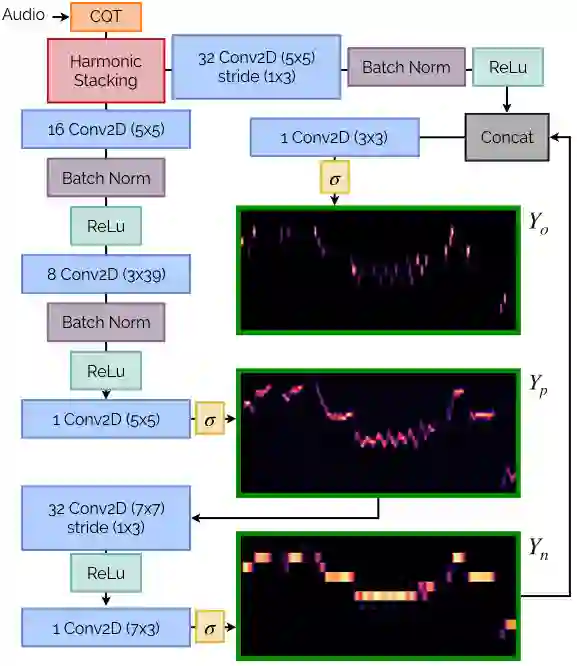
Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise $f_0$ values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems.
翻译:自动音乐追踪(AMT)已被公认为具有广泛应用范围的关键赋能技术(AMT) 。 鉴于任务的复杂性,对侧重于特定环境的系统来说,报告的最佳结果通常都是最佳的,例如,特定仪器的系统在仪器识别方法方面往往能产生更好的效果。同样,仅仅根据框架估计值(f_0美元)和忽略较难的备注事件检测,就可以获得更高的准确性。尽管这种专门系统非常精确,但往往无法在现实世界中部署。储存和网络限制禁止使用多种专门模型,而记忆和运行时间限制则限制了这些模型的复杂性。在本文件中,我们建议为乐器笔录建立一个轻量的神经网络,支持多功能产出,并概括广泛的工具(包括声音)。我们的模型经过培训,可以共同预测以框架判断的起始、多功能和笔记的启动。我们实验性地表明,这种多功能结构提高了由此产生的框架级注释的准确性。尽管其简单性,但基准结果显示我们的系统注释估计比可比较的基线要好得多。我们提出的是,其框架级的精确性工具只能进一步调查那些低的系统。