【NLP.TM】情感(观点)分析

【NLP.TM】
本栏目是结合我最近上的课,和我最近的研究方向,自然语言处理和文本挖掘而设计的,会讲一些和自然语言处理以及文本挖掘相关的内容,欢迎大家关注和交流!
往期回顾:
【NLP.TM】句法分析综述
【NLP.TM】NLP和TM的深度概述
情感分析,正好是我目前的主要研究方向,涉足这块并不是太长时间,所以细节不是特别清楚,只是有一些自己已经淌出来的可行的方法,不见得是最好的,最in的,但是一定是可行的,原谅我无法提供源代码,但是下面的内容我会给足文章和材料支撑,如果没提到的,大概率是百度都能百度得到,我就不赘述了~
情感分析或者观点分析,其实在技术上可以理解为广义地把多样的语言信息转化为可计算的数据信息,例如我通过算法得到一个用户对某件商品的评价是8分(满分10分),说明用户对该商品基本满意。这个算法就被称为情感分析。
本文的标题讲了就是说主要流程,所以这章是重点。
文本获取
巧妇难为无米之炊,要做分析,必须有足量的数据,数据的获取其实并不是简单的事,对大部分企业而言,是可以轻松获得文本的,例如微博、知乎等,而对部分科研机构而言,通过合作的方式也能拿到宝贵的数据,然而大部分的工作者可能并不那么轻松,所以目前文本获取最为直接的方法就是网络爬虫。关于网络爬虫,我之前写过文章简单的讲讲,欢迎了解。但是网络爬虫是一个深坑,毕竟不是每个网页都这么喜欢你去爬自己的数据的,一方面是用户的个人信息保密,另一方面是怕自己饭碗里面的饭要被别人舀走一些。

另外补充一点,爬虫获取的信息,如果使用不当,是属于侵权行为的,所以大规模商用或者用于科研的话,最好是能知会一声,尤其是商用。
我的爬虫文章点击这里进入。
文本预处理
文本预处理是进行文本处理的第一步,首先保证文本的质量足够高,众所周知质量不够高的数据分析了也没用,耗时耗力耗钱。
首先是把无效的,错误的数据去掉。这个事这么做要结合实际情况,如果是从网上趴下来的,要注意文本中有没有已经失效的页面如”page not found”,有无存在类似html之类的乱码残留,有无copyright之类的无效信息。
一昧地剔除并不是好事,因为你的数据可能其实非常少了,还删除数据那后面的分析就不靠谱了,所以有些数据还是可以通过处理使之有效的。记得我之前分析twitter的时候,遇到这样一句话,”this IPhone is so cooooooolllllll!!”,这样一句话里面,cooooooolllllll实际上就是cool的意思,我们人知道,但是电脑并非如此,我们需要对他进行处理而不是剔除或者置之不理。具体还有什么细节,这个要和自己的数据的实际情况结合来分析。关于社交网络的情感分析,可以参考[1].
文本量化
要进行分析和计算,首先是要将文本转化为可以计算的数字。目前的方法是非常非常多,有简单的仅仅基于概率的,如后面会提到的TF-IDF的,也有比较高级的基于深度学习的,例如word2vec方法,不过,无论如何,都离不开一个关键,把文本变为数字的关键——概率,单词在一篇文章出现的概率,出现该单词的文章占所有文章的概率,单词在所有文章中出现的概率等,都是对文本进行量化的重要指标。
深度学习很火,但是我是一个不是万不得已不用深度学习的深度学习黑,所以这里不详细介绍深度学习方法,这里只简单介绍一下上面提到的TF-IDF方法,看好,简单介绍= =,别骂我,你看到这里能去主动百度的都是好样的!

TF-IDF:
这是一个比较简单,而且已经得到非常广泛运用的文本表示方法,运用词向量去表示一篇文章,从而将文章抽象成向量,用于进行下一步计算,这也是Bag of words(BOW)的思想,TF-IDF只是BOW下一个比较优秀而且简单的方法。下面我开始上公式了哈,做好心理准备。
(文字描述中,符号后的括号中的词表示下标)
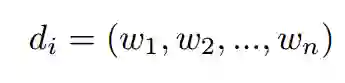
设一篇文章可以用d(i)表示,i表示第i篇文章,d(i)可以用一个向量表示。每个w(i)表示的是第i个单词,在这篇文章d(i)的一个权值。这就是BOW模型,BOW下不同的模型,其实就是改变这个权值的计算方法,每篇文章的向量都相同,所以可见是一个非常稀疏的向量。
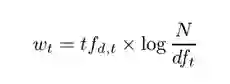
这个就是权值的计算公式,w(t)表示的是文章d中的第t个单词对应的权值,tf(d,t)表示在文章d中,第t个单词出现的频率,log是对数函数,取啥的都有,2,e,10都有,自己开心就行,N表示文章的总数,df(t)表示在所有文章中出现第t个单词的文章的概率。
具体原因,为什么这样?我给文献,有兴趣的自己去看好吧。当然的你也可能认为这个东西太简单,你可以用下面几个TF-IDF的升级方法,自己开心就好。
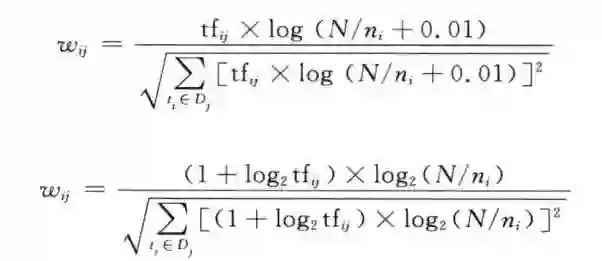
说说实现吧,我用的是python的sklearn包,详细阅读,百度就有的东西,这里不赘述了。
文本分析(分类)
文本分析,主要针对情感分析(当然还有别的),是文本分析中最为常见的内容,由于数据本身的原因,目前采用的主要是分类的方法,逼格说的高一点,就是监督学习,机器学习的一部分,说得简单点,就是分类。(不太懂机器学习的可以尝试看看下面的,觉得看不下去了最好先简单百度一下基本的概念)
分类在什么情况能用呢?首先,得有文本向量,上面文本量化是能够拿到的,然后是需要监督学习里面最宝贵的一块,那就是标签,一篇文章,具体的核心信息是什么。还是拿用户评价来作为例子,用户对一个商品,好评,那就记为1,否则记为0,那么用户的那条评论文本的向量的标签就是1,有了很多这样的数据,就能够实现文本分类了,训练得到文本分类器,当有一个新的文本,可能是微博,或者还是评论,就能通过分类器,得到该文本的好坏评价。

分类器,就是能把样本分成几类的划分方法,只需要求出分类器的具体参数,就能够得到分类器,可用作分类器的模型主要有支持向量机,决策树,朴素贝叶斯(都说朴素贝叶斯很好,但是我的实验看来并不好),然后还有一些提升方法,bagging,boosting等,当然的有足够的样本规模,那深度学习的方法也是可以用的(有点杀鸡用牛刀吧),具体这几个方法,已经有非常成熟的包了,python里面有sklearn实现浅层的机器学习,至于深度学习,不用多说,大家应该也知道很多。
分类得到的需要经过检验,常用查准率,查全率,F1,AUC,ROC之类的指标进行评判。
文本分析(打标签然后再用分类)
这里就推荐一篇文章,被引量还行,用的是基于时间序列的方法,发现趋势,然后把当日的趋势用于匹配新闻,打标签为“看涨新闻”,“看跌新闻”,“看平稳新闻”三种,涉及的内容是线性回归、t检验、k-means的方法。
文本分析(无监督和半监督)
像上述情况,有标签的情况并不多,上面讲到了打标签的方法,但是可靠度有限,而且再进行分类,会导致误差叠加,大部分情况拿到的都是无监督的数据,打标签比较难,那就只能考虑用无监督和半监督的方法实现。无监督是指一个有标签的数据都没有,在这种情况下进行分析,这种方式的优点就是不用带标签就能实现,缺点是,聚类是定向的,他不见得是按照情感好坏来聚类,说不定他是按照说话是男性还是女性来聚类,或者你甚至不知道标准的聚类,这个很危险。
为了表面这种无头苍蝇式的聚类,有两个解决方案,一个是调整聚类的属性,这个在情感分类中非常难,因为很多词不好界定,另一个就是造或者找一些带标签的数据辅助,后者相比前者比较考虑,这里到了我后面需要看的地方,目前我是空白的,关于半监督学习,我需要进一步学习,有想法的欢迎交流。
文本分析(连续型方法)
上面的分类,只能实现“好”和“坏”的区分,但是不能解决“有多好”和“有多坏”的问题,例如我看了两个文本,A是0.8,B是0.7,那我可以认为A比B的观点更为乐观。
这块我看的材料同样比较少,但是存在这些技术,后面需要进一步看,也希望大家能够指出。
暂时说到这,一个是篇幅原因,一个是时间原因,还有一个是现在网上已经有很多人把这个写成论文、发成博客、开源代码、构建程序包了,不需要我重复,大家可以根据我给的思路继续去找一些材料自己拓展,靠一篇文章就能学会情感分析,太太天真,大家都懂,我只希望,大家看了我的文章,能有一个基本的思路,然后跟着这个思路能找到更多的材料进一步学习,无论是理论,还是技术,都是能找得到材料,能找得到资源的。自己要多动手,多思考,多百度。
另外,情感分析目前还没有形成专门的,很成体系的研究框架和思路,很多东西都比较新,踏足这块的大部分是拓荒者,而且很多内容都是从扣了“自然语言处理”的帽子下有的,所以资料找起来是真的难Orz。
从理论到技术,我下面都提供了一些我认为还不错的资源,大家可以参考一下。
[1] 主讲社交网络的,被引不多,但是感觉把社交网络的情感分析基本方法论说的比较清楚,思路可以借鉴,细节方法可以和零件一样替换,另外文献综述也可以仔细阅读一下,看看有没有相关内容可以进一步阅读。Vu T T, Chang S, Ha Q T, et al. An Experiment in Integrating Sentiment Features for Tech Stock Prediction in Twitter[C]. The Workshop on Information Extraction & Entity Analytics on Social Media Data. 2012:23-38.
[2] 最近看的标杆文献,比较厉害的是提出了一个给无标签文本打标签的方法(基于时间序列),用了TF-IDF方法,具体怎么用可以看看这篇论文,而且我作文本分析的思路就是从这篇文章借鉴的。Fung G P C, Yu J X, Lam W. News Sensitive Stock Trend Prediction[C]. Pacific-Asia Conference on Advances in Knowledge Discovery and Data Mining. Springer-Verlag, 2002:481-493.
[3] 金融领域关于文本挖掘的一篇综述,额,被引量不高,不过从总数看来,这块的应用缺口多少有一点点。Kumar B S, Ravi V. A survey of the applications of text mining in financial domain[J]. Knowledge-Based Systems, 2016, 114:128-147.
[4] 再来一篇综述,关于这方面的应用,这两篇综述看完已经知道怎么回事,然后可以开始看做什么事情了。Khadjeh N A, Aghabozorgi S, Wah T Y, et al. Text mining for market prediction: A systematic review[J]. Expert Systems with Applications, 2014, 41(16):7653-7670.
[5] 中文方面,比较好的一本书,非常推荐,这本书写的和文献综述类似,可以以这本书为线索去看更多的材料,今天的内容主要参考的第13章。宗成庆. 统计自然语言处理[M]. 清华大学出版社, 2008.
[6] 这是一本将技术的书,不过没什么代码,主要讲怎么去进行web数据挖掘,里面讲了如何分析网上的内容,观点分析这章写的非常不多,内容很充实,也很系统。刘兵. Web数据挖掘[M]. 清华大学出版社, 2013.
[7] 目前看来写的最好的一本自然语言处理的书了,动物园系列,颇推荐,主要走NLTK的路线。StevenBird, EwanKlein, EdwardLoper,等. Python自然语言处理[M]. 人民邮电出版社, 2014.
[8] 强大的python机器学习sklearn中同样提供了比较好的情感分析功能,TF-IDF,分类,回归等,都能做。http://scikit-learn.org/stable/index.html
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏





