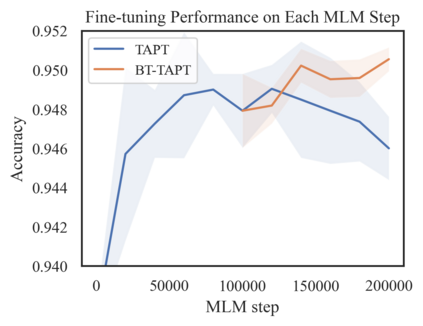
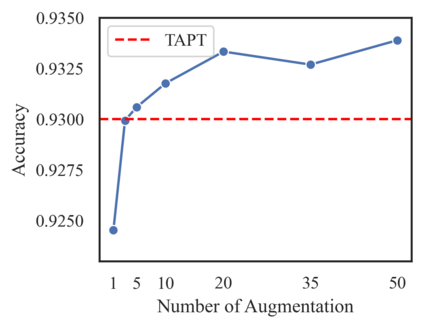
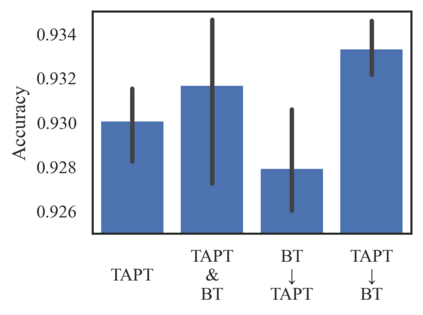
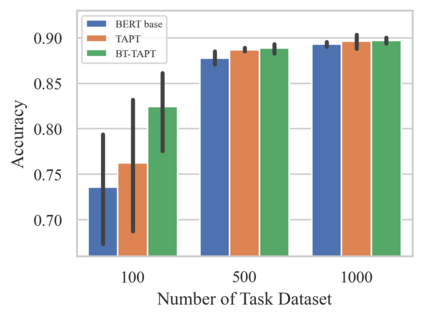
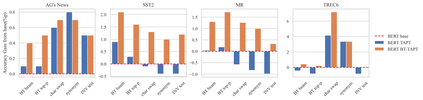
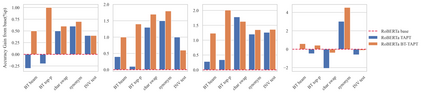
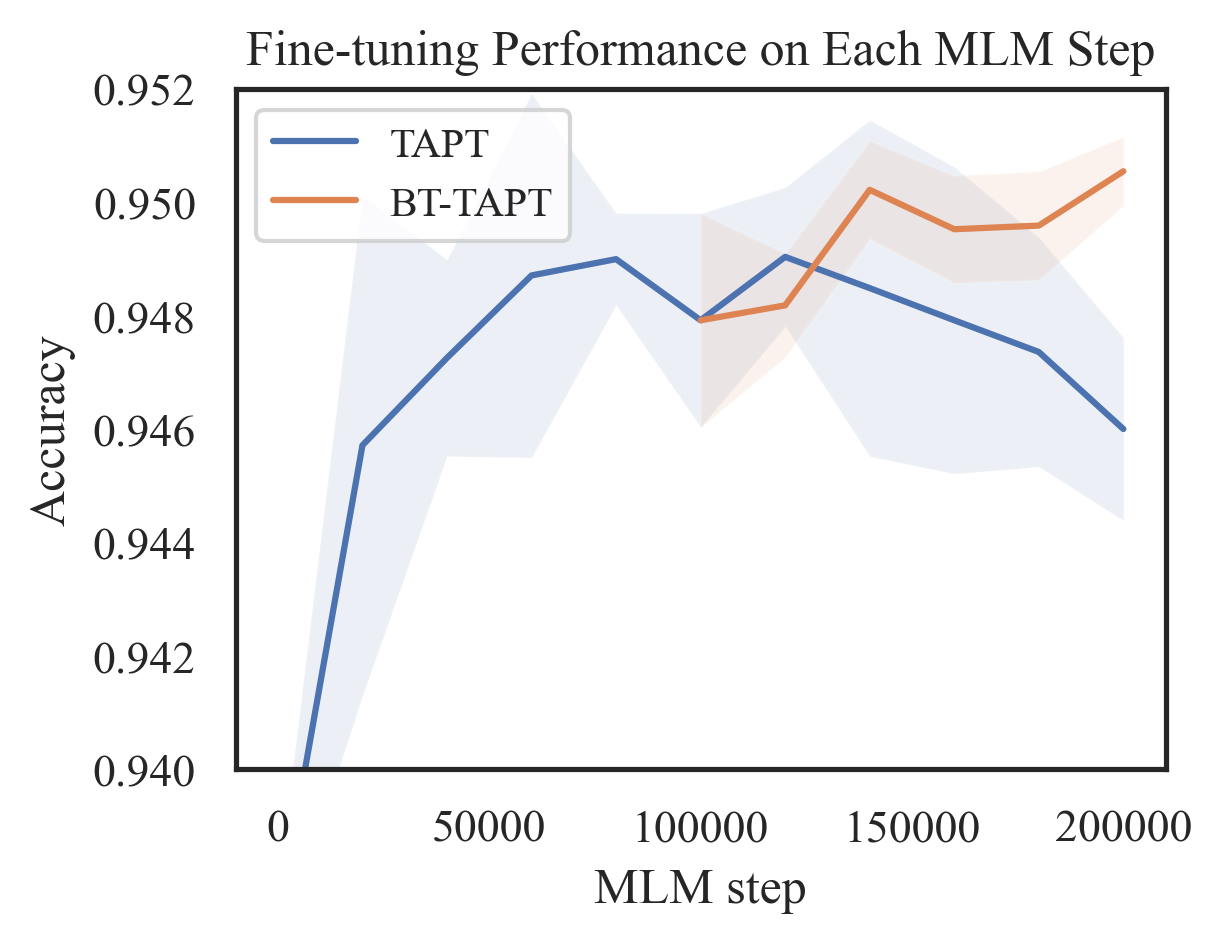
Language models (LMs) pretrained on a large text corpus and fine-tuned on a downstream text corpus and fine-tuned on a downstream task becomes a de facto training strategy for several natural language processing (NLP) tasks. Recently, an adaptive pretraining method retraining the pretrained language model with task-relevant data has shown significant performance improvements. However, current adaptive pretraining methods suffer from underfitting on the task distribution owing to a relatively small amount of data to re-pretrain the LM. To completely use the concept of adaptive pretraining, we propose a back-translated task-adaptive pretraining (BT-TAPT) method that increases the amount of task-specific data for LM re-pretraining by augmenting the task data using back-translation to generalize the LM to the target task domain. The experimental results show that the proposed BT-TAPT yields improved classification accuracy on both low- and high-resource data and better robustness to noise than the conventional adaptive pretraining method.
翻译:语言模型(LMS)在大型文本堆中预先培训,在下游文本堆中经过微调,在下游任务上经过微调,成为若干自然语言处理任务的实际培训战略。最近,对预先培训的语言模型进行适应性培训前方法的再培训,加上与任务相关的数据,显示出了显著的性能改进。然而,由于用于再培训LM的数据数量相对较少,目前的适应性培训前方法在任务分配方面出现不足。 为了完全使用适应性预备培训的概念,我们提议了一种回译任务适应性培训前培训(BT-TAPT)方法,通过使用回译将LM(LM)概括到目标任务领域的任务数据增加LM(任务数据)的具体任务数据数量。实验结果表明,拟议的BT-TAPT在低资源和高资源数据方面提高了分类的准确性,而且比常规的适应性培训前方法更可靠。