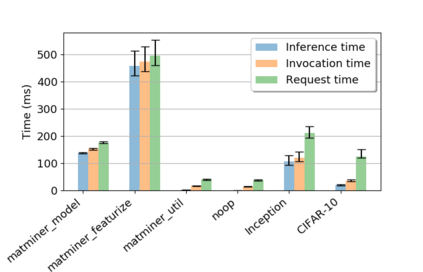
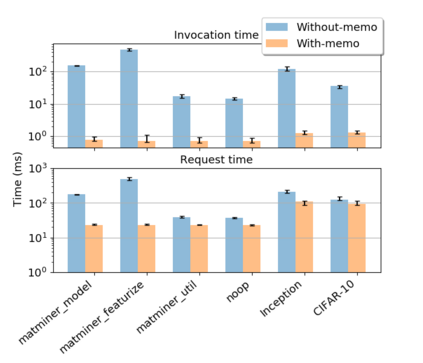
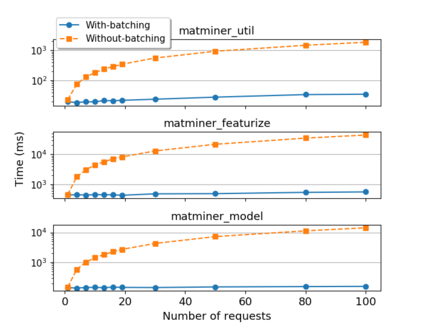
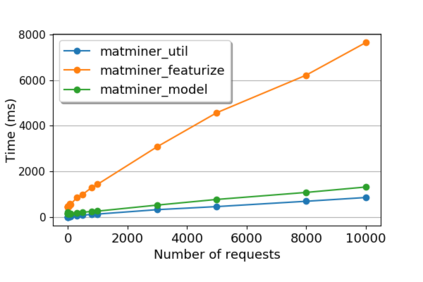
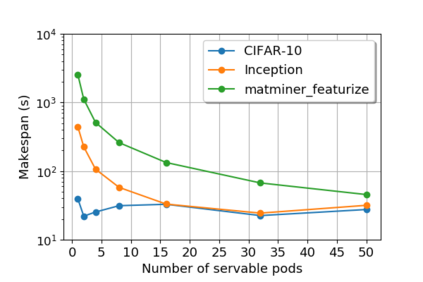
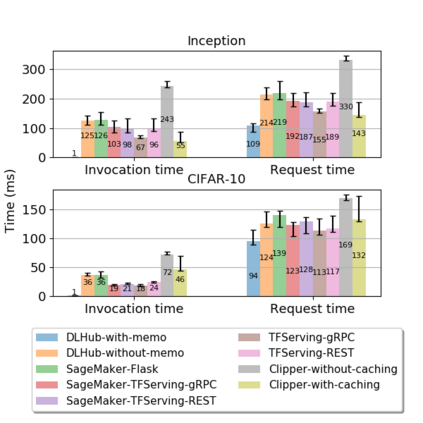
While the Machine Learning (ML) landscape is evolving rapidly, there has been a relative lag in the development of the "learning systems" needed to enable broad adoption. Furthermore, few such systems are designed to support the specialized requirements of scientific ML. Here we present the Data and Learning Hub for science (DLHub), a multi-tenant system that provides both model repository and serving capabilities with a focus on science applications. DLHub addresses two significant shortcomings in current systems. First, its selfservice model repository allows users to share, publish, verify, reproduce, and reuse models, and addresses concerns related to model reproducibility by packaging and distributing models and all constituent components. Second, it implements scalable and low-latency serving capabilities that can leverage parallel and distributed computing resources to democratize access to published models through a simple web interface. Unlike other model serving frameworks, DLHub can store and serve any Python 3-compatible model or processing function, plus multiple-function pipelines. We show that relative to other model serving systems including TensorFlow Serving, SageMaker, and Clipper, DLHub provides greater capabilities, comparable performance without memoization and batching, and significantly better performance when the latter two techniques can be employed. We also describe early uses of DLHub for scientific applications.
翻译:虽然机器学习(ML)格局正在迅速演变,但在开发必要的“学习系统”以便广泛采用方面却相对滞后,此外,这类系统也很少用来支持科学ML的专门要求。这里我们展示了科学数据和学习枢纽(DLHub),这是一个提供模式储存和服务能力的多维系统,以科学应用为重点。DLHub处理当前系统中两个重大缺陷。首先,其自助服务模式库允许用户通过包装和分发模型及所有组成部分,分享、公布、核查、复制和再利用模型,并解决与模型再现有关的问题。第二,它实施可扩展和低延迟的服务能力,通过简单的网络界面,利用平行和分散的计算机资源,使已出版模型的进入民主化。与其他模式服务框架不同的是,DLub可以储存和提供任何比对立的3模型或处理功能,加上多重功能管道。我们显示,与其他模型服务系统相比,通过包装和分发模型以及所有组成部分,我们可以通过包装和分发模型和克里普(Clipper),DLHub等系统实施可扩缩的可操作能力,在不大量使用科学应用的早期和后,我们也能提供较强的成绩。