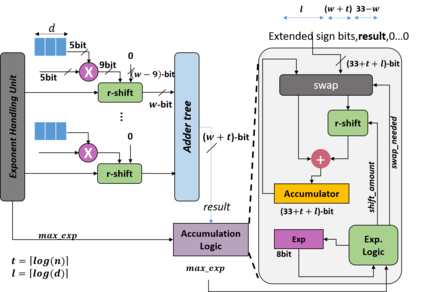
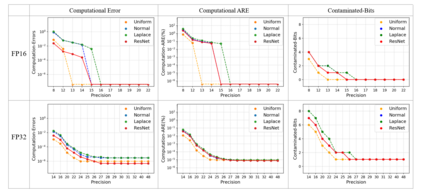
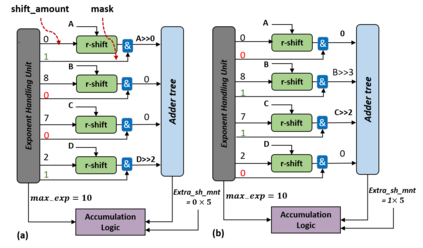
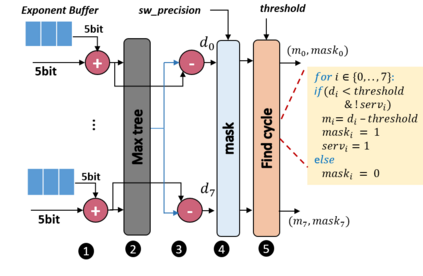
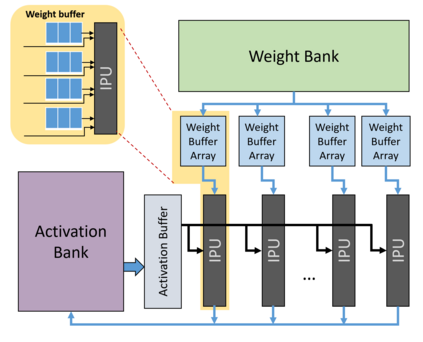
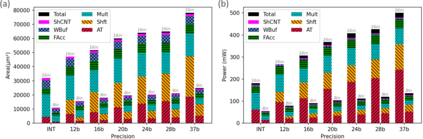
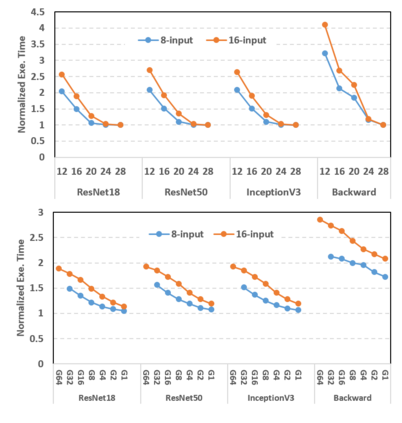
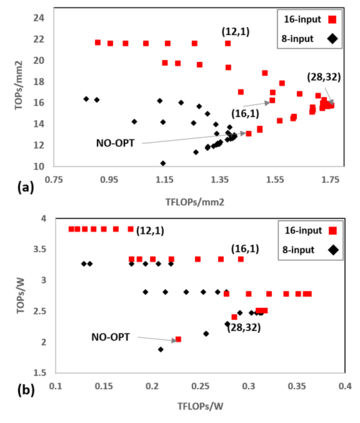
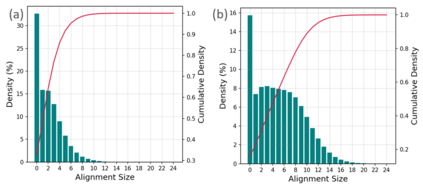
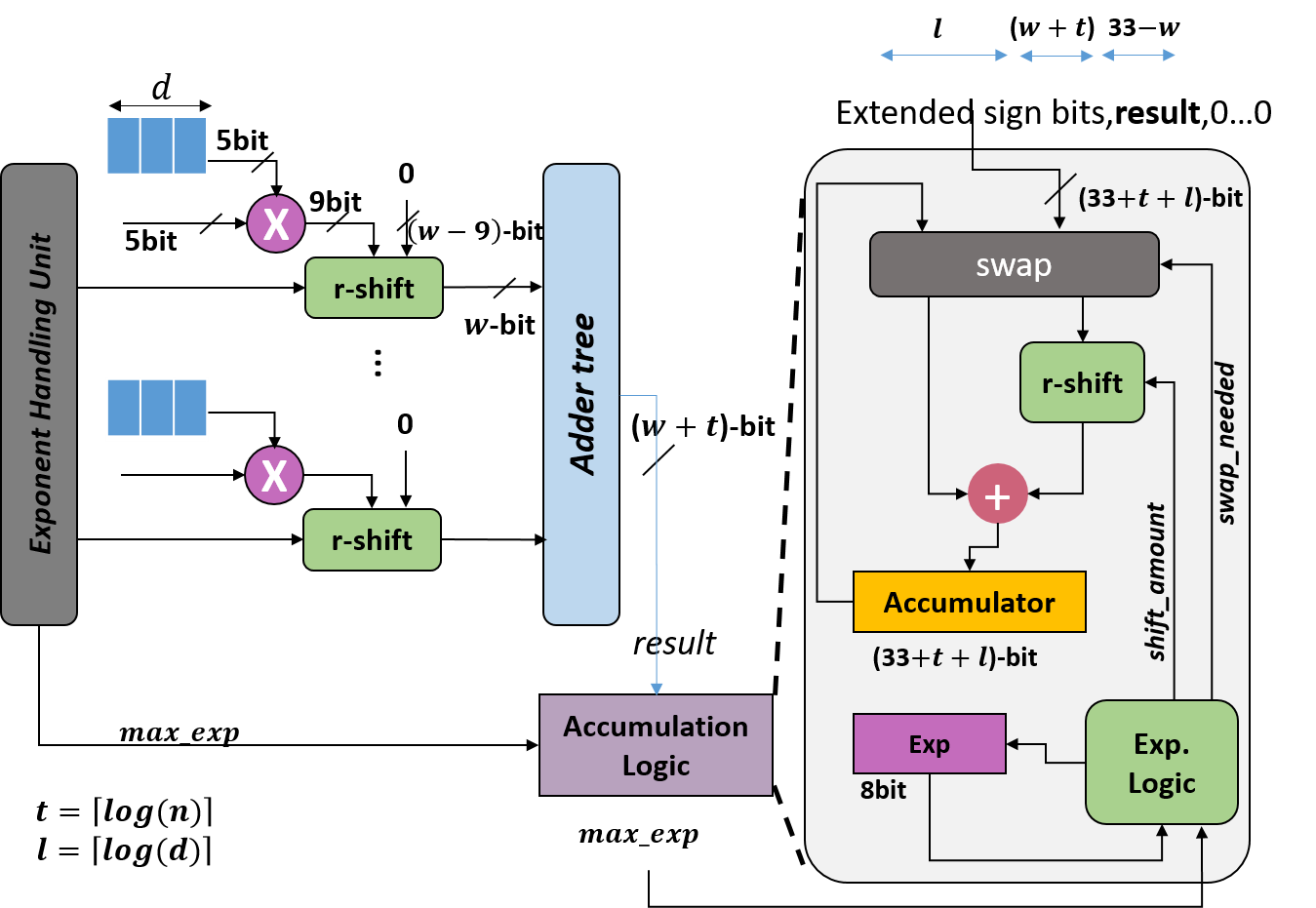
In this paper, we propose a mixed-precision convolution unit architecture which supports different integer and floating point (FP) precisions. The proposed architecture is based on low-bit inner product units and realizes higher precision based on temporal decomposition. We illustrate how to integrate FP computations on integer-based architecture and evaluate overheads incurred by FP arithmetic support. We argue that alignment and addition overhead for FP inner product can be significant since the maximum exponent difference could be up to 58 bits, which results into a large alignment logic. To address this issue, we illustrate empirically that no more than 26-bitproduct bits are required and up to 8-bit of alignment is sufficient in most inference cases. We present novel optimizations based on the above observations to reduce the FP arithmetic hardware overheads. Our empirical results, based on simulation and hardware implementation, show significant reduction in FP16 overhead. Over typical mixed precision implementation, the proposed architecture achieves area improvements of up to 25% in TFLOPS/mm2and up to 46% in TOPS/mm2with power efficiency improvements of up to 40% in TFLOPS/Wand up to 63% in TOPS/W.
翻译:在本文中,我们提出一个混合精密卷动单元结构,支持不同的整数和浮动点(FP)精确度。拟议结构以低位内值产品单位为基础,根据时间分解实现更高的精确度。我们说明如何整合基于整数的建筑结构的FP计算,并评估FP计算支持产生的间接费用。我们争辩说,FP内产物的最大指数差异可能高达58位元,从而形成一个很大的校正逻辑。为了解决这一问题,我们从经验上说明,不需要超过26位比特产品位,在多数推断情况下,最多达8位比特。我们根据上述观察提出了新的优化,以减少FP计算硬件的硬件间接费用。我们根据模拟和硬件实施的经验结果显示,FP16的间接费用显著减少。在典型的混合精确实施中,拟议的结构在TFLLOPS/mm2和TOPS/mm2中实现了高达25%的改进,在TFLOPS/W和TPS/63W中提高了高达40%的功率,在TFLOPS/W中达到了46%。