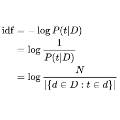成为VIP会员查看完整内容
VIP会员码认证
首页
主题
会员
服务
注册
·
登录
TF-IDF
关注
0
TF-IDF(英语:term frequency–inverse document frequency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。
综合
百科
VIP
热门
动态
论文
精华
复习 | 2017 知识点总结测验
数说工作室
0+阅读 · 2018年2月21日
Doc2vec原理解析及代码实践
AINLP
0+阅读 · 2020年4月25日
小菜鸡的算法实习面经(已拿腾讯/华为/搜狐Offer)
CVer
3+阅读 · 2019年4月26日
独家 | 一文读懂推荐系统知识体系(附学习资料)
THU数据派
8+阅读 · 2017年11月5日
文本数据如何向量化展开
凡人机器学习
1+阅读 · 2018年7月2日
我们文本分析了贾跃亭2017年全部公开信,发现他近期喜欢用“责任”“致歉”
大数据文摘
1+阅读 · 2018年1月4日
【NLP.TM】情感(观点)分析
AINLP
1+阅读 · 2020年11月20日
5000字长文告诉你,SEO每日流量如何从0到10000+
卢松松
0+阅读 · 2018年8月17日
TF-IDF与余弦相似性的应用(三):自动摘要
黑龙江大学自然语言处理实验室
1+阅读 · 2018年5月2日
【综述】关键词生成,附10页pdf论文下载
专知
9+阅读 · 2019年10月16日
数据科学家成长指南(中)
R语言中文社区
0+阅读 · 2017年8月16日
Kaggle最流行NLP方法演化史,从词袋到Transformer
机器之心
3+阅读 · 2019年11月12日
CIKM AnalytiCup 2018 冠军方案出炉,看他们构造模型的诀窍
AI科技评论
4+阅读 · 2018年11月29日
从零开始用Python写一个聊天机器人(使用NLTK)
AI研习社
10+阅读 · 2018年12月27日
R语言自然语言处理:文本分类
R语言中文社区
7+阅读 · 2019年4月27日
参考链接
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top