Sora问世,视频创作领域迎来“iPhone时刻”。2023年2月15日,OpenAI发布视频生成大模型Sora,通过文本指令,Sora可以直接输出长达60秒的高清视频,包含高度写实的背景、复杂的多角度镜头以及富有情感的多角色叙事,更为可贵的是,Sora生成的视频表现出对于真实世界物理常识的深刻理解。部分媒体报道惊叹——“Sora之后,现实将不再存在”。从本轮AI应用端发展实践来看,以文本创作(小说、剧本)、图像创作(绘画、平面设计、摄影)、视频创意(广告、短视频、传统影视、游戏)为代表的创意创作领域因其高容错率、高投入度,在AI浪潮之初就被市场广泛认为将会成为最先被AI深刻赋能的产业之一;从本轮AI模型发展演绎来看,以ChatGPT为代表的文本创作以Midjourney、StableDiffusion为代表的图像创作以Runway、Sora为代表的视频创作的发展速度无疑是极为惊人的。我们认为,从文字到图像到视频,AI内容创作的信息升维越来越考验模型的创作效率与生成结果的稳定性(早期版本的Midjourney存在生成时间长、生成结果违背物理常识或者“AI感”明显的问题;RunwayGen-1/2也存在生成视频时长较短且生成视频逻辑连贯性较弱等缺陷),但正如MidjourneyV5/6已逐步广泛实现多行业的商业化落地,我们认为Sora的问世有望推动着视频创作领域的“iPhone时刻”到来。
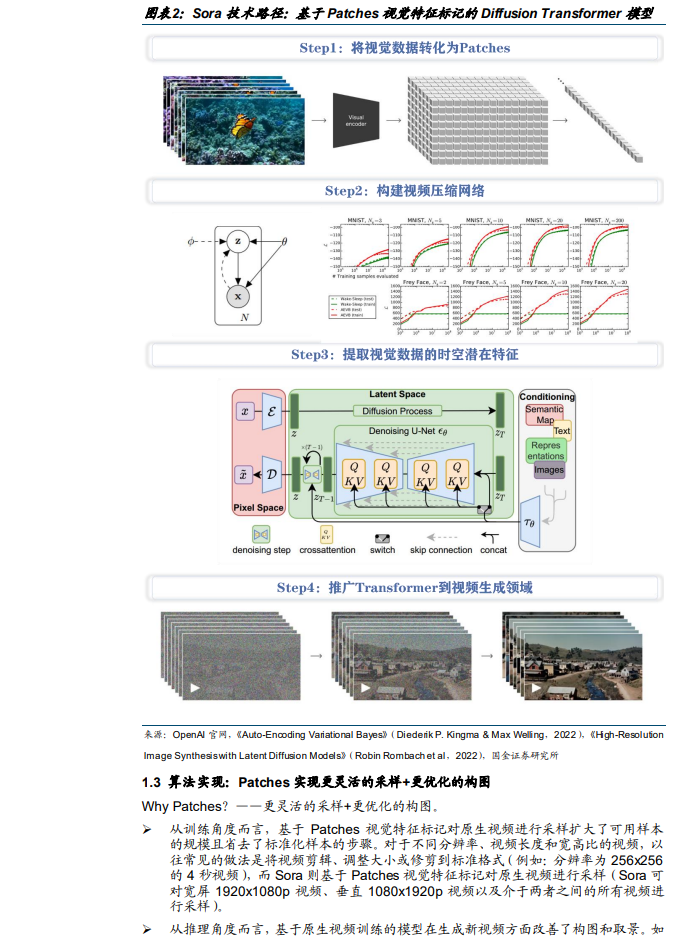
Sora取法Tokens文本特征标记,是基于Patches视觉特征标记的DiffusionTransformer模型。OpenAI研究团队从LLM中汲取灵感,认为LLM范式的成功在一定程度上得益于Tokens的使用,故而通过将视频信息分解为带有时空特征的Patches训练了DiffusionTransformer模型。从训练角度而言,基于Patches视觉特征标记对原生视频进行采样扩大了可用样本的规模且省去了标准化样本的步骤。从推理角度而言,基于原生视频训练的模型在生成新视频方面改善了构图和取景。OpenAI目前发布的Sora视频大模型主要具备文生视频、视频编辑、文生图三类功能,在文生视频过程中,用户通过输入Prompt提示词DALL·E生成图像Sora生成视频。 文生图和文生视频是当下AI应用端落地焦点,海外相关技术产品迭代迅速。据Discord,按邀请页面流量排序的十大AI应用程序中,有5个是图片生成应用程序,2个是音频生成应用程序,2个是视频生成应用程序,其中,Midjourney位列第一,Pika位列第二,图片约占前10名流量的74%,视频约占前10名流量的8%。文生图领域,海外有Adobe(老牌创意软件巨头,现已发布下一代Firefly支持多种文生图功能)、Midjourney(文生图模型新锐,现已广泛实现商业化落地)。文生视频领域,海外有Pika(AI初创公司,支持一键生成3秒共计72帧视频)、Runway(拥有最早商业化的T2V模型RunwayGen-2)。 国内推荐关注万兴科技和美图公司等创意软件龙头投资机会。万兴于2023年9月宣布即将发布国内首个专注于以视频创意应用为核心的百亿级参数多媒体大模型“天幕”,具备一键成片、AI美术设计、文生音乐、音频增强、音效分析、多语言对话等核心能力。2022年底至2023全年万兴对旗下T2V/I多款拳头产品进行AI功能更新,AI赋能之下订阅收入占比及订阅续约率取得双增。美图公司于2023年12更新视觉大模型MiracleVision4.0,具备文生视频、图生视频、视频生视频等多模态能力,AI赋能之下订阅业务收入占比逐年增长。