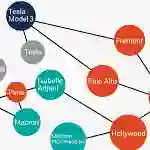
Answering complex questions over knowledge bases (KB-QA) faces huge input data with billions of facts, involving millions of entities and thousands of predicates. For efficiency, QA systems first reduce the answer search space by identifying a set of facts that is likely to contain all answers and relevant cues. The most common technique for doing this is to apply named entity disambiguation (NED) systems to the question, and retrieve KB facts for the disambiguated entities. This work presents CLOCQ, an efficient method that prunes irrelevant parts of the search space using KB-aware signals. CLOCQ uses a top-k query processor over score-ordered lists of KB items that combine signals about lexical matching, relevance to the question, coherence among candidate items, and connectivity in the KB graph. Experiments with two recent QA benchmarks for complex questions demonstrate the superiority of CLOCQ over state-of-the-art baselines with respect to answer presence, size of the search space, and runtimes.
翻译:回答有关知识基础(KB-QA)的复杂问题时,面临数十亿个事实的大量输入数据,涉及数百万实体和数千个上游。为了效率,QA系统首先通过确定一套可能包含所有答案和相关线索的事实来减少答题搜索空间。最常用的方法是将名称实体脱钩(NED)系统应用于问题,并为脱节实体检索KB事实。这项工作展示了CLOCQ,这是利用KB-aware信号处理搜索空间中无关部分的一种有效方法。CLOCQ使用一个顶级查询处理器,而不是按分级排列的KB项目清单,该清单将有关词汇匹配、与问题的相关性、候选项目的一致性和KB图中的连接性等信号结合起来。与最近两个关于复杂问题的QA基准的实验表明,CLOCQ在回答存在、搜索空间大小和运行时间方面优于最先进的基准。