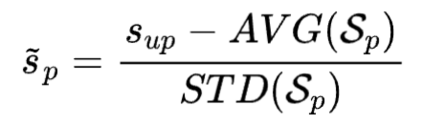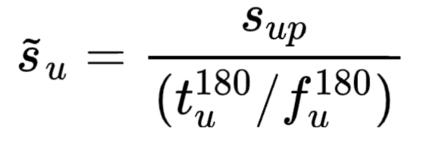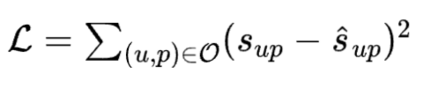论文地址:https://arxiv.org/abs/2404.08301 项目地址:https://zenodo.org/records/10775846
现有的在线服务系统多数关注 CTR 和 CVR 指标,然而,如何更加精准的推测用户对平台的价值对于实现精准广告和服务推荐更有意义。在本研究工作中,我们以如何测用户主观上愿意多付费的游戏产品,并推荐给用户为研究任务,对该任务进行探索。
直观来看,把用户更满意的商品推荐给用户应该就可以激励用户付出更多的时间或者支出。然而,模型的上线对于现有的业务方来说是一个很严肃的事情,只有达到业务方的指标,才会被允许进行在线测试。但是如何在离线状态下评估模型是否有潜力使得平台获得更多收益是一个非常有挑战的事。因为用户的具体付费行为受到多种难以观测到的因素的影响。不过我们在这项研究工作中并没有针对这个研究任务展开更多的探索。我们最终仍然基于目前业务上使用的评估手段对模型的有效性进行评估。
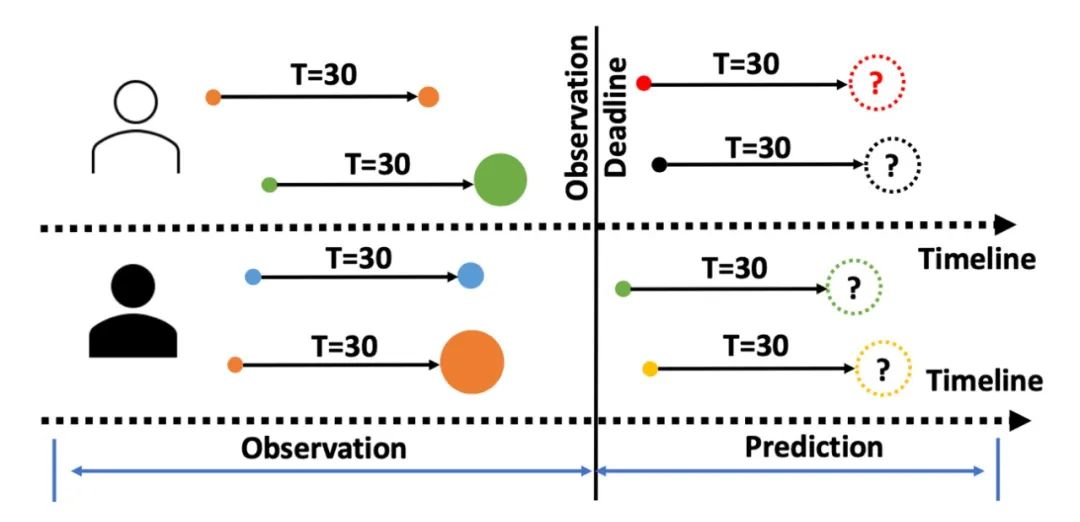
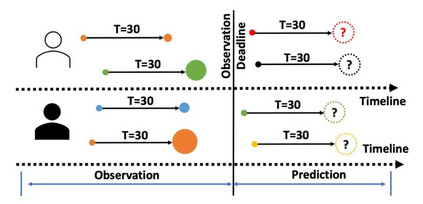
图1 基于用户在新下载游戏上的付费记录划分训练集和测试集
为帮助读者更好地理解我们的研究工作,我们先对现有的业务场景中使用的数据和模型训练以及评估方式进行简单介绍。如图1所示展示了现有的用于研究的训练数据和测试数据。对于每个用户,分别收集了其下载记录,以及下载 30 日内对下载的游戏的付费记录。确定某个观测时间点为训练集和测试集的划分曲线,其中观测observation 区域中的数据被用于训练模型,prediction区域中的数据被用于测试训练得到的模型。不同颜色的圆表示不同的游戏,T=30 表示经过 30 天之后。T=30 之后指示的圆表示用户在目标游戏上的花销金额大小。圆越大表示用户花钱越多。当前任务目标就是预测在观测线之后,用户自下载游戏 30 天后在目标游戏上的花销金额。需要注意的是,现有的业务模型也是基于该框架进行训练的。并且训练得到模型在测试集上相对于真实消费金额的差距被用于评估模型的有效性。具体采用的评估指标是 r2_score,该指标是一个类似 MSE 的指标,用于衡量模型在测试集上的预测消费金额和观测到的真实消费金额之间的差距。 表 1 用户付费数据统计信息
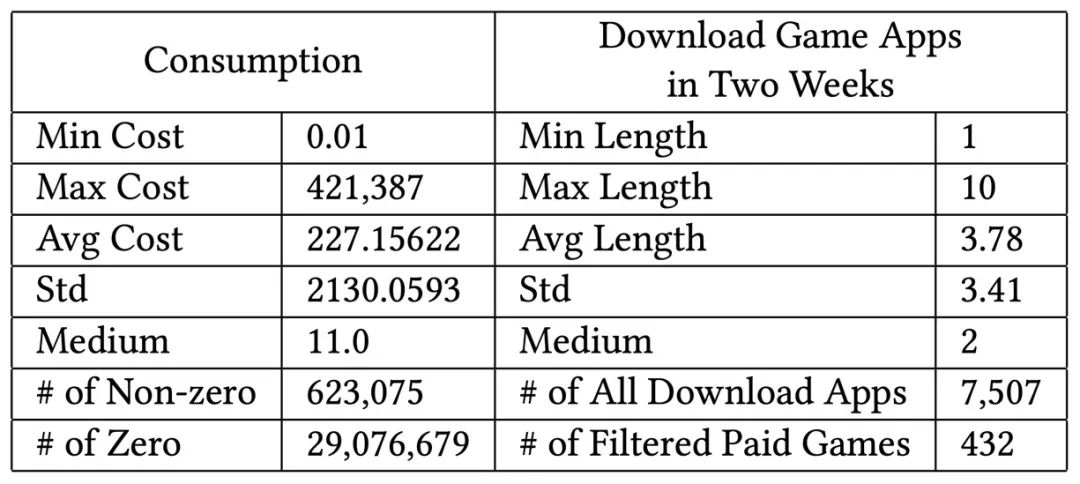
为了使得我们研究的模型可以被认可具备上线资格,我们需要在现有的评估体系下相对于业务模型取得更优异的表现。然而,收集到的用户在游戏上的付费数值分布比较怪异,比如存在大量的 0 值,部分用户在游戏上的消费数值极高,非 0 值消费记录方差极大。在表 1 中,我们展示了统计的用户付费标签的最大值,最小值,平均值,标准差,中位数,以及0 值付费记录和非0 值付费记录。看到这么怪异的数字,我们会预料到这项任务将会非常艰巨,甚至感觉用户的消费金额是无法预估的。但是很意外的是,虽然模型训练不够稳定,但是还是可以反映出表达能力更强的模型在用户消费金额预估任务上可以取得更优异的表现的。在后续的实验阶段可以看到这一点。
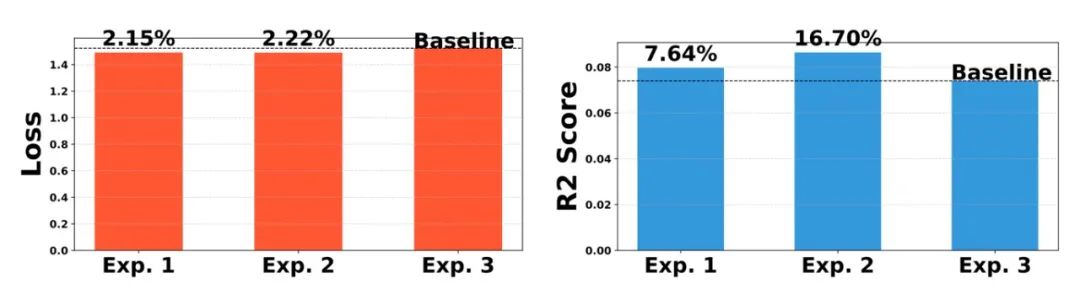
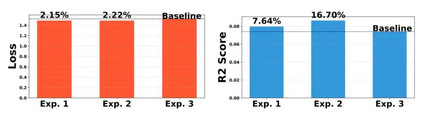
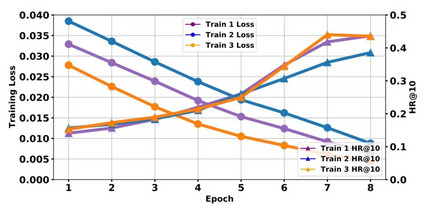
图 2 模型训练损失数值和模型在测试集上对应的评估表现虽然如此,在继续推动我们研究的时候,我们还是发现分布如此怪异的标签数据导致现有评估体系存在一个弊端,即模型很容易出现在损失函数上的表现和测试集上的评估表现不一致问题。如图2 所示。其中 Exp1 ,Exp2 和 Exp3 是开展的 3 次实验,三次实验均为同一个模型的多次训练结果和测试表现。可以看到,虽然从损失函数角度,同一个模型的 3 次表现相差不大,但是从评价指标上来看,该模型的 3 次表现出现很大差异。这就可能会带来一个问题,我们提出的新模型在测试集上的表现也可能会出现类似这种很大差异的现象。从而很难快速判断我们提出的模型是否表现更好。虽然我们发现在当前评估体系下,应该发挥更高性能的模型在多次实验下必定展示出稳定提升,但是这种模型表现差异很大的问题终将给研究新模型带来不少困扰。比如会拖慢研究的速度。所以我们就针对这种现象做了模型训练和评估框架的设计,希望可以基于我们提出的框架实现对不同模型有效性的更稳定评估,加快科研人员的探索速度。
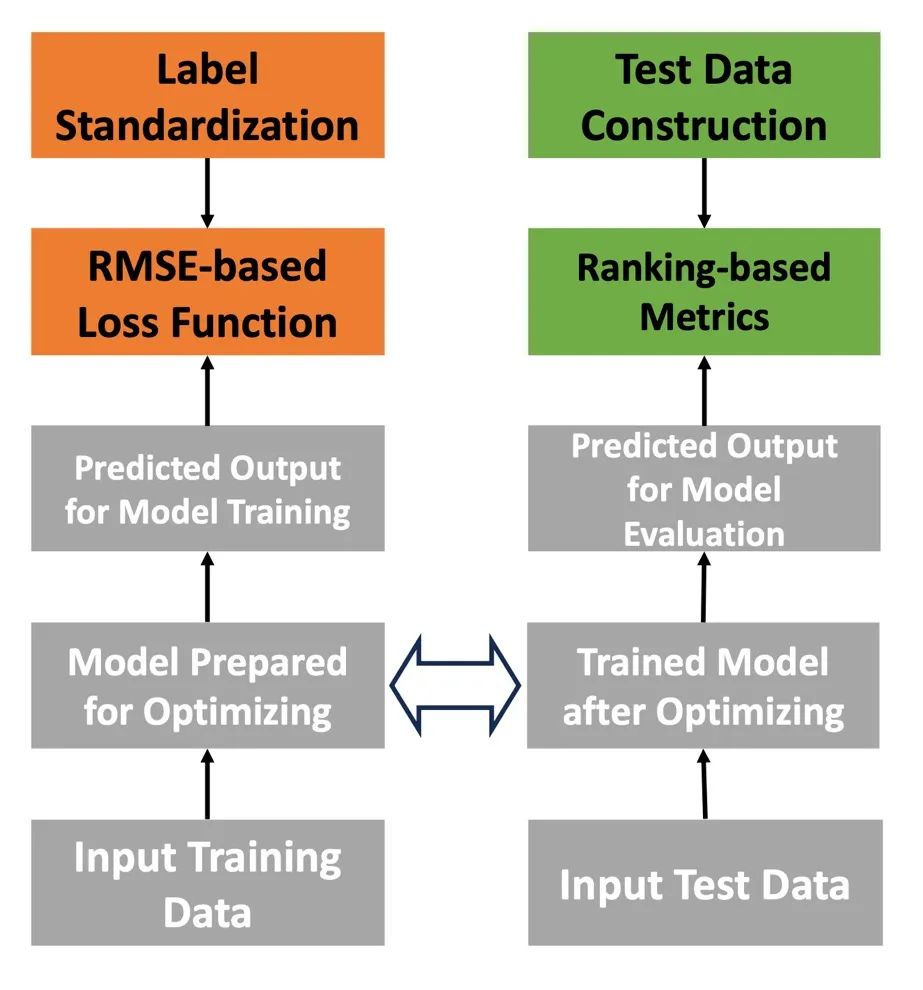
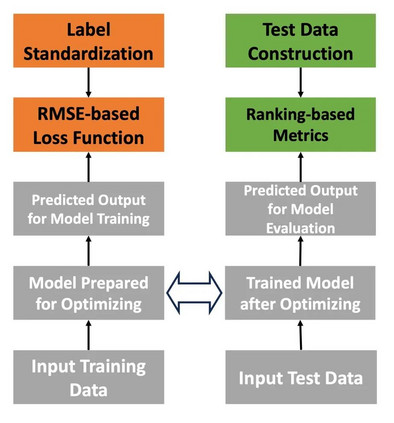
图 3 加速模型设计的框架 具体而言,我们从训练损失函数的设计和评估策略设计两个角度出发进行了加速我们研究的框架的设计,主要为了实现模型损失数值和测试集上表现的一致性,如图 3 所示。从损失函数设计层面,我们提出了标签标准化的方案,并将标准化后的标签用于模型训练。为了降低怪异的标签分布对模型训练带来的负面影响。同时,我们在模型评估阶段,提出了使用排序指标替代现有的 r2_score 指标。因为我们认为,虽然模型在预估具体的标签金额时,会受到多种未观测到因素的干扰,难以取得精准表现。但是排序指标可以用于评估模型是否能够发现用户更愿意付费的产品,从而降低未观测到因素对模型评估的负面影响。具体而言,我们的标签标准化分为三个步骤,分别是用户侧标准化,产品侧标准化,以及结合用户和产品双侧标准化数值的标签标准化。
首先是用户侧标准化的过程,我们基于待推荐游戏的消费历史,求取用户对游戏的价值衡量值。具体来说,针对游戏,结合游戏对应的历史消费记录集合,可以对游戏对应的标签数据进行标准化,从而得到用户对游戏的价值衡量值(即游戏在用户心目中的价值数值)。具体地,对标签数据进行标准化的过程如以下的公式所示。
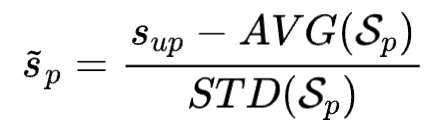
其中, 表示用户对游戏 的价值衡量值; 表示训练数据集中用户 针对游戏 的消费金额; 表示游戏对应的消费历史中所有消费金额的均值; 表示游戏 对应的消费历史中所有消费金额的标准差。 由以上的公式可以看出,代表游戏的整体消费水平,与之间的差值越大,代表用户对游戏的付费意愿越高,即用户对游戏的感兴趣程度越高。 并且,通过上述的标准化过程,能够有效地表达用户对各种游戏的感兴趣程度,确保针对不同的消费金额都能够实现以同一个标准来确定用户对游戏的感兴趣程度。举例来说,有些游戏本来就是高付费游戏,那么相对于低付费游戏,如果用户在两种游戏上花费相同的钱,则说明低付费游戏对用户而言价值更高,即用户对待付费游戏的感兴趣程度更高。 其次,是针对游戏侧的数值标准化的过程。基于用户的消费历史,求取待推荐游戏在用户已消费金额中的消费占比。具体地,待推荐游戏在用户已消费金额中的消费占比可以如以下的公式所示。
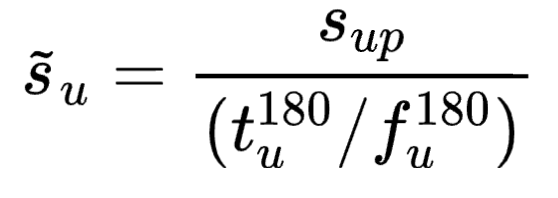
其中,表示待推荐游戏在用户已消费金额中的消费占比;表示训练数据集中用户针对游戏的消费金额;表示用户过去180天在游戏上的总消费金额;表示用户过去180天的总消费次数。 最后,结合用户对游戏的价值衡量值以及待推荐游戏在用户已消费金额中的消费占比,求取用户对待推荐游戏的感兴趣程度,得到训练数据标准化后的标签。
具体来说,同时结合用户侧的标准化消费数值和游戏侧的标准化数值,可以计算得到最终的标准化数值。其中,为用户对待推荐游戏的感兴趣程度,表示训练数据标准化后的标签。在具体的模型训练过程中,我们将上述得到的数值进行模型损失函数计算,用于指导模型的学习。
在模型评估阶段,构建评估数据。对于测试集中任意用户和待推荐游戏交互记录,随机从基于所有游戏构建的游戏池随机选择100个未交互游戏作为负样本,并采用符号表示由100个负样本所构成的负样本集合。在本实施例中,负样本是指在用户曝光范围内但用户并未与之互动的内容(即用户未消费的游戏)。基于评估数据评估训练后的多个候选的内容推荐模型,确定上线应用的目标模型。
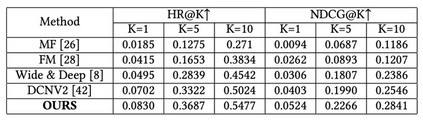
在模型评估阶段,针对测试集中任意用户与待推荐游戏的交互记录(,),首先获取该交互记录对应的负样本集合,然后通过多个训练后的候选的内容推荐模型计算用户对产生交互的游戏的感兴趣程度,以及用户对负样本集合中每个负样本的感兴趣程度,并将所有获得的感兴趣程度进行排序。然后,借助指标k的命中率(Hit Rate at k,HR@K)和归一化折损累计增益(Normalized Discounted Cumulative Gain at k,NDCG@K)评估用户真实交互的产品对应的感兴趣程度是否排在靠前的位置,从而可以借助最终的评价指标HR@K和NDCG@K对应的数值对训练得到的训练后的多个候选的内容推荐模型的有效性进行评估。
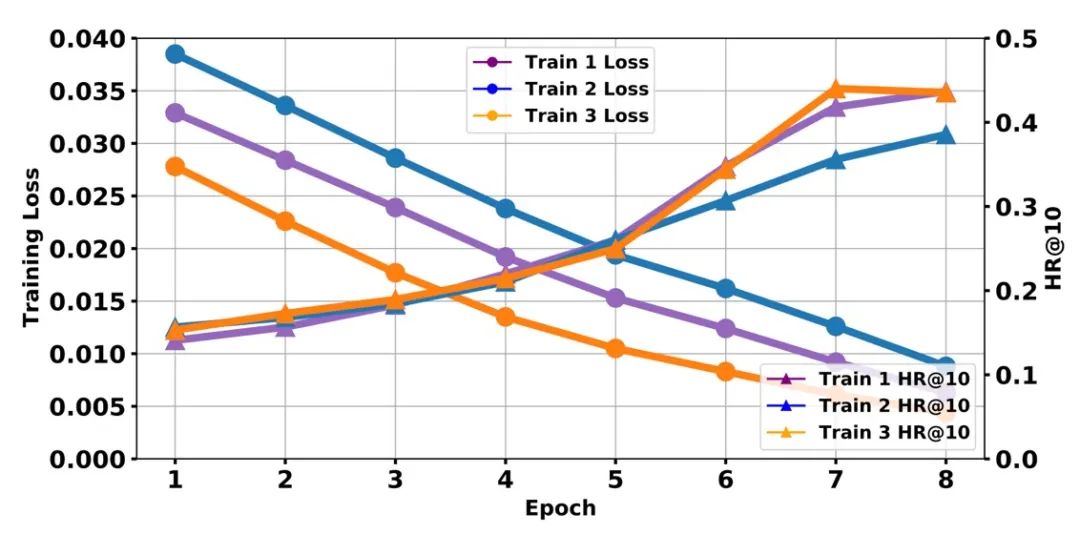
图 4 基于提出框架的模型损失函数和测试集上表现一致性验证为了验证我们提出的框架的有效性,我们分别从基于该框架训练得到的模型的损失值和评估数值一致性,以及是否可以使得拥有不同表达能力的模型在当前框架下的表现也保持一致。同时,我们也会对我们提出的标签标准化策略,以及排序指标的有效性进行验证。实验结果如下所示。从图 4对应实验结果中看出来,该框架在验证模型训练和测试稳定性方面表现一致。
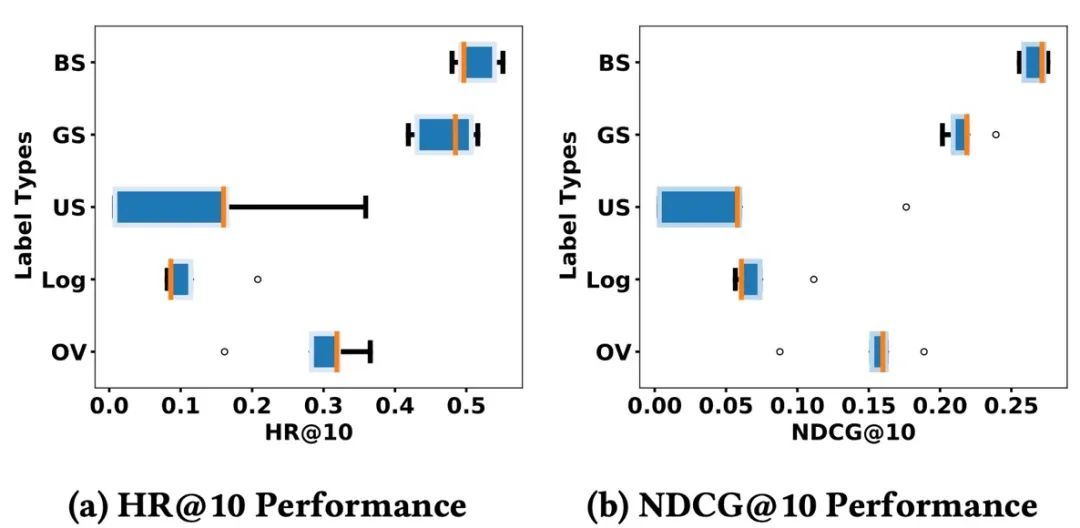
图 5 不同标签标准化策略对应模型评估表现同时为了测试我们提出的标签标准化方案以及排序指标进行评估的稳定性,我们分别设计了消融实验,测试了不同组合形式的标签标准化方案,测试不同的标签标准化方案对模型训练稳定性的影响。其对应实验结果如图5所示。实验结果表明,同时考虑了用户和产品侧的标签标准化方法可以使得在我们提出的框架中验证的模型取得更稳定的表现。 表 2 基于评估框架多种评价指标稳定性评估
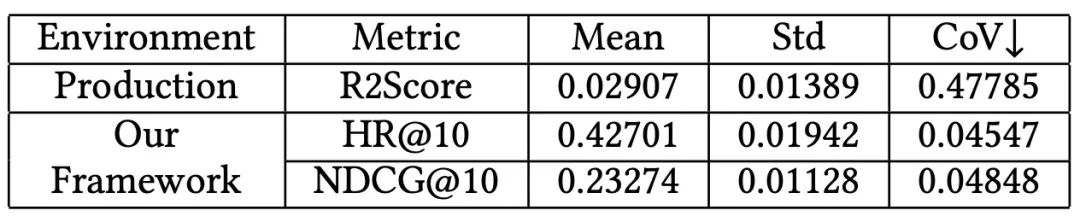
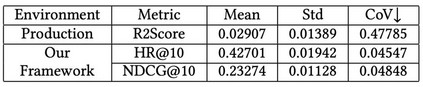
除此之外,我们验证了我们的排序指标在模型评估稳定性上的表现。实验结果如表2所示,可以发现相对于 r2_score 指标,我们的排序指标明显可以取得更加稳定的表现。
虽然我们提出的框架的有效性被验证了。但是仍然存在一个问题,我们提出的框架验证有效的模型在基于 r2_score 评估的业务模型框架下,仍然可以取得比较好的结果吗?我们难以针对这个问题进行理论分析。但是我们直觉上觉得是会呈现正相关关系的。因为大部分用户交互数值都为 0,所以在预测阶段,模型的预测倾向性也会偏向于 0。所以对于用户更愿意付费产品关系的发掘,有利于提升模型非 0 数值任务上的预测表现。因此,我们将基于我们提出的框架探索如何帮助用户发现其更感兴趣的产品。值得一提的是,虽然最终的实验结果反映我们设计得到的模型取得了更好的表现,不过很可惜并没有针对这个推测进行深度验证。
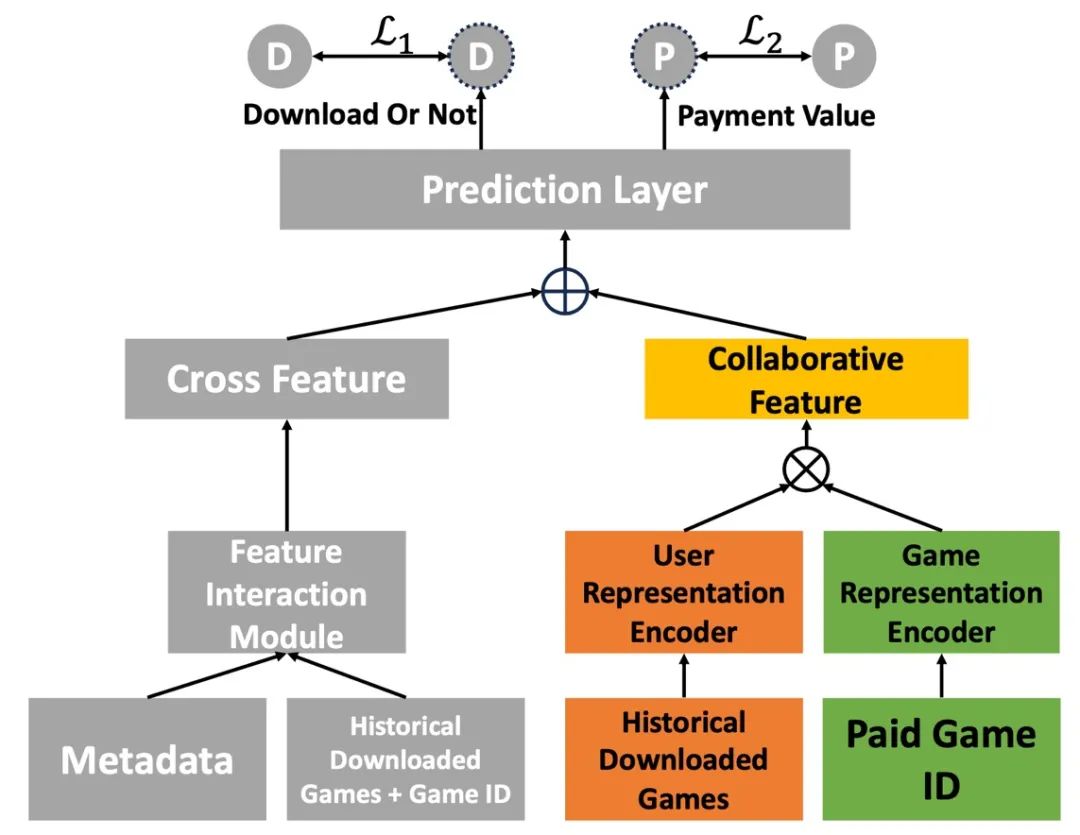
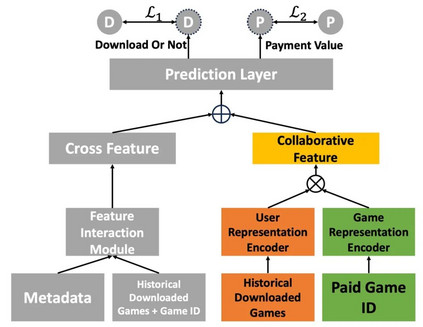
图 6 协同增强的用户消费数值预测模型
具体而言,受协同建模启发,我们认为存在具有相似交互行为的用户应该持有相似兴趣偏好,将相似兴趣偏好邻居喜欢的商品推给目标用户将会刺激目标用户付费更多。我们提出了可以建模用户游戏之间协同关系的模块,并结合现有的业务模型,赋予现有业务模型更强的协同建模能力,提出模型如图6所示,灰色部分为已有业务模型模块,彩色部分为我们提出的用于建模用户游戏之间协同信号的模块。假设每个用户只有10个历史交互游戏,输入用户的历史交互游戏列表。初始化一个历史交互游戏的表征表,其中符号表示数据集中所有的历史交互产品的个数,表示历史推广产品表征的维度大小。那么,对于游戏,其对应的表征为。首先,基于用户交互游戏历史得到用户表征,本研究工作中借助了多层感知机基于用户的历史交互游戏来提取用户的兴趣偏好表征。具体函数如下:将获取用户表征与待推荐游戏的特征执行点乘操作,得到融合特征。 接下来获取待推荐游戏的特征,例如基于预先构建的游戏特征表来获取待推荐游戏的特征。然后,基于点乘操作来获得用户表征与待推荐游戏的特征对应的融合特征:
表3不同评价指标对应的统计数值
将融合特征和业务模型已有的模型输出进行拼接后输入预测网络,得到预测网络所输出的预测消费金额。例如,假设业务模型已有输出可以表示为,那么预测网络的输入可以表示为;即,预测网络的输入是和融合特征进行拼接后得到的。预测网络的输出为,训练数据对应的标签(即训练数据中游戏的真实消费金额)为;那么,可以构建得到以下的损失函数:
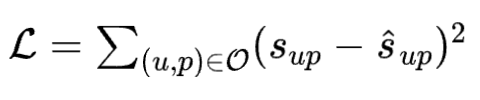
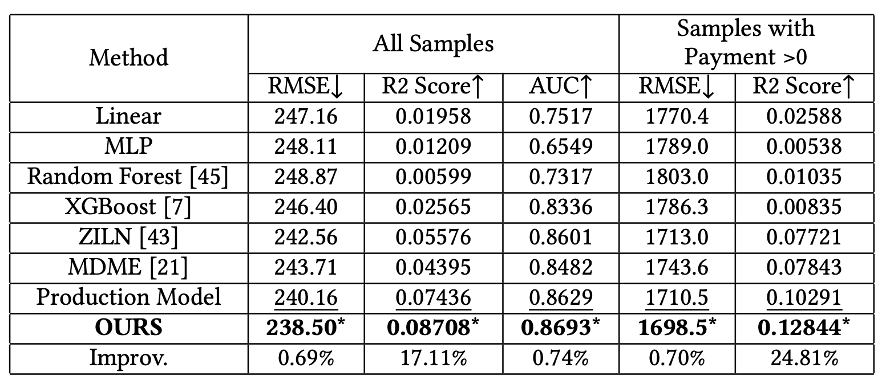
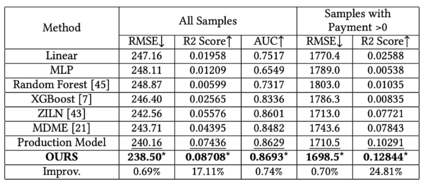
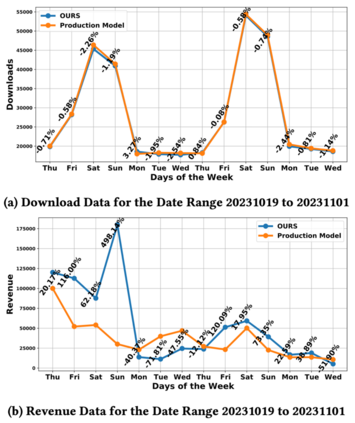
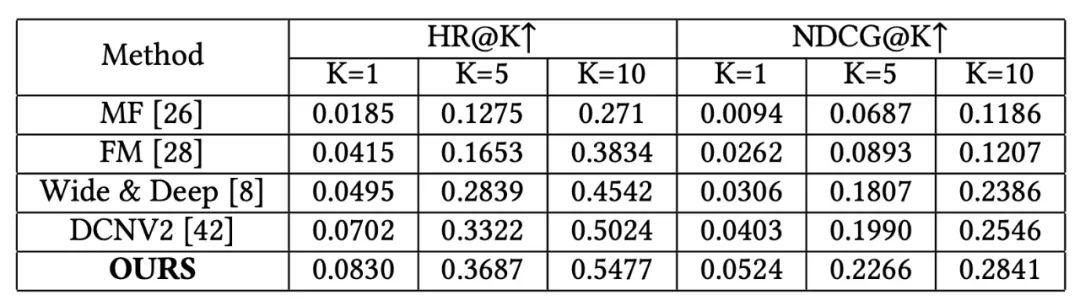
首先,我们在我们的研究框架下针对我们提出的方法的有效性进行了评估。实验结果如表3 所示。在我们的框架中,我们也采用了图 6 类似的修改方式,对 DCNV2 方法进行了协同特征增强。不过训练和测试都在我们设计的框架中开展的。然后,我们将我们提出的模型放在现有的业务框架中进行训练和评估,实验结果如表 4所示。非常幸运的看到,在业务框架中,我们提出的模型也取得了较好的表现。我们将我们提出的模型在现有的业务框架下进行训练和测试,经过多次训练和评估,可以发现我们提出的模型相对于已有业务模型可以取得显著提升,多次结果的平均结果显示我们的模型相对于一有业务模型可以取得24.81%的表现。同时,我们开展了为期两周的在线 A/B 实验,实验结果如图 7 所示,可以看到我们提出的模型相对于业务模型可以取得 50.65% 的收益提升。近期反馈的全场景应用表明,我们提出的模型相对于业务模型,取得了 18.43% 的全量提升。
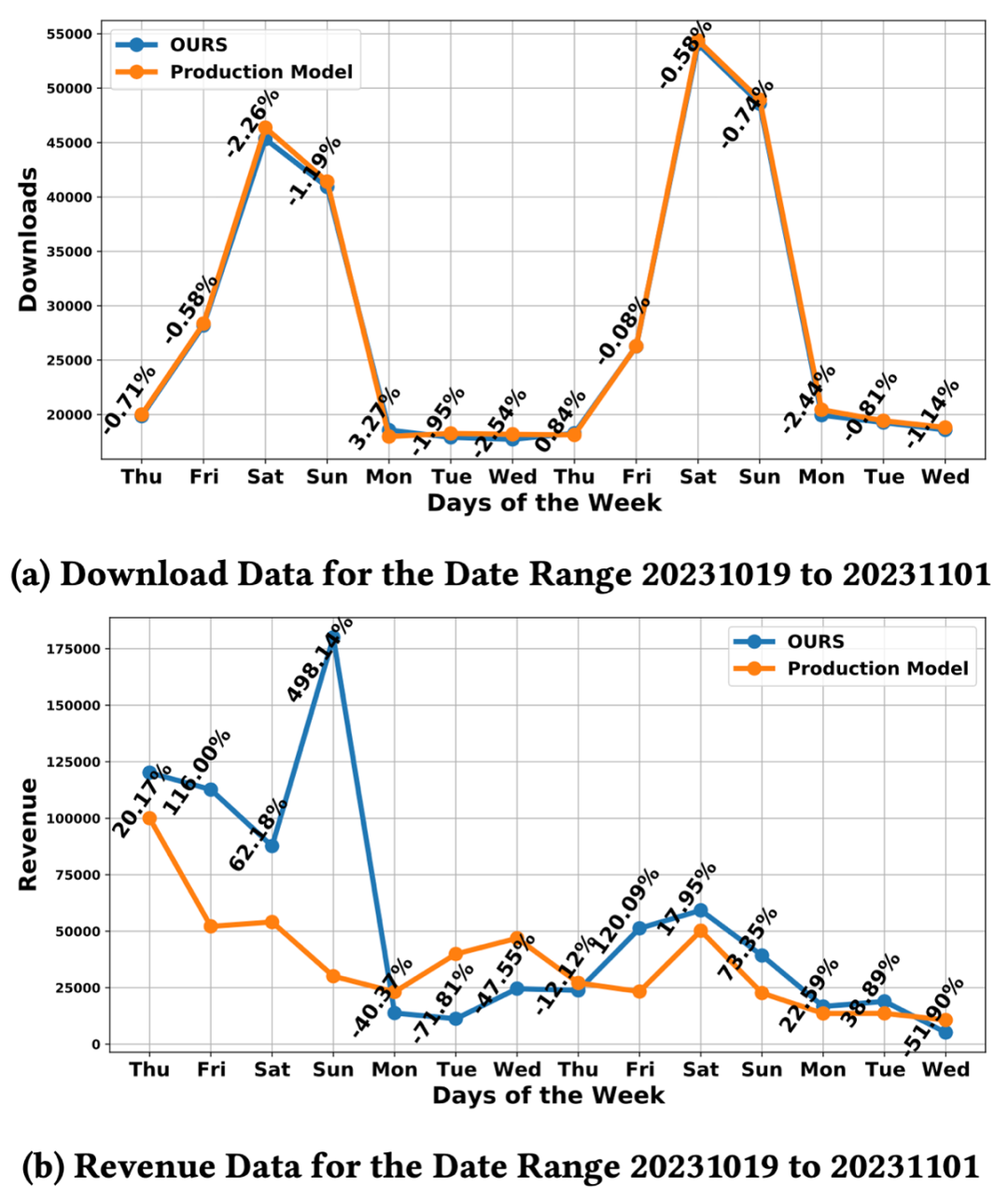
图 7 为期两周的在线 A/B实验 最后插一句。在经过线上训练和评估框架对我们提出的模型训练之前,我们也挺发怵的。正如我们所说,我们不知道什么样的模型可以在 r2_score 指标下取得更好的效果。好在最后还是比较顺利。不过这也极有可能说明我们之前的假设是正确的。能够把用户喜欢的产品找到对于提升模型在 r2_score 指标上的表现是有积极作用的。还有,我们也尝试说服业务同事将目前的评估指标替换为我们提出的排序指标,但是现有的广告及服务推广策略还是基于数值进行设定的。所以最后还是得通过 r2_score 指标这个挑战。