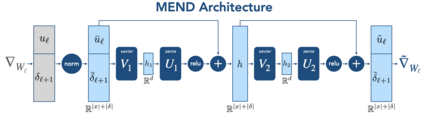
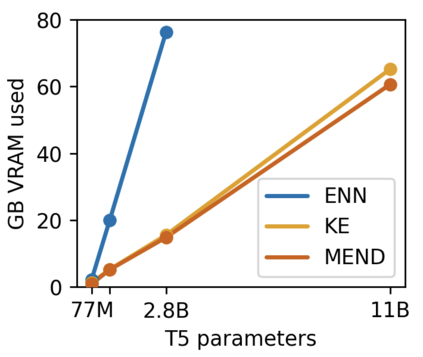
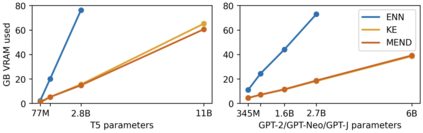
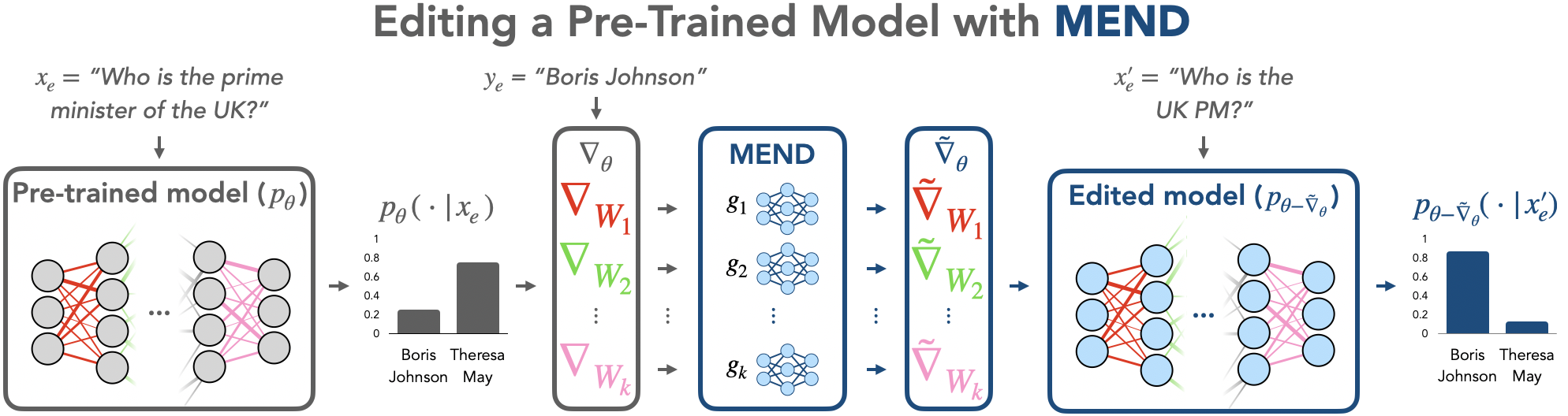
While large pre-trained models have enabled impressive results on a variety of downstream tasks, the largest existing models still make errors, and even accurate predictions may become outdated over time. Because detecting all such failures at training time is impossible, enabling both developers and end users of such models to correct inaccurate outputs while leaving the model otherwise intact is desirable. However, the distributed, black-box nature of the representations learned by large neural networks makes producing such targeted edits difficult. If presented with only a single problematic input and new desired output, fine-tuning approaches tend to overfit; other editing algorithms are either computationally infeasible or simply ineffective when applied to very large models. To enable easy post-hoc editing at scale, we propose Model Editor Networks with Gradient Decomposition (MEND), a collection of small auxiliary editing networks that use a single desired input-output pair to make fast, local edits to a pre-trained model. MEND learns to transform the gradient obtained by standard fine-tuning, using a low-rank decomposition of the gradient to make the parameterization of this transformation tractable. MEND can be trained on a single GPU in less than a day even for 10 billion+ parameter models; once trained MEND enables rapid application of new edits to the pre-trained model. Our experiments with T5, GPT, BERT, and BART models show that MEND is the only approach to model editing that produces effective edits for models with tens of millions to over 10 billion parameters. Implementation available at https://sites.google.com/view/mend-editing.
翻译:尽管经过事先培训的大型模型使得在各种下游任务上取得了令人印象深刻的结果,但最大的现有模型仍然会出错,甚至准确的预测可能随着时间的推移而过时。由于不可能在培训时间发现所有这些失败,因此不可能在培训时间发现所有这些失败,使这些模型的开发者和终端用户能够纠正不准确的产出,而使模型保持原样,这是可取的。然而,大型神经网络所学的演示的分布式黑箱性质使得难以产生这种有针对性的编辑。如果只用单一的有问题的投入和新的预期产出来显示,微调方法往往会过度适用;其他编辑算法要么计算不可行,要么在应用非常大的模型时效果不明显。为了便于在规模上进行容易的后热编辑,我们建议模型的模型网型(MEND)和终端编辑网(MEND)能够使用单一所需的投入-输出配对来快速进行本地编辑。 MEND学会只学会改变通过标准微调获得的梯度模型取得的梯度,使用10亿分级的梯度的梯度的梯度,甚至使这一变形模型的参数化。MEND在10亿个经过训练的模型上进行快速的GPL的测试。