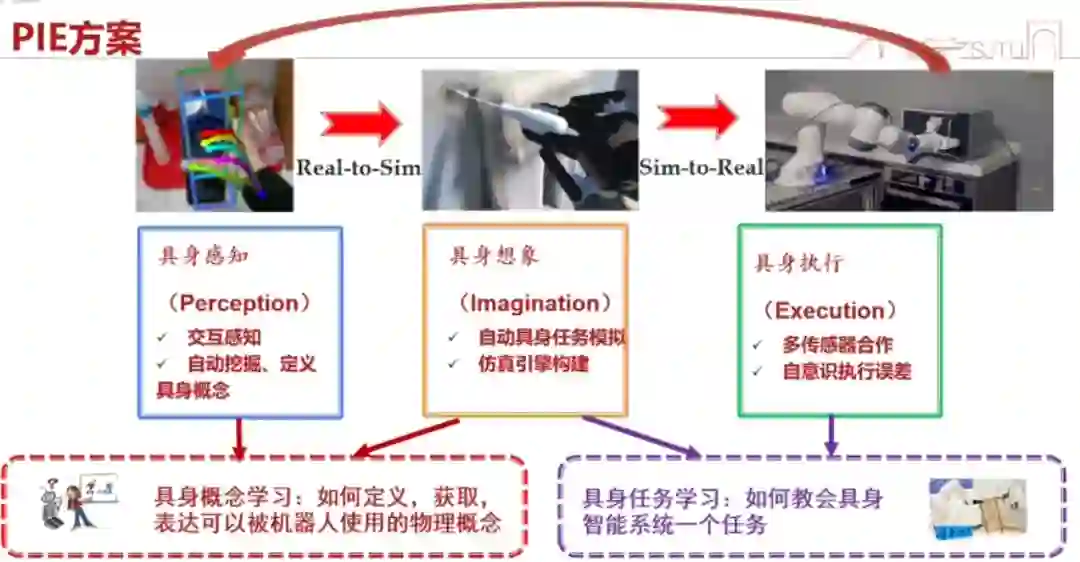
为什么呢?因为我们看到这个事件,我们总是会想象它长什么样子,我们应该怎么去做,虽然很多时候这种想象不是很显式的,是下意识的。然后,我们会去执行,就会落实到实体上面。 下图是一个 Real-to-Sim、Sim-to-Real 的过程,对应着具身感知、具身想象和具身执行。下面一行是我们的几个工作:
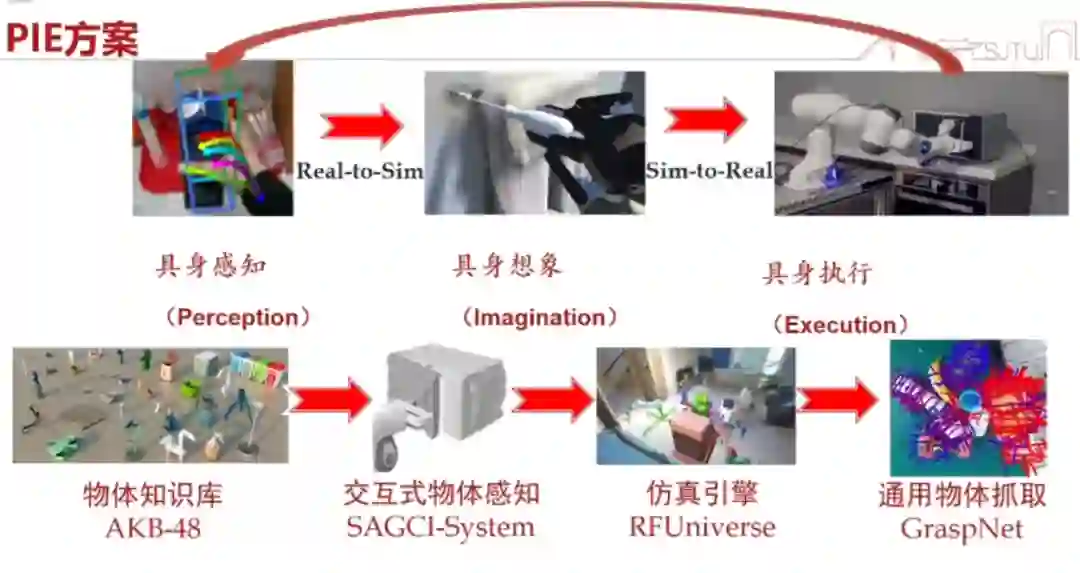
具身感知
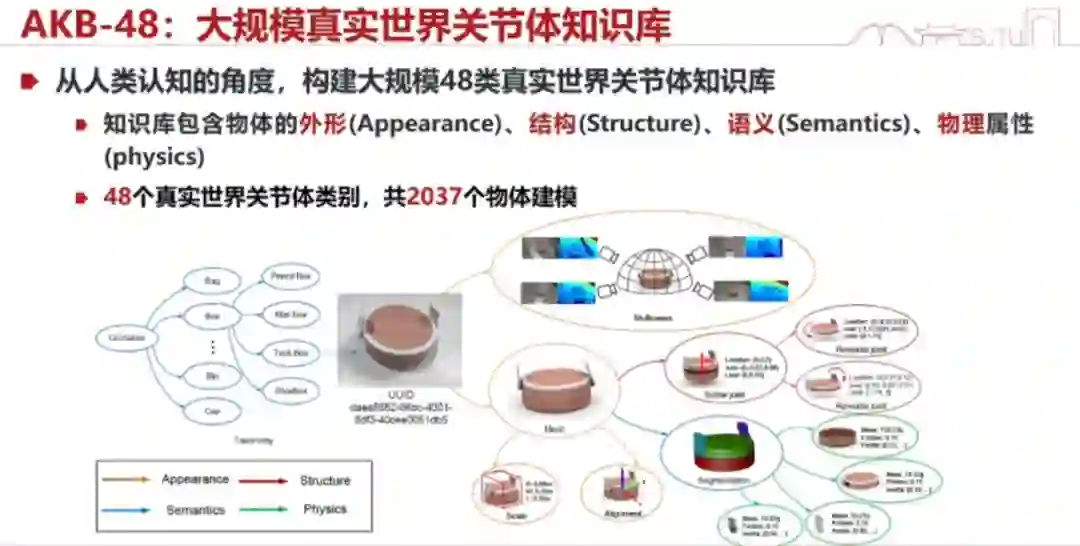
1、全概念感知 首先,我们具身智能的感知应该是什么样的?跟之前计算机视觉的感知有什么不一样?我们觉得它应该是一个全感知。全感知的意思就是,我们能够知道我们所操作的这个世界模型(world model)的各种各样的知识,跟操作相关的知识,包括外形、结构、语义,以及 48 个真实世界关节体类别等等。
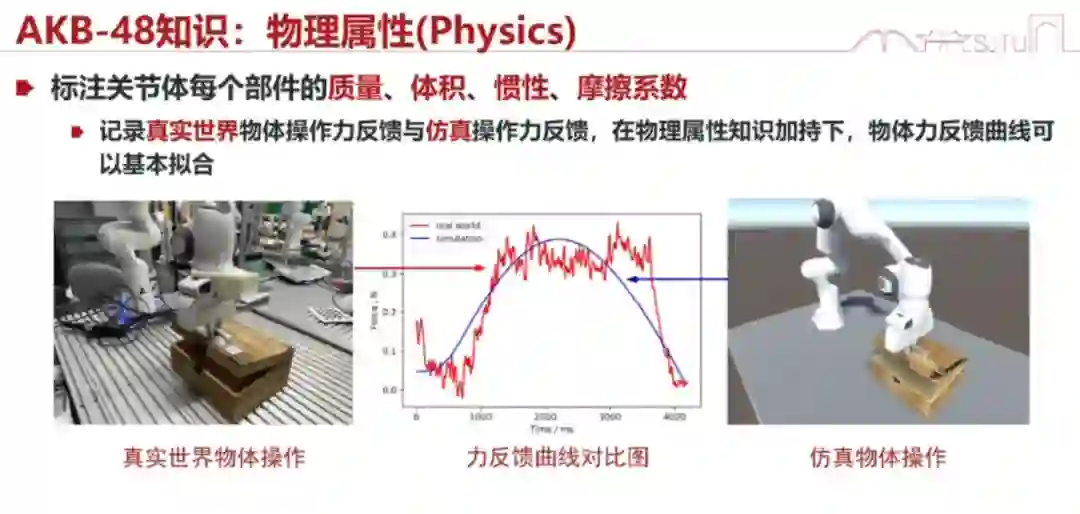
举个电饭锅的例子。我们检测到这个电饭锅就结束了吗?其实不是,我们要知道它怎么拧动、怎么开的。我们能够通过视觉,在没有接触的时候就大概知道它是个什么样子。此外,我们还有新的任务,比如还要标注它的语义、知道它的外形以及猜它的物理属性。猜物理属性是很有可能的,因为它是能猜出来的。猜得对不对倒没关系,猜个大概就行。比如人类看到一个桶,我们也会估计它有多重,你能估计出大概范围,然后在这个范围内去微调与它相关的力或交互,我们下个工作会讲这个事情。
我们现在来检验我们的检测(感知)对不对。除了检测物体的某个部件(比如箱子的轴)在哪里之外,我们还需要检测能否在它上面完整地完成任务。比如我检测一个箱子,检测完了之后我能够在仿真里面顺利地打开它,证明我的检测(感知)是对的。
这是视觉部分我们检测的一些结果:

当然,我们也做了一个数据集:AKB-48。
接下来我们来讲讲具身交互感知。 2、具身交互感知 具身交互感知是什么呢?我们作交互的时候,其实除了视觉,还有触觉,还有各种内容交互的感觉。这些感觉其实也会带来新的感知。就像我们刚才讲的提一个桶或者打开微波炉,我们其实没办法从视觉上知道大概需要多少牛的力,所以其实很多时候我们对这个模型的估计是通过交互来获得的。
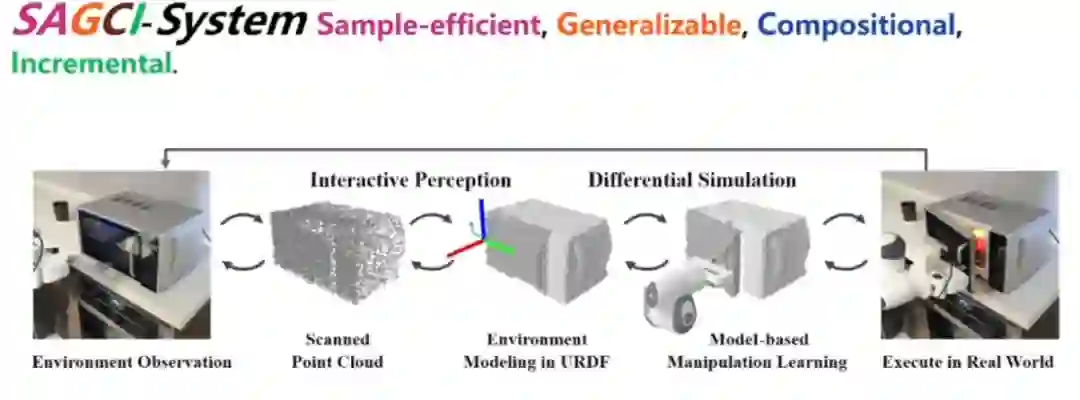
我们会通过一个 initial environment 来做这样的事情。比如说,我们给它一个盒子,或者说一个模型,这个模型会产生一个 URDF,就是一个机器人的描述模型。这个模型不是很准,就像人类去感知的时候。但是你可以去「拉」它,「拉」完之后你就会通过你的仿真,给出下一个模型是什么样子。接下来你还会进行点云的跟踪(点对点的跟踪)。跟踪完之后,这两个点云按道理说应该是一致的。如果不一致就有两个原因,第一是模型不对,第二是仿真的参数不对。当然,仿真参数不对最大的问题还是在于模型不对。我们就把这两个点云一减,计算它们的 loss,减完之后去优化它们的 loss,最小化这个 loss 就相当于逼着它去做对这个模型。
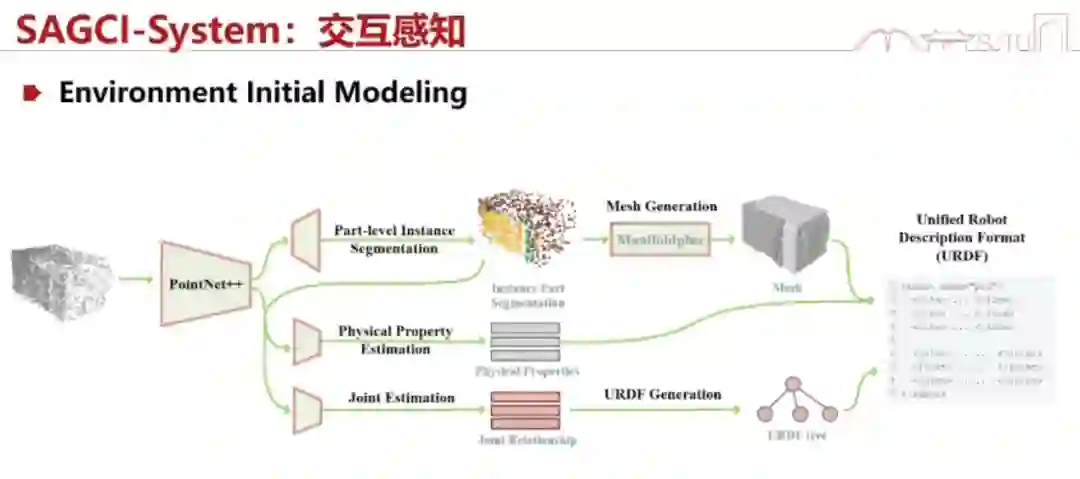
这里面用到了牛顿定律和数据驱动的结合。就像我刚才讲的,我们的视觉可能会有一些问题,包括估计物理参数的时候,但是这些物理参数是被牛顿定律所支配的,只是我们不知道这些参数。比如说我们推一个木块,它一定是符合牛顿定律的,但它的摩擦系数等参数我们是不知道的,只能靠肉眼估。估得不准没关系,我们在交互过程中会估得更准,这和人类激励是一致的。 接下来我们看看 real world experiment 效果怎么样。在这个实验里,我们先让机器人去扫描一个微波炉,扫描完之后让它去拉开微波炉的门。因为这个微波炉它之前没有见过,所以它的轴估计得不是很准,拉的动作也不太好。但是没关系,它已经迅速地学会了拉开微波炉所需的参数,所以后面就做得很好了。

接下来看这个学会之后的视频:

这个时候,机器人已经学会拉开微波炉的门,学会之后就可以在上面加技能了,比如把东西塞进去。这个项目是开源的,大家可以关注。 具身想象
感知的东西都有了之后,你肯定会在脑子里想我该怎么去做,这是一个具身想象的过程。

我们做了一个名为 RFUniverse 的仿真引擎,这个仿真引擎支持 7 种物体(比如关节可移动的、柔性的、透明的、流体的……)、87 种原子操作的仿真。这些操作相当于我们把物体录入之后,我们在仿真引擎里想象它大概应该怎么做。跟以往不同的一点是,我们已经有了这些物体的知识。它也支持强化学习、VR。这个项目也已经开源。


我们还成功探索了从看视频到机器人的行为。也就是说,我给你看 50 个场景,看完之后你就会在你的仿真引擎里去尝试类似的事情,尝试完之后再迁移到真机上。这项研究发表在 CoRL 2022 上。 另外,这套思路还可以放到人体的康复上面,去做医疗看护机器人。这项工作是我们康奈尔大学合作完成的,在 IROS 2022 上获得了最佳论文之一。
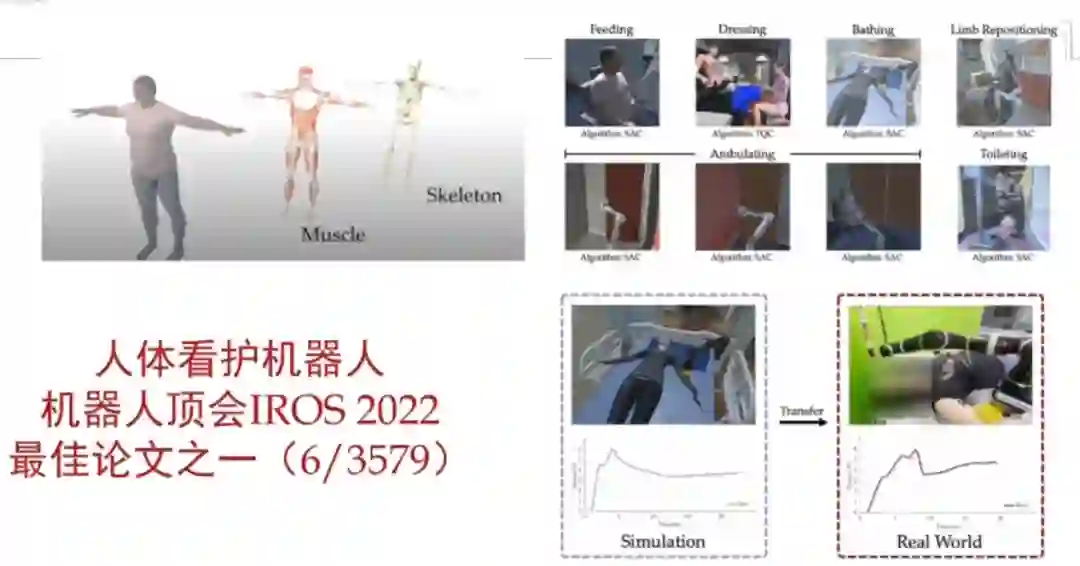
具身执行
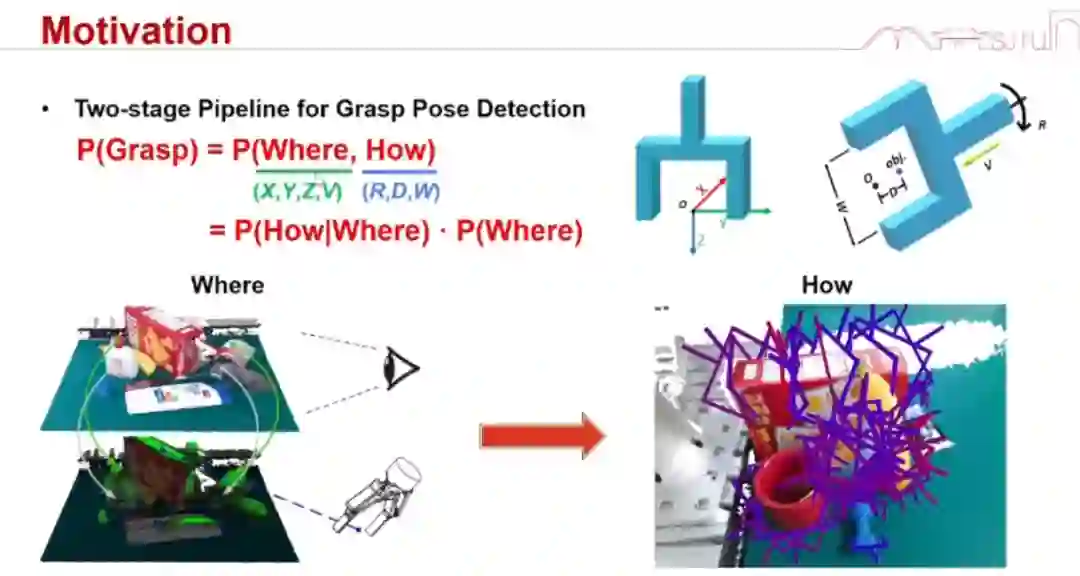
接下来是一个更难的事情:我们想象完了之后怎么去做?大家觉得想完之后去做是不是挺简单的?其实不是,因为你的想象和真实操作是有差距的。而且我们又希望这个操作能自适应于各种事件的变化,这个难度就很大。 我们希望建一个元操作库,这样我们就能调用各种元操作来解决这个问题。在《Mother of all Manipulations:Grasping》这项工作中,我们从 Grasping 做起。给定一个点云,这个点云对应的动作会去抓取,你怎么去产生那些 grasp pose?
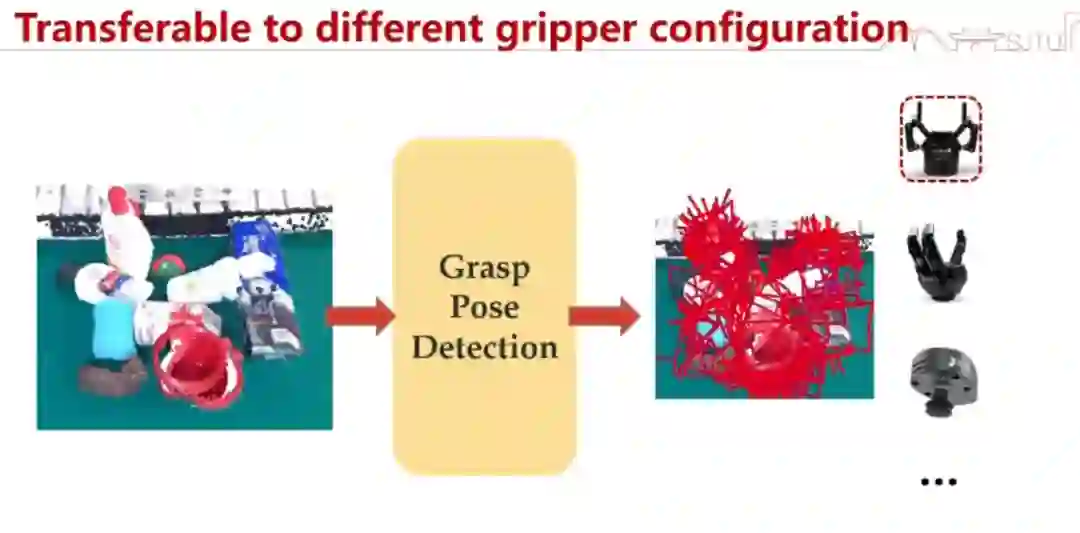
也就是说,这其实要探索的是从 x 到 y 的变换。
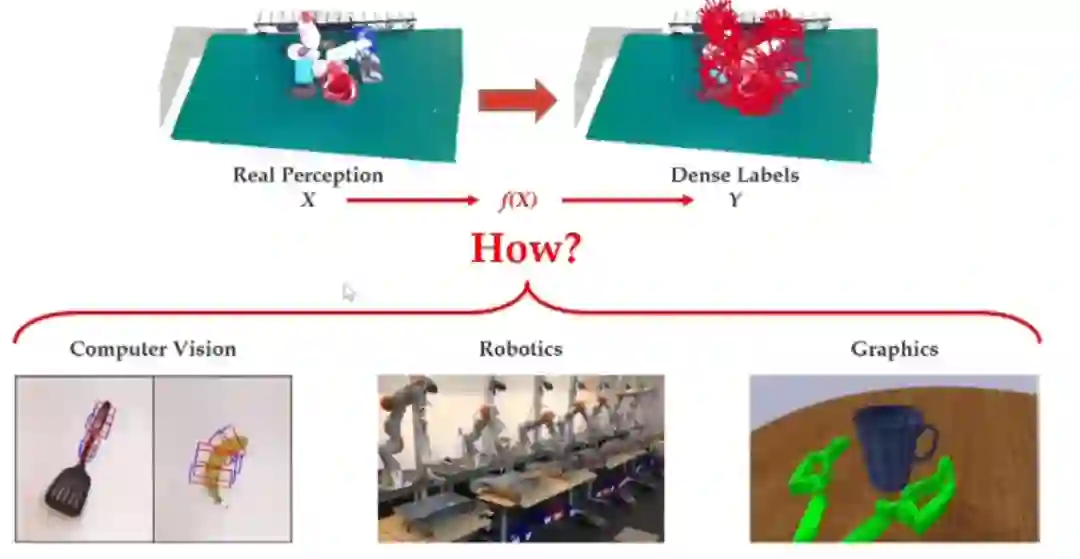
其实,目前有三个领域在做这件事情:计算机视觉、机器人学和计算机图形学。为什么之前的领域做不好呢?首先,如果你用计算机视觉方法去标的话,这些点是很稀疏、很残破的,而且不一定对,所以你产生不了一个密集的标签。如果用机器人学的方法去做,你得到的标签量是很有限的,因为它一天也抓不了几个。如果你用计算机图形学方法,它又不是真实的,这也会有很大的问题。所以,在我们之前,没有一种可行的方法可以廉价地产生大量 x 到 y 的 pair。
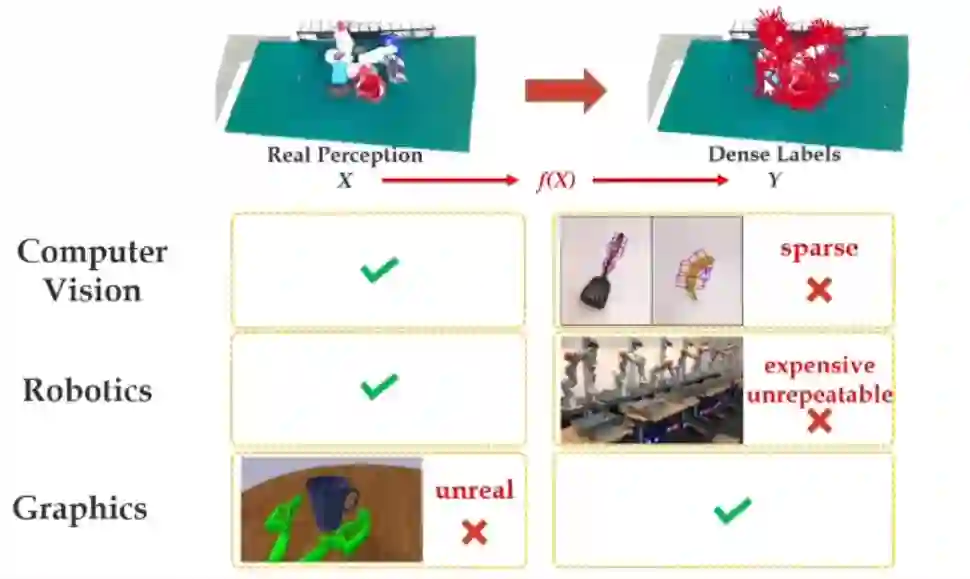
那么,我们是怎么做的呢?我们先扫描物体的模型,得到一个数字孪生。有关物体抓取的力觉模型会在上面起作用。我们可以把它迁移过去,迁移完成后我们什么都有了,然后我们就可以产生这样的一个 pair。
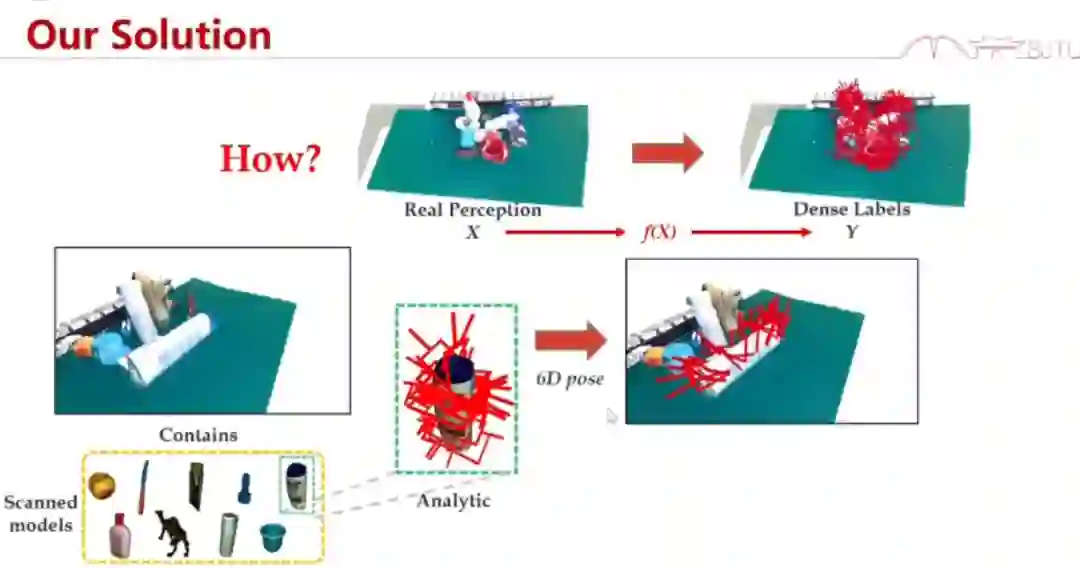
当然,大家可能会说,每次都要扫描、产生孪生模型好累啊。其实,我们采用了半自动的 data collection and labeling,能够非常快速地产生 20 亿个抓取点位。你想要再增加十倍的数据也很容易,但我们发现 20 亿个已经够用了。 有了这个东西之后,我们就要开始训练了。我们把「grasp」这个问题分解为 where(去哪里抓)和 how(怎么去抓)的贝叶斯问题,分别去估测网络。这个方法的准确率远远高于其他方法。
下面是一个抓取瓷器碎片的结果。我们怎么证明我们的方法是通用的呢?就是这种没见过的物体也可以抓起来。这个问题是有难度的,因为你把瓷器敲碎的瞬间,每个碎片都是独一无二的。但是,我们的方法能把每一片都稳定地抓起来。其实,我们能把几千个物体都稳定地抓起来。我们也能抓取一些小的或者动态的物体。这是世界上首个能抓取未知动态物体的机器人。此外,我们还能进行透明物体的抓取。透明物体为什么难?因为它的点云是缺失的。


我们这个论文两年内引用量达到 150+。我们在其中提出了新的数据、标准、算法以及系统。基于这些,我们可以做一个平台,让你不需要真机就能够去验证。这个事情就相当于,你看到的是真实的点云,看到之后你给我一些抓取的姿态,我就能给你返回你的成功率。我们也能做到超越人类水平,达到和人相媲美的 99.5% 的准确率。

以上就是我们前面提到的三个模块,我们也在逐步完善这样一个框架。它们也已经有了一些实际的应用。

具身智能与通用人工智能
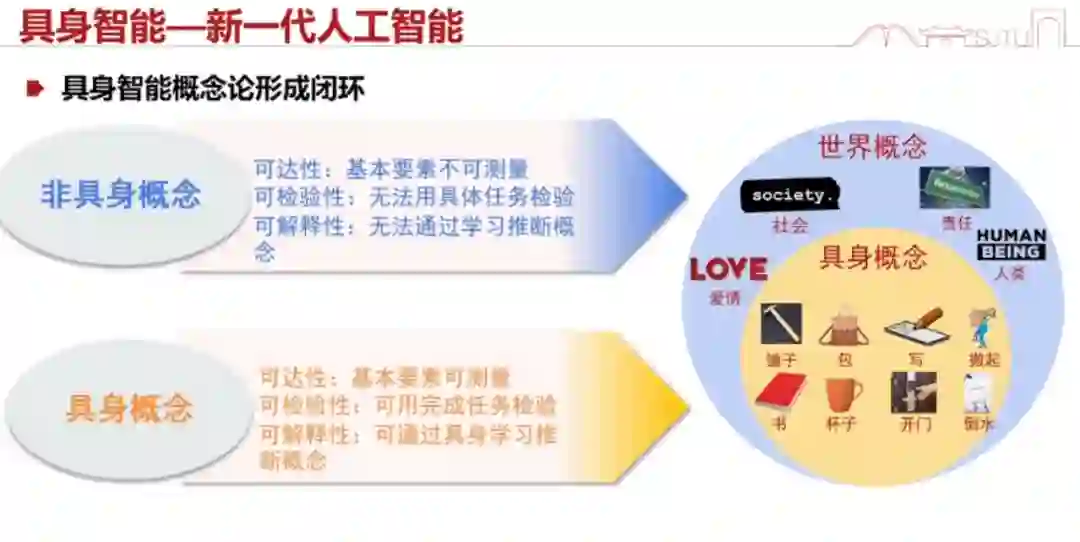
接下来分享一下我们对具身智能与通用人工智能的看法。 为什么说具身智能可能是很好的一个走向未来的方案?人工智能是很多概念的总和。其中有些概念很难被测量或验证,比如让机器理解什么是社会,什么是责任。虽然它能给你输出一个表征,但我们很难检验机器是不是真的理解了这些概念,毕竟对于这些概念,每个人都有自己的看法。所以我们可以先在一些可验证、可测量的概念上面做出个闭环。而具身智能刚好是这样一个闭环,它很容易理解什么是锤子。所以我们认为,这样的具身智能可能是迈向通用智能的一个很好的起点,因为它可测量、可解释、可检验。
在交大,我们做了一个开源系统 ——Robotflow(https://robotflow.ai/),接入了二十几种机器人的程序,非常易于开发和部署,大家可以下载使用。

具身智能的脑认知
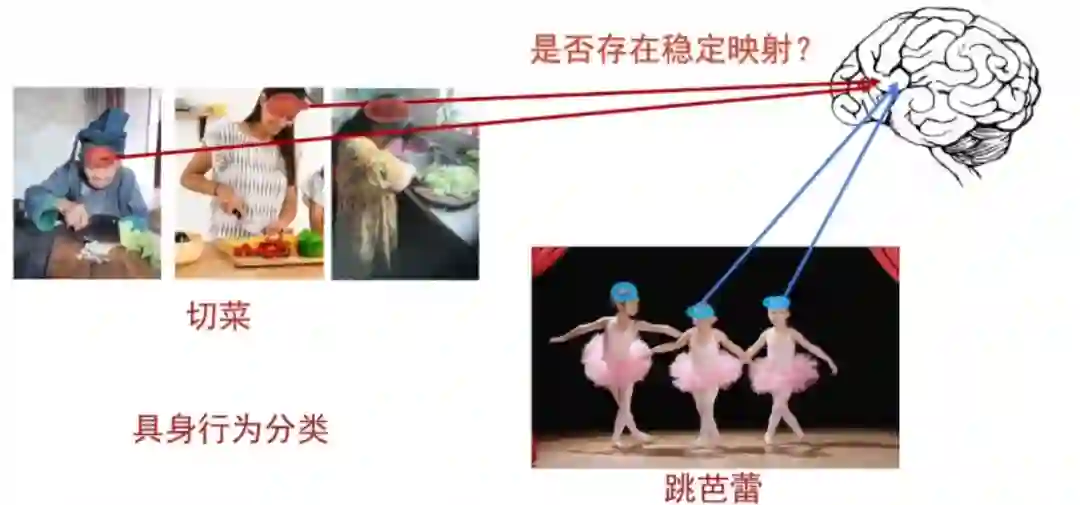
人体是最大的一个具身智能体。我们想知道人体在操作过程中,是一个什么样的机制催生它去做这样一件事情。这就涉及到脑科学,比如人切菜的时候,脑神经在干嘛;跳芭蕾的时候,脑神经又在干嘛。 我们要解决的第一个问题就是:我们看到的这样的视觉表征,和脑神经是否有一个稳定的映射关系。
这件事情在人身上其实很难验证(需要做侵入式实验),所以我们普遍是先做小鼠的实验:去看大规模的小鼠的行为,同时观测他的神经信号。如果二者有稳定的映射,我们就认为这个规律是存在的。 在这样的情况下,我们就通过训练,去提取大量的脑信号标签以及它的行为标签。这里面发挥很大作用的是我们提出的一整套非常鲁棒的行为检测系统,不然行为标签可能存在大量的错误。为什么要自动去检测呢?因为那么多小鼠的数据,人看是看不过来的。我们的实验结果是 93%,证明这种映射是相对稳定的。
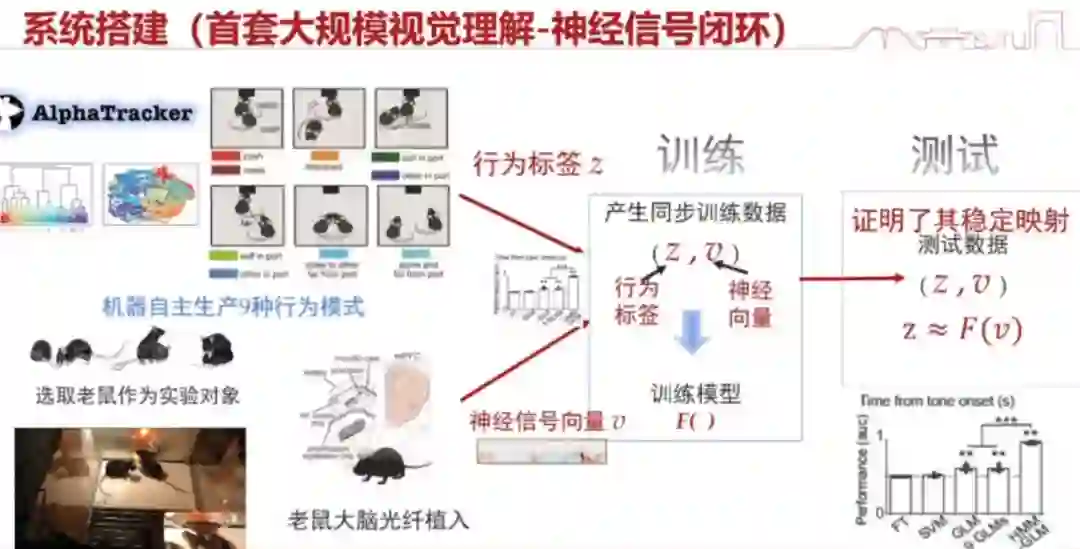
当然,这里面有很多的挑战。我们需要去解决一个重大的问题:行为理解。就是说,理解小鼠的行为其实是一件困难的事情,我们在这方面也做了很多工作。 通过实验我们可以看到,小鼠的神经观测结果和行为的视觉表现是能对得上的,这是一件很神奇的事情。从长远的角度来讲,我们是不是可以把小鼠或者说生物体在做某种行为的时候,它的脑神经状态的表征,作为我们具身智能的一些表征?这个东西可能近 5 年内都没有办法做出来,但其实它对具身智能的发展来说是一个非常好的重点方向。 我们还有一些副产品非常有意思,就是对行为神经学、生物学的一些贡献。如果我们做神经回路,很多时候你要激活某个神经去分析行为。这种方式非常麻烦,不能产生大规模的自动分析结果,导致复杂行为(如社会行为)的神经解析仍然十分困难。有了这套系统之后,我们就能用人工智能的方法去解决它。这其实形成了一种范式的转变。

在大规模的视频跟踪中,我们可以同步小鼠的脑神经信号,去指定它是在哪个地方发生的,控制它的回路是在哪里。通过这种方法,我们成功地定位了控制小鼠社会等级行为的神经回路。这是神经学里面长期存在的一个难题。

我们的相关工作发表在《自然》杂志上。我是这篇文章的通讯作者之一,文章的另一位通讯作者是一位生物学家。我们已经把研究代码和新工具都开源了。有些人给了我们比较好的评价,认为我们是基于人工智能的一种探索行为神经机制的新方法,也有人认为说我们提出了一种很有前景的新算法。 我的讲座就到这里,谢谢大家。

