深度监督学习模型需要大量标注数据才能获得足够好的结果。然而,收集和标注如此大规模的数据既昂贵又费力。近年来,自监督学习(SSL)在视觉任务中的应用引起了广泛关注。SSL的直觉是利用数据内部的同步关系作为一种自我监督的形式,这种方式具有多样性。在当前的大数据时代,大多数数据是未标注的,因此,SSL的成功依赖于找到改进这些大量可用未标注数据的方法。因此,深度学习算法更应减少对人工监督的依赖,而是专注于基于数据内部固有关系的自我监督。随着视觉Transformers(ViTs)的出现,它们在计算机视觉中取得了显著的成果,因此有必要探索和理解在标注数据较少的情况下,用于训练这些模型的各种SSL机制。在本综述中,我们系统地分类了SSL技术,依据其表示和预训练任务开发了一个全面的分类法。此外,我们讨论了SSL的动机,回顾了流行的预训练任务,并强调了这一领域的挑战和进展。最后,我们对不同的SSL方法进行了比较分析,评估了它们的优缺点,并指出了未来研究的潜在方向。
1 引言
基于深度学习的算法在多个领域,尤其是计算机视觉 (CV) [1] 和自然语言处理 (NLP) [2] 中展示了令人印象深刻的成果。深度学习模型通过在大规模数据集上进行预训练任务来提升其性能。这个主要步骤通常作为初始化点,然后对模型进行优化以适应任何特定的应用场景。自监督学习 (SSL) 是深度学习算法预训练策略之一。总体而言,SSL 方法受到两个主要动机的驱动。首先,在大规模数据上训练过的网络已经学会了可以应用于后续任务的独特模式。这也有助于减少训练过程中的过拟合问题。其次,从大规模数据中学习到的参数提供了有效的参数初始化,这使得不同应用中的收敛速度更快 [3]。
尽管在大数据时代有大量未标注的网络数据,但获得具有人工标注的高质量标注数据可能代价高昂。例如,数据标注公司如 Scale.com [4] 为图像分割标注收取每张图像 6.4 美元的费用。创建一个包含超过 100 万个高质量样本的图像分割数据集(如 JFT-300M)可能耗资高达数百万美元。通常,这个过程既耗时又低效 [5]。此外,监督学习的方法容易在数据集中学习到误导性的关联,这可能导致错误,从而更容易受到对抗性攻击的利用。
为了应对监督学习中提到的挑战,提出了几种学习策略,如主动学习 [6]、半监督学习 [7] 和自监督学习 (SSL) [8]。最近,Transformers [9] 作为一种有效的神经网络 (NN) 架构,尤其是视觉Transformers (ViTs) [10],被认为是卷积神经网络 (CNNs) [11] 的替代方案。ViTs 已成功应用于计算机视觉相关任务,如目标检测、识别和语义分割。值得注意的是,ViTs 在使用大规模数据集(如 JFT-300M [12])进行训练时,在图像分类中表现出色。
本质上,通过设计前置任务,使网络的预训练阶段鼓励模型在数据中自行学习重要的模式,SSL 方法使得 ViTs 能够在没有任何监督的情况下理解数据的潜在结构。将 SSL 应用于 ViTs 的动机有两个方面。首先,SSL 允许 ViTs 利用现成的大量未标注数据,使其能够开发出更健壮和更具泛化性的表示。SSL 在标注数据稀缺或获取成本高的情况下尤为有利。其次,SSL 为 ViTs 在大规模数据集上进行预训练提供了一条途径,随后通过微调特定任务,提高了性能并加速了收敛 [5]。
1.1 综述范围和贡献
已经有几篇与自监督学习相关的有趣综述被报道。然而,这些SSL综述通常专注于特定领域,如推荐系统 [13]、图结构 [14][15]、序列迁移学习 [16]、视频 [17] 和算法 [5]。视觉Transformers (ViTs) 是计算机视觉领域的一个重要研究方向,最近在多个领域取得了突破性进展。然而,ViTs 的训练仍然充满挑战。因此,本综述与现有综述不同,探索了为 ViTs 提出的各种自监督学习方法。
1.2 综述结构
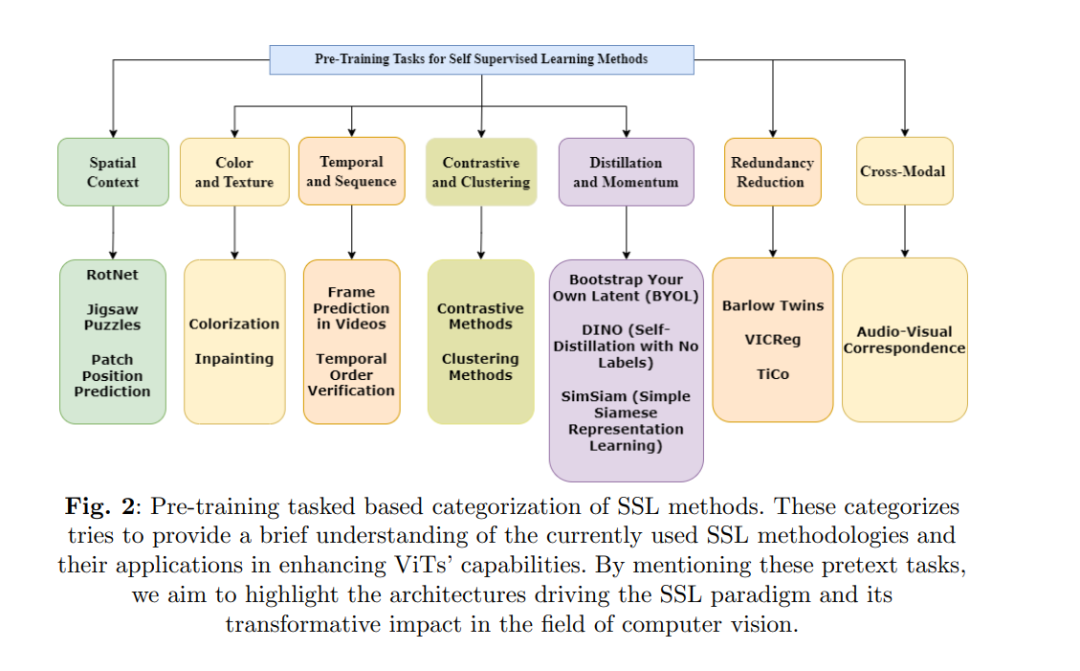
本文首先介绍了自监督学习,并详细讨论了其在视觉Transformers中的重要性。报告的SSL方法根据其独特特征分为五类。本文讨论了SSL在不同计算机视觉任务中的最新进展和应用。此外,本文还提出了一个SSL的分类法,根据其在架构中应用特征学习的方式进行分类。根据这一分类法,SSL被分为五组,每组代表了利用输入特征的独特方式。常用的缩略词列在表1中。本文结构如图1所示。第1节讨论了SSL架构的系统性理解,强调了其在ViTs中的需求,并概述了SSL架构的兴起。接下来,第2节涵盖了SSL变体的进展,而第3节则提供了最近SSL架构的分类法。第4节集中于SSL在计算机视觉领域中使用的正则化技术,第5节介绍了用于评估SSL有效性的不同指标和基准,第6节讨论了使用视觉Transformers的最新SSL机制的比较分析,第7节提到了自监督学习领域的一些开放性挑战,第8节讨论了SSL在视觉Transformers中的不同应用及未来方向,包括当前挑战和潜在发展。最后,第9节总结了这篇综述文章。