CIKM AnalytiCup 2018 冠军方案出炉,看他们构造模型的诀窍

AI 科技评论按:CIKM AnalytiCup 2018(阿里小蜜机器人跨语言短文本匹配算法竞赛)近日落幕,由微软罗志鹏、微软孙浩,北京大学黄坚强,华中科技大学刘志豪组成的 DeepSmart 团队在一千多名参赛选手中突出重围,一举夺冠。

本次算法竞赛以聊天机器人中最常见的文本匹配算法为目标,通过语言适应技术构建跨语言的短文本匹配模型。在本次竞赛中,源语言为英语,目标语言为西班牙语。参赛选手可以根据主办方提供的数据,设计模型结构判断两个问句语义是否相同。最终,比赛主办方将在目标语言上测试模型的性能。在这次比赛中,主办方对外部资源进行了严格限制。训练数据集包含两种语言,主办方提供 20000 个标注好的英语问句对作为源数据,同时提供 1400 个标注好的西班牙语问句对,以及 55669 个未标注的西班牙语问句。所有的标注结果都由语言和领域专家人工标注。与此同时,也提供每种语言的翻译结果。
规则描述
主办方希望参赛选手关注在短文本匹配和语言适应的问题上,所有的参赛选手都需要注意以下限制:
1)模型训练中只能使用主办方提供的数据,包括有标注语料、无标注语料、翻译结果、词向量等。不得使用其它数据或预训练模型。
2)如果需要预训练词向量,只能使用 fastText 预训练的词向量模型。
3)如果需要使用翻译模型或翻译语料,只能使用主办方提供的翻译结果。
4)理论上选手们可以用主办方提供的平行语料训练出一个翻译模型,此类方法不禁止,但不推荐。
DeepSmart 团队成员介绍:
罗志鹏(getmax): 微软 Bing 搜索广告算法工程师,北京大学软件工程专业硕士,专注于深度学习技术在 NLP, 广告相关性匹配,CTR 预估等方面的研究及应用。
黄坚强 (Jack Strong) : 北京大学软件工程专业硕士在读,擅长特征工程、自然语言处理、深度学习。
孙浩(fastdeep): 微软 Bing 搜索广告部门首席开发工程师,专注于机器学习与深度学习在搜索广告和推荐算法领域的创新和应用,致力于通过提高在线广告匹配算法、相关性模型和点击率预估模型等来推动广告收入增长。
刘志豪 (LZH0115) : 华中科技大学自动化学院控制科学与工程硕士在读,主要研究方向图像识别、zero-shot learning、深度学习。

左一:微软 Bing 搜索广告部门首席开发工程师孙浩;左二:微软 Bing 搜索广告算法工程师罗志鹏
团队成员曾经获奖记录:
NeurIPS 2018 AutoML(Phase 1)
1st place
KDD Cup 2018(Second 24-Hour Prediction Track)
1st place
KDD Cup 2018(Last 10-Day Prediction Track)
1st place
Weibo Heat Prediction
1st place
Shanghai BOT Big Data Application Competition
1st place
Daguan text Classification
1st place
以下为 DeepSmart 团队成员罗志鹏的夺冠心得和详细方案解读:
1. 你们团队共有四名成员,大家是通过何种渠道认识的?大家的研究背景以及在比赛中的分工如何?各自擅长的工作是什么?
比赛刚开始我们队伍有三人,包括我,黄坚强和孙浩(Allen),其中黄坚强是我的直系师弟,孙浩是我在微软的 tech lead,是广告匹配和推荐方面的专家。在比赛即将进入第二阶段时,我在比赛交流群看到刘志豪想找队伍合并,当时觉得和我们的模型有些互补,就组成了 4 人战队。由于坚强和志豪是在校硕士研究生,相对业余时间较多,他们在数据处理和特征工程上花了不少时间;我和 Allen 主要设计特征和模型结构,坚强和志豪也有参与。
我个人比较擅长设计和实现深度学习模型,在特征工程和模型融合上也有丰富的经验;Allen 身为广告推荐领域的老兵,对主流匹配算法如数家珍,对数据有深入透彻的理解,他基于工业界的实际经验对算法的弱点提出了多种改进方案,帮助我们避免了一些数据陷阱;坚强和志豪比较擅长设计特征,对数据有敏锐的直觉,能快速实现特征并得到效果反馈以加快模型迭代。
整体而言,我们队伍的成员有各自擅长的领域,大家优势互补,在比赛过程中充分沟通、通力合作,最终让我们在众多竞争对手中脱颖而出。
2. 你们最终取得了第一名,这个最终成绩是根据什么而定的呢?
最终成绩由 5 项指标计算而来,阶段一线上成绩占比 20%,阶段二线上成绩占比 30%,创新性、系统性占比 20%,数据理解占比 10%,实用性占比 20%。
阶段一成绩:初赛线上成绩。
阶段二成绩:复赛线上成绩。
创新性、系统性:设计思路新颖,从数据预处理到模型结果本地验证的整体设计独特;合理使用开源库,充分发挥开源模型的作用,不盲目拷贝;算法模型设计思路清晰,详细论述模型设计的优势,符合赛题数据应用特点;算法模式架构特征明显,阐明了作品中设计相关特征的目的,及其对于预测目标的优势;算法模型结果验证策略合理,能够证明最优的结果是经过仔细比对后得出,而非运气导致。
数据理解:充分理解数据样本的字段含义,清晰阐明数据预处理方法。
实用性:参赛作品的算法模型设计,对于真实业务具有实用性或启发。
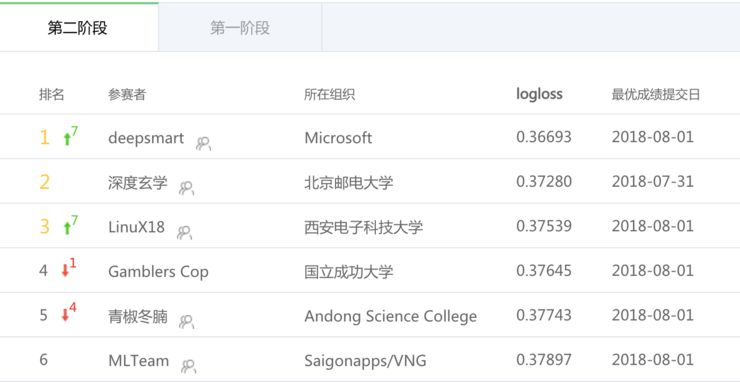
图:阶段二成绩排名
3. 阿里对参赛规则进行了严格限制,如模型训练时只能使用他们提供的数据,只能使用 fastText 预训练的词向量模型,如果需要使用翻译模型或翻译语料,只能使用他们提供的翻译结果,这会不同于你们以往的比赛吗?是否会带来一些新的挑战?
这些限制能使得这次比赛更公平,大家使用相同的资源来进行效果比拼,尽管能使用一些外部资源是可以帮助提升效果的,但其实和以往的比赛的差别并不是很大,而且还能让我们的精力集中在官方提供的数据上。
4. 团队成员中是否有人懂西班牙语?如果懂西班牙语,会不会在比赛中占据一些优势?
没有。如果懂西班牙语也许能针对语言做一些数据处理或者特征提取来提升模型效果,具体是否有效需要实验去验证。
5. 这次比赛的难点集中在哪些方面?
严格限制使用外部资源。
提供的训练数据少,local 验证不稳定。
如何有效的使用英文数据。
6. 能具体讲讲你们在数据预处理、特征工程、验证、模型选择、模型融合上的思路?
数据预处理、特征工程
我们通过 LightGBM 模型来验证特征效果,对文本做不同的预处理后进行特征工程。经验证,不同的文本预处理后形成的特征进行混合非常有利于单个模型的泛化能力的提升。我们将两个问题称为 q1 与 q2,接下来列举用到的特征,并说明不同预处理方式所使用的特征。
使用的特征如下:
文本距离特征。文本距离能较简单地判断出不相似的文本,相似的文本往往字符数及单词数较为接近,会带有相同或相似的单词,并且编辑距离会较短。同时,使用了 tf-idf 后关键词的权重会高,使用它来代替 count 提取特征更有效。以下为使用的文本距离特征:
字符距离:q1 与 q2 字符数的差值绝对值,比例。
单词距离:相同单词 tf-idf 权重和占所有单词 tf-idf 权重和的比例,q1 与 q2 相同单词数占所有单词数的比例,q1 与 q2 单词的 jaccard 距离,q1 与 q2 单词的交集数,并集数,单词数的差值等。
字符 fuzzywuzzy 距离:使用 fuzzywuzzy 计算字符的编辑距离等。
单词 fuzzywuzzy 距离:使用 fuzzywuzzy 计算单词的编辑距离等。
词向量特征。共使用了三种词向量:官方提供的词向量,利用官方提供的训练数据、预测数据、无标签数据训练的词向量,以及去除停用词后训练的词向量。虽然训练集及测试集数据量小,但是使用它们训练得出的词向量更能体现出该数据的特性。由于两个问题的单词长度并不相等,并且相似句子的词序差异很大,要使用词向量计算问题相似性,需要将词向量转换为句向量,我们对问题的词向量进行了两种处理得到了与词向量相同维度的句向量,分别是所有单词的词向量取均值,所有单词的词向量和除以单词词向量的 2 范数,使用这两种句向量来计算相似度能从词向量的角度来计算出两个问题的相似性。我们使用词向量构建了以下特征:
q1 词向量均值与 q2 词向量均值的相似度,相似度计算包括 cosine, cityblock,canberra, euclidean, minkowski, braycurtis,这些不同的距离能从不同角度来度量相似度。
q1 词向量和除以 q1 词向量 2 范数与 q2 词向量和除以 q2 词向量 2 范数的相似度,相似度计算包括 cosine, cityblock,, canberra, euclidean, minkowski, braycurtis。
使用词向量计算问题的 Word Mover's Distance。
根据两个问题的单词的 tf-idf 值提取两个问题的关键词,对关键词的词向量计算余弦相似度。两个问题会由于最关键的单词不相似从而导致句子不相似,所以通过 tf-idf 先计算出问题的关键词,然后再计算关键词词向量的相似度。
主题模型特征。主题模型是常用的文本相似度计算模型,使用主题模型来提取文本相似度特征加入我们的模型对模型的泛化能力有很大的提升。我们采用 LSI 和 LDA 模型来将句子映射到低维度的主题向量空间,由于主题向量维度低,可以直接使用主题向量特征而且不容易导致模型的过拟合,同时可以根据两个问题的主题向量来得出相似性特征,主题向量的计算能直接体现出两个问题的主题是否相似,以下为使用到的主题模型特征:
q1,q2 主题数为 3,5,7,9 的 LSI、LDA 主题向量
q1,q2 主题向量差值的绝对值
q1,q2 主题向量的相似度
预处理方式如下:
原文本:使用特征 1,2,3,4,两个问题文本距离相差大的样本更倾向于不相似。
去标点符号+字母转小写:使用特征 1,2,3,4,5,6,7,8,9,10,11,有无标点符号基本不会改变短文本的语义,大小写字母对语义也不会有影响,所以去标点符号及转换为小写后提取的特征更为有效。
去标点符号+字母转小写+单词 2 元组:使用特征 2,4,9,10,11,n 元模型是自然语言处理的常用模型,使用单词 n 元组来提取特征,给模型增加了单词间的词序信息。
去标点符号+字母转小写+去停用词:使用特征 1,2,3,4,5,6,7,8,9,10,11,停用词往往没有实际含义,去掉停用词再提取特征给模型增强了非停用词的信息。
去标点符号+字母转小写+去停用词+单词 2 元组:使用特征 2,4,11
去标点符号+字母转小写+去问题交集词:使用特征 1,3,4,5,6,7,8,9,10,11,去掉问题交集词后提取特征能给模型增强非交集词的信息。
无标签数据的利用:
无标签数据中包含西班牙语到英文的翻译,且比赛规则说明了不能使用翻译接口,因此最初我们训练了一个翻译模型,但是由于训练数据太少,导致模型严重过拟合,最后我们放弃使用翻译模型。
经过数据分析发现无标签数据集中包含部分测试集的英文翻译,所以我们采用纯规则在无标签数据中对测试集西班牙语的英文翻译进行了提取,从而我们可以训练英文模型并且对部分测试集进行预测。实验中发现当我们使用弱匹配时虽然能匹配到更多的英文对,但是线上效果却不好,经过分析发现弱匹配会有映射错误,而一旦映射错误就很容易被预测成一个接近 0 的概率值,如果这样,原来这个样本的 label 是 1 的话,loss 就会变得很大,因此我们匹配时尽量做到精确匹配,尽管这样匹配的样本不多。
根据我们的较精确的匹配方法,在 A 榜测试集中,我们可以从 5000 个测试集中提取出 2888 个,在 B 榜测试集中,我们可以从 10000 个测试集中提取出 4334 个。在 A 榜中,使用英文训练的模型来预测这 2888 个测试集,经验证,使用西班牙语模型与英语模型融合在 A 榜评分上能提升 0.003~0.004,由于 B 榜匹配上的样本占比更少,效果提升可能会有所减少。
从实验中我们验证了英文模型的有效性,如果使用英文翻译接口肯定能够得到更好的效果,此外也可以使用多种语言进行翻译来做数据增强。
验证
我们采用了以下两种验证方式。
Holdout validation:
由于测试集都为原生的西班牙语,而给予的训练集分为两类,一类是 20000 对从英语翻译过来的西班牙语,一类是 1400 对从西班牙语翻译过来的英语。显然,1400 对西班牙语更适合用于做验证,由于验证集和线上测试正负比例不一致,所以我们复制 1400 对西班牙语样本并调整了正负样本的比重,最终得到 34061 对验证集,同时我们对模型的随机数种子进行多次更换,取多个模型对验证集预测的平均值来得到最终的验证集评分。经过与 A 榜得分的对照,对该验证集预测评分的提升与 A 榜分数的提升保持了较好的一致性。
k-fold validation:
由于数据集较小,只采用一种验证方式并不能保证模型的泛化能力,所以我们也对 21400 对训练集采用了十折交叉验证。在每一折,我们留出一个部分作为验证集,一个部分作为测试集,并且将其余部分作为训练集。同时考虑到单一的数据划分,可能划分后的数据分布与测试集的数据分布差异更大,使得线下验证的结果可能与线上不一致,因此,我们设定不同的随机种子来产生多种划分。通过这种方式来调节模型的超参数以获得更好的线下线上一致性。当大致确定了模型的超参数之后,我们再使用一般的交叉验证方式来训练模型,以使得每折有更多的训练数据。
模型选择、模型融合
在模型的选择上,我们主要考虑使用深度神经网络模型,主要包括 3 种网络结构。在实验中我们测试了多种词嵌入的形式,我们使用了给定的 300 维的词向量,并且通过给定的语料训练了 128 维的词向量。通过实验我们发现使用给定语料训练出来的词向量能够实现更低的 logloss,这可能是因为给定语料训练的词向量对问题本身根据有针对性,能够学习到针对该任务更好的表示;此外我们还测试过 tri-letter 和字符卷积,因实验效果不好最后未使用。
模型一:M-CNN
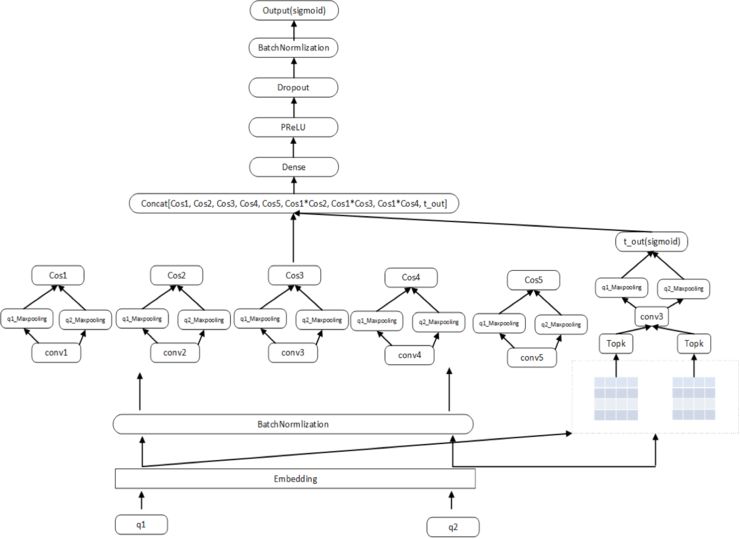
该模型是由我们自主创新的一个语义匹配模型。首先使用 Embedding 对 q1,q2 进行编码提取每个 word 的语义特征,然后再经过 BN 对 word 的语义特征进行标准化,然后我们使用不同尺寸的 filter 建立卷积层,每一种 filter 用来提取一种局部语义特征,filter 越大局部语义跨度越大。这里我们使用 conv1-conv5 和 maxpooling 后得到 5 种不同的句子语义特征向量,再用 q1 和 q2 对应的局部语义特征向量计算余弦相似度,可以得到 5 个余弦相似度,我们也添加了交叉相似特征,包括 Cos1*Cos2, Cos1*Cos3, Cos1*Cos4, 然后 concat 连接起来形成新的表示层,最后再经过 Dense,PRelu, Dropout, BN,output 得到最后的匹配结果。此外我们进行了进一步优化,我们用 Embedding 后的 q1,q2 计算余弦相似矩阵,这里每个 word 的向量由该 word 与另一端的所有 word 余弦相似性组成,然后我们保留了 top10 的相似性作为该 word 的语义表达,然后经过卷积、maxpooling、dense 得到另一种匹配度,最后加入到 Cos 的 concat 中。由于 q1 和 q2 的顺序无关,所以这里的 Embedding,BatchNormlization 和所有的 convolution 层都是共享的。
模型二:Decomposable Attention
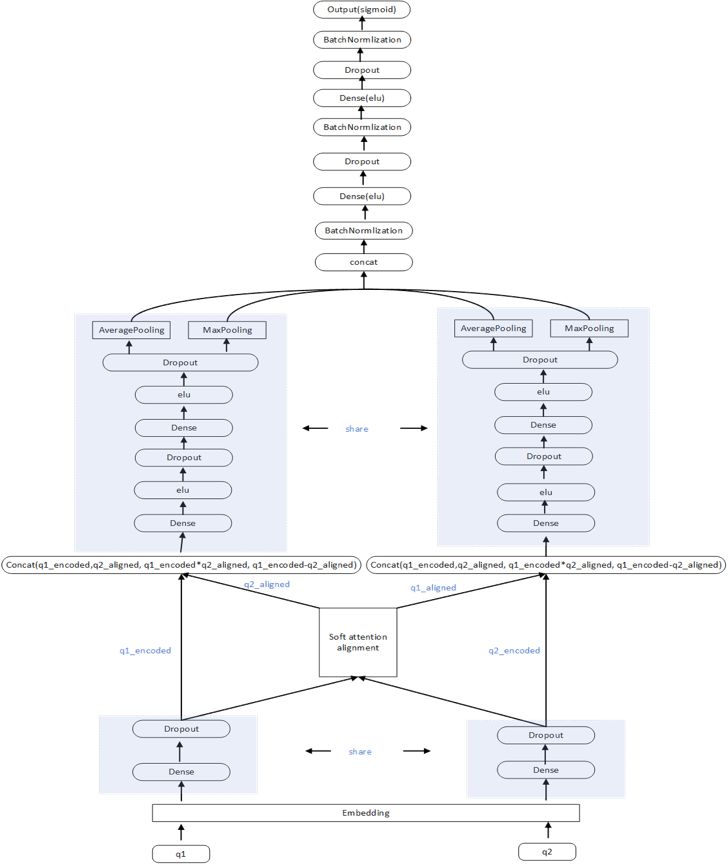
该模型的核心是 alignment, 即词与词之间的对应关系,alignment 用在了两个地方,一个是 attend 部分,是用来计算两个句子之间的 attention 关系,另一个是 compare 部分,对两个句子之间的词进行比较,每次的处理都是以词为单位,最后用前馈神经网络去做预测,它并没有使用到词在句子中的时序关系,但是它参数量少且运行速度较块,在实验中也取得了不错的效果。
模型三:ESIM
相对于 Decomposable Attention 模型来说,ESIM 在 Embedding 之后添加了 BatchNormlization 层,并把 project 层和 compare 层都从原来的 Dense 换成了 BiLSTM。这里的局部推理(Local Inference Modeling)也是一个 attention 过程,只是它是在 LSTM 输出序列上计算得到的。同样 Pooling 层也是在 LSTM 的每个时间步上进行 pooling 的,ESIM 模型有了很强的时序关系,在时序比较敏感的任务中一般能够取得很好的效果,在此次竞赛中 ESIM 也表现的很好。
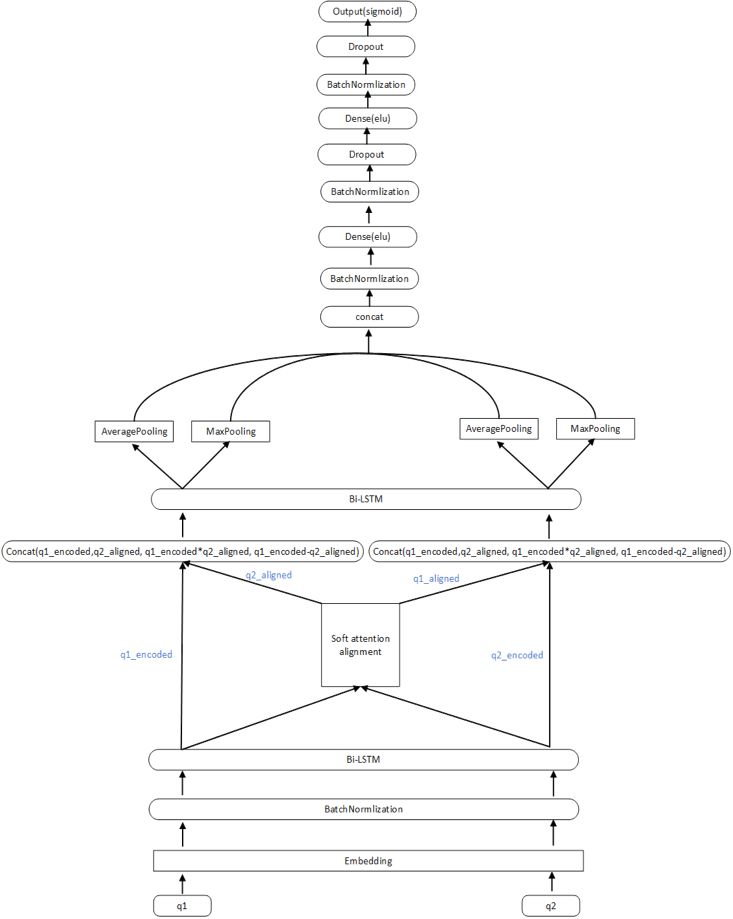
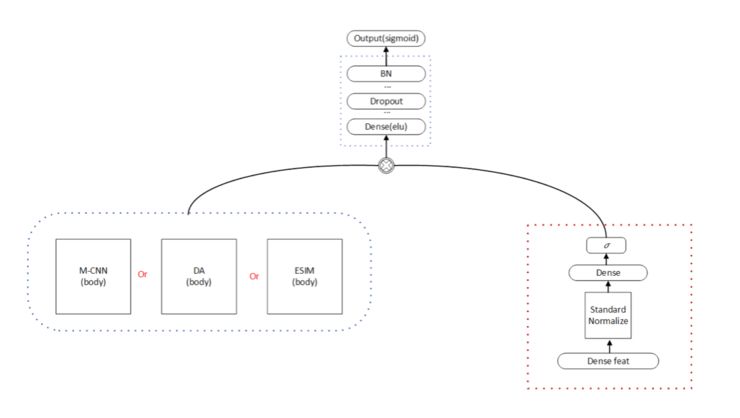
使用 dense feature 作为 gate 的模型优化:
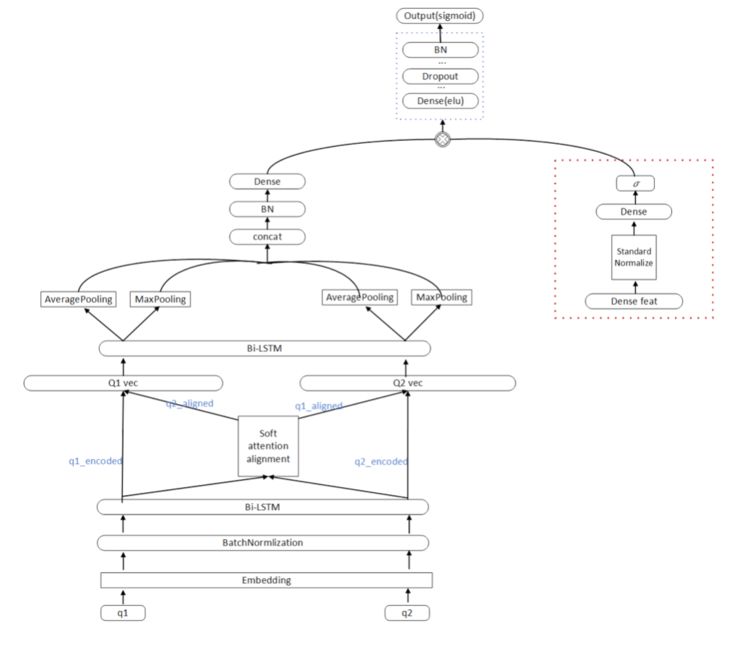
我们在 LightGBM 中使用了文本字距离、tf-idf、词向量相似度、LDA、LSI 等特征,同时我们把这些特征嵌入到了深度学习模型中,这部分特征我们称做 dense feature。在实验中发现把 dense feature 和 nn 模型某一层直接 concat 的效果并不好,我们参考了 product neural network 概念以及 LSTM 中的 Gate 设计,我们把 dense feature 做为 gate 来使用,使用中我们把 dense feature 经过全连接层得到和子模型维度一样的表示向量,然后加上 sigmoid 激活函数,再进行 element-wise-multiplication,这样 dense feature 就可以控制子模型的信息流通,通过实验发现这样的结构在每个子模型上都得到的很大的提升。优化后的模型结构如下:
Gate-ESIM:
这次比赛我们在模型融合上做的比较简单,最终结果融合了 4 种模型,包括 Gate-M-CNN, Gate-DA, Gate-ESIM 和 LightGBM,对于这 4 种模型我们训练了英文版本和西班牙语版本,首先按照两种语言分别加权融合,然后再融合两种语言的结果。
7. 你们在榜单上领先第二名很多,这次比赛能得到冠军的决定性因素有哪些?
提出了一种用 dense feature 做 gate 的网络结构。
设计了一种基于 CNN 的多种局部相似度的网络结构。
使用 2 种本地验证方式,让效果提升更稳定。
从无标签数据中匹配英文,进行两种语言的模型融合。
使用 2 个版本的 dense feature 构造差异化的 gate, 增加模型差异性。
基于官方数据训练了 fasttext 词向量,由于词向量处于网络的第一层,并且占用了大量参数,使用不同的词向量训练的模型具有很大的差异性。
融合 LighGBM 和 DNN 模型。
构造了几种差异化的模型结构,提升了融合效果,增加了结果稳定性。
使用不同的预处理方法构造特征,加强了特征表达。
多种句向量距离度量方法,包括词向量均值距离,Word Mover's Distance 及 TF-IDF 与词向量的结合。
使用 LDA,LSI, fuzzywuzzy 等增加特征多样性。
8. 你们已经参加了很多数据挖掘类比赛,如今年的 KDD Cup,NeurIPS 2018 AutoML, 这些赛事有哪些共性?你们挑选赛事的标准是什么?
这些都是顶级学术会议举办的比赛,比赛质量高,影响力大,有许多经验丰富且实力很强的竞争对手。
参加比赛主要是我们的个人兴趣,我们参加过许多不同类型的比赛,大多都是使用的工业应用数据。在比赛中,我们有机会去真正解决这些工业应用问题,这让我们颇有成就感,因此我们并没有什么严格的挑选赛事标准,能从比赛中学到东西并解决工业应用问题就是我们的选择标准。
9. 对于经常参加机器学习类比赛的同学,有什么好的建议和经验分享?如何才能做到像你们这样的成绩?
经常参加机器学习类竞赛的同学通常是对机器学习竞赛感兴趣的同学,有的在校,有的在职,通常在校学生比较多,在职的相对要少一些。
对于在校的同学来说,参加机器学习竞赛可以快速提升自己的专业技能,也能积累实战经验,对找实习和找工作都有很大帮助;对于在职的同学来说,希望在业余竞赛的同时能把竞赛中学习到的东西应用到当前工作中来,由于竞赛需要花费不少时间,也建议队伍中有时间相对比较多的在校学生;也希望参赛经验丰富的同学能多多分享,带带新人。
其实网上已经有挺多经验分享了,我们的分享很简单:多看看优胜队伍的分享和相关任务的 paper,多思考,对于特定任务可以结合实际业务场景深入探索。
在机器学习竞赛中取得 top 的成绩不仅要实力也需要一定的运气,放松心态,带着学习的态度去玩比赛,在玩的过程中,能提升自己的能力,认识更多相同兴趣的朋友,这就是最大的收获。
文末福利大放送
科技界一年一度的案例研究峰会 TOP100summit 将于本周在京开幕,TOP100summit 会在每年甄选有学习价值的 100 个技术创新/研发管理实践,分享他们在本年度最值得的总结、盘点的实践启示。
会议地址:北京市朝阳区国家会议中心
会议时间:11.30-12.03
会议地点:北京国家会议中心
会议官网:http://www.top100summit.com/
峰会首日,你将看到如下分享:
陈伟:搜狗语音交互技术中心语音首席科学家,《智能语音的深度思考》
Guang Yang:Yelp group product dirwctor,《工程师文化落地指南》
段亦涛:网易有道首席科学家,《人工智能在翻译、学习等场景的落地应用……》
AI 科技评论为大家提供了 2 张价值 1000 元的首日体验票 + 3 张价值 3600 的全程体验票,欢迎大家点击如下地址填写麦课表格,领取赠票资格:
http://ailearning.mikecrm.com/0RtRhHC
AI 科技评论将从中抽取 5 位幸运读者~

点击阅读原文,了解阿里其他相关竞赛