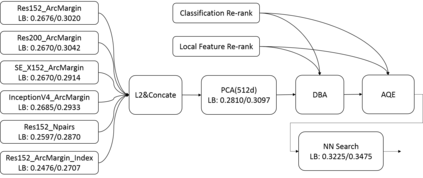
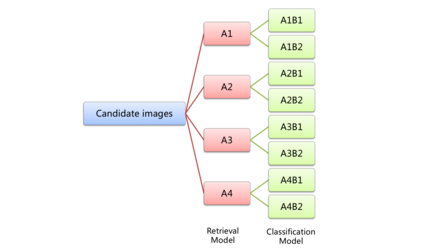
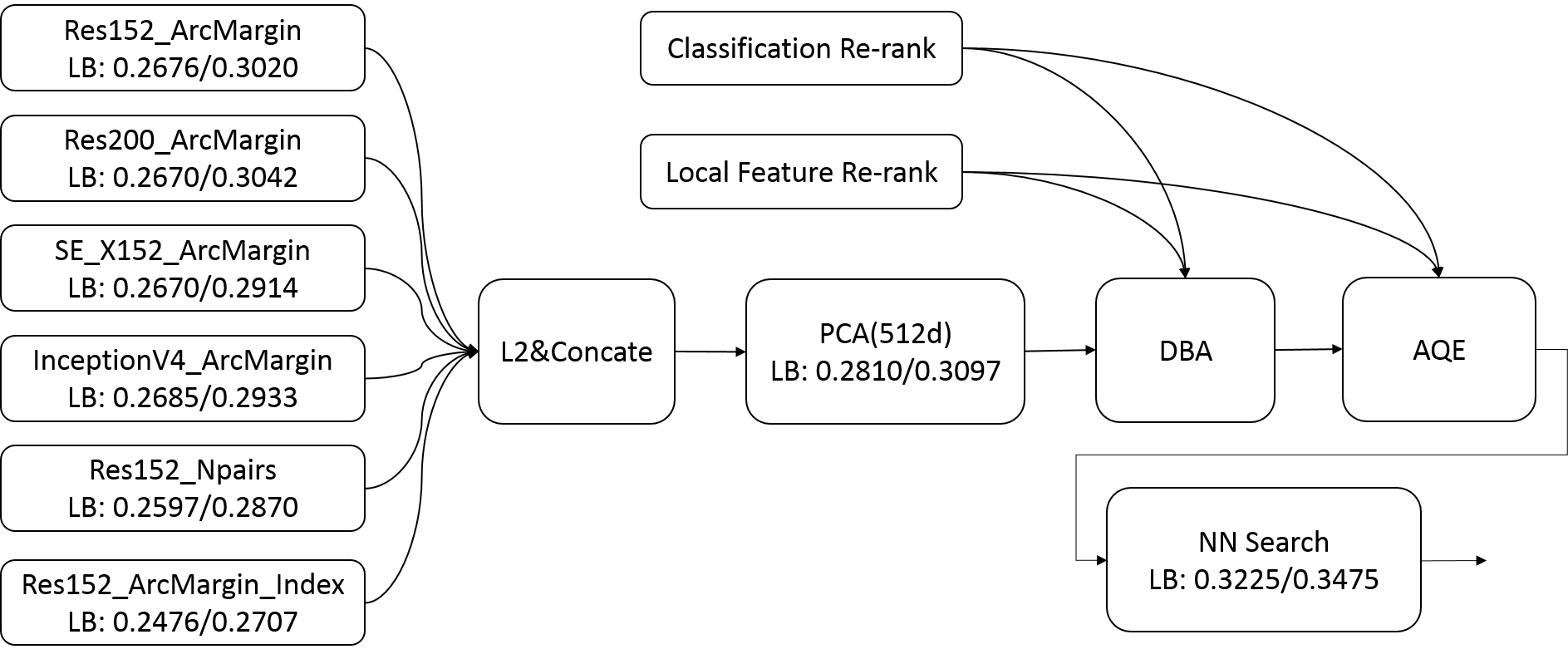
We present a retrieval based system for landmark retrieval and recognition challenge.There are five parts in retrieval competition system, including feature extraction and matching to get candidates queue; database augmentation and query extension searching; reranking from recognition results and local feature matching. In recognition challenge including: landmark and non-landmark recognition, multiple recognition results voting and reranking using combination of recognition and retrieval results. All of models trained and predicted by PaddlePaddle framework. Using our method, we achieved 2nd place in the Google Landmark Recognition 2019 and 2nd place in the Google Landmark Retrieval 2019 on kaggle. The source code is available at here.
翻译:我们提出了一个基于检索的系统,用于里程碑的检索和识别挑战。 在检索竞争系统中,有五个部分,包括地物提取和匹配以获得候选队列;数据库扩增和查询扩展搜索;从识别结果和本地特征匹配中重新排序。在识别挑战中,包括:里程碑和非地标识别,多重识别结果表决,以及利用确认和检索结果的组合进行排序。所有模型都经过编织PaddlePadddle框架的培训和预测。我们使用我们的方法,在谷歌Landmark识别2019和谷歌Landmark Retrieval 2019年谷歌Laggle排名第二位中取得了第二位。源代码在这里可用。